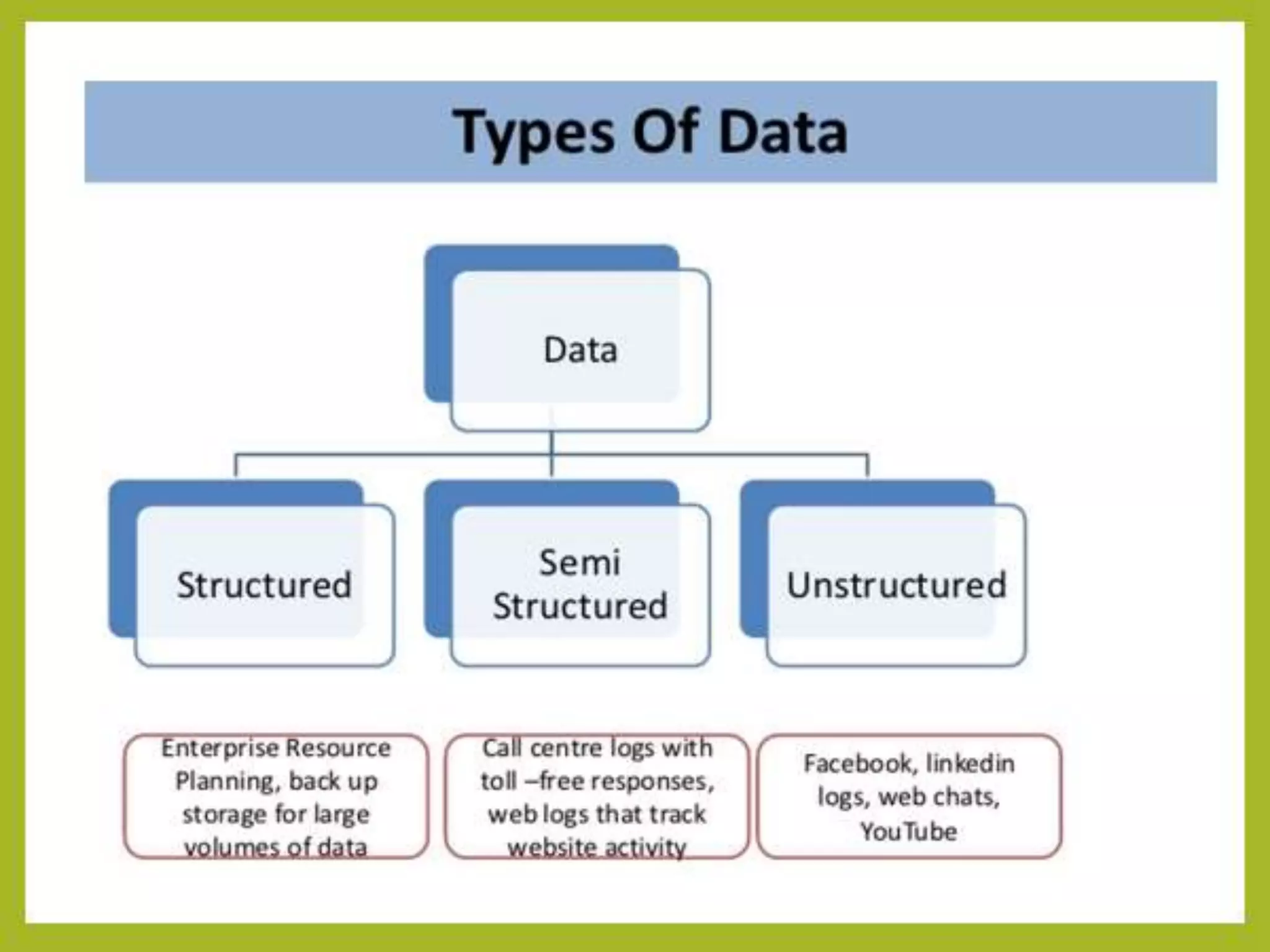
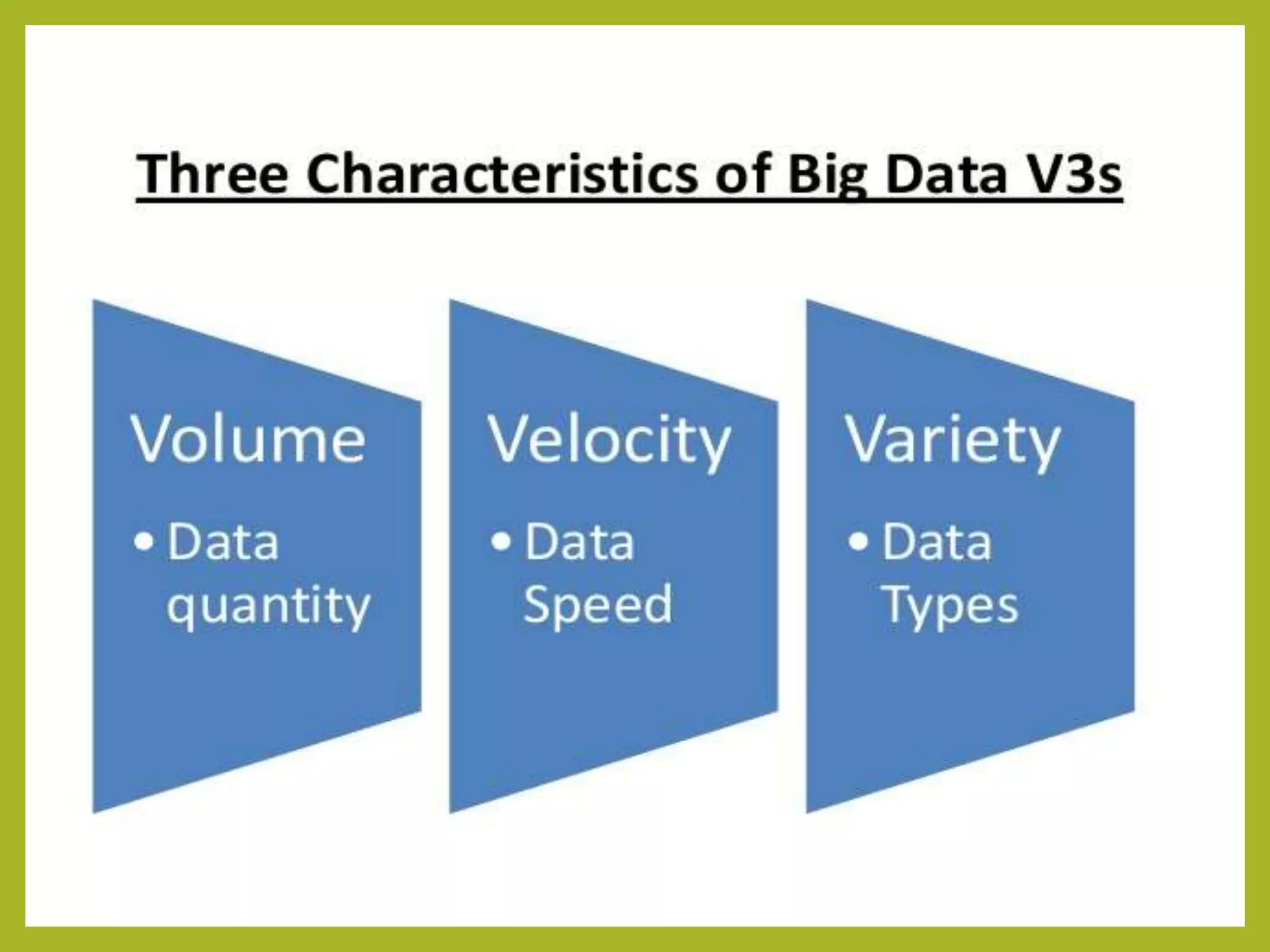
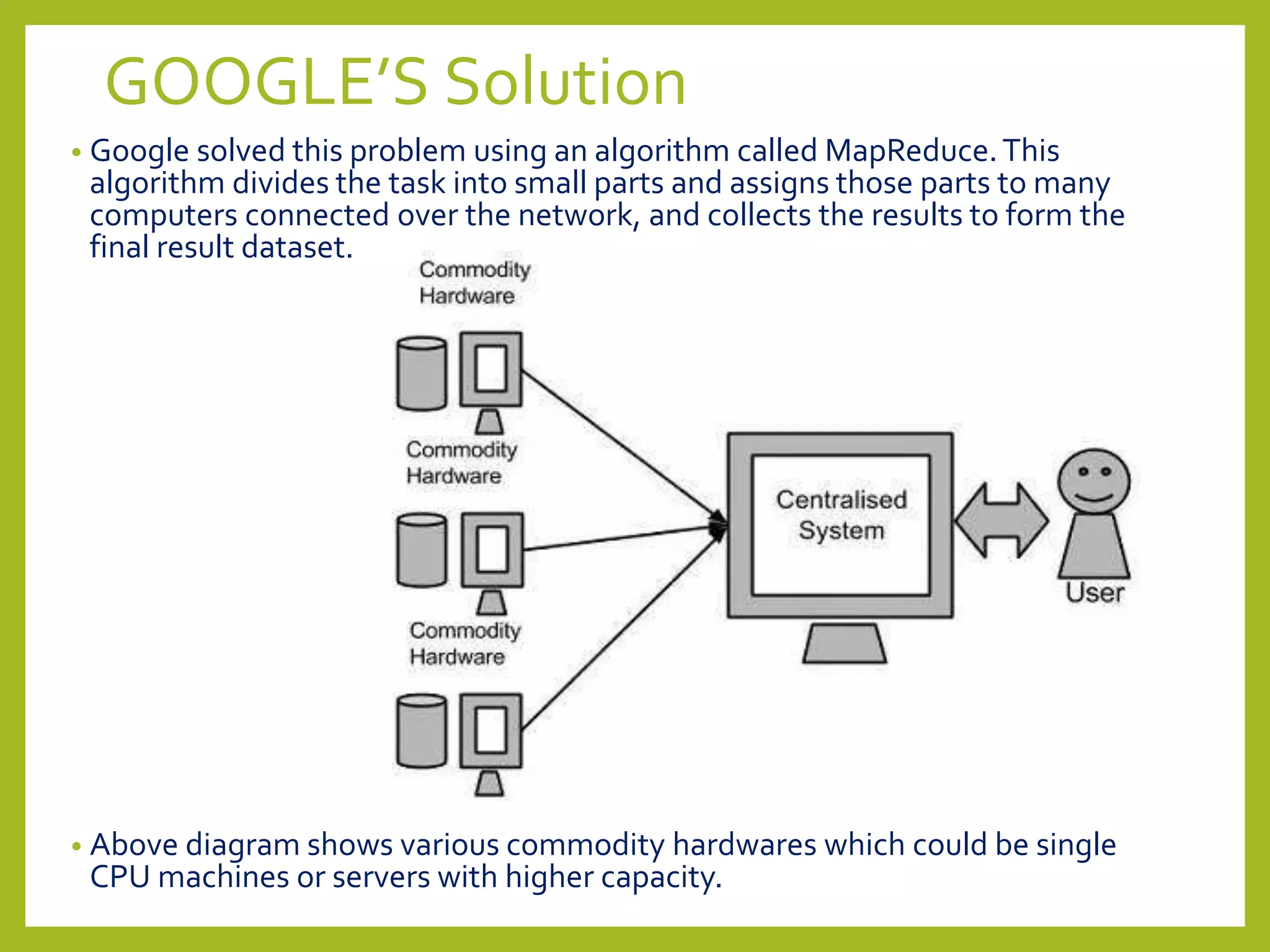
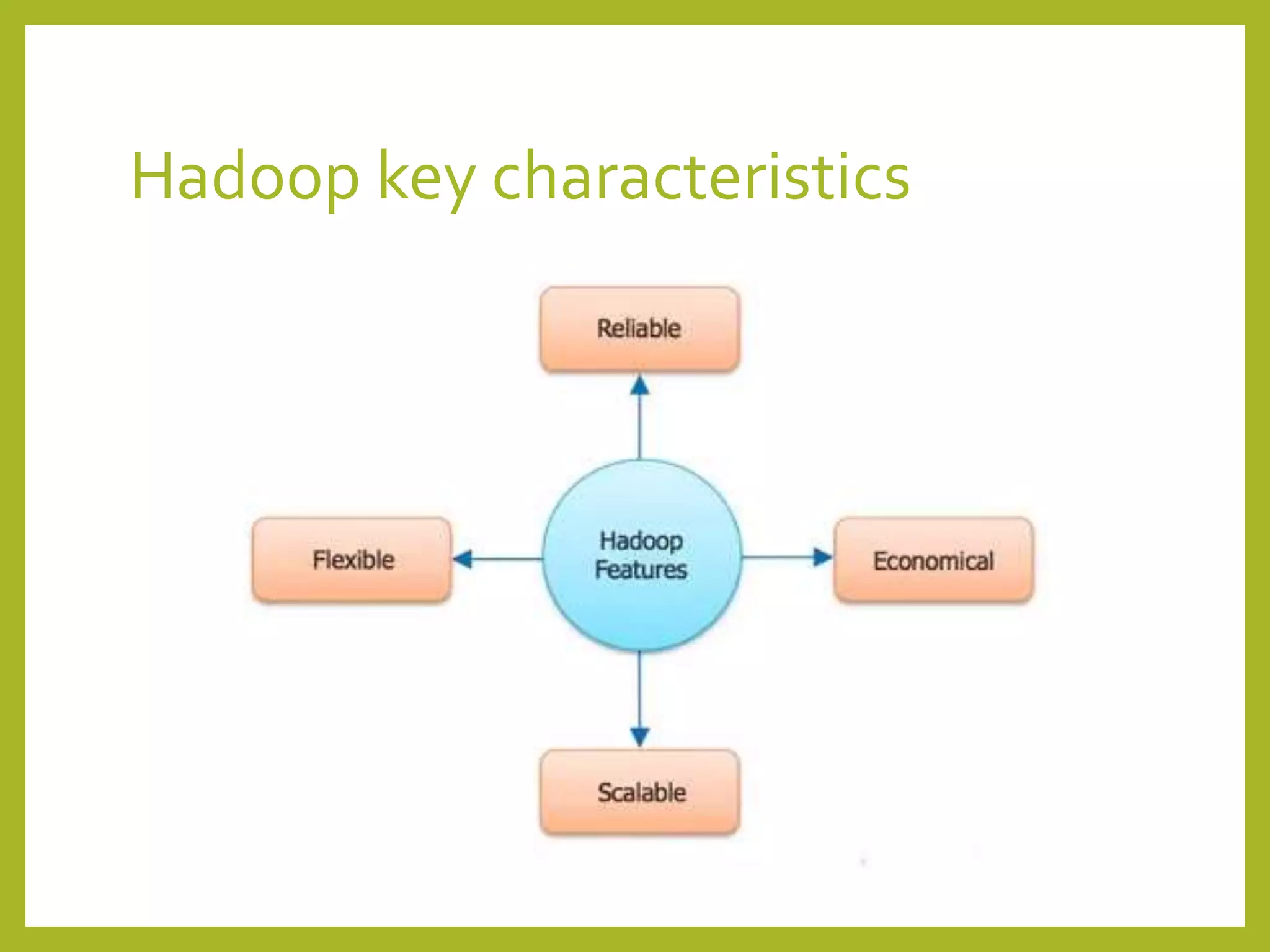
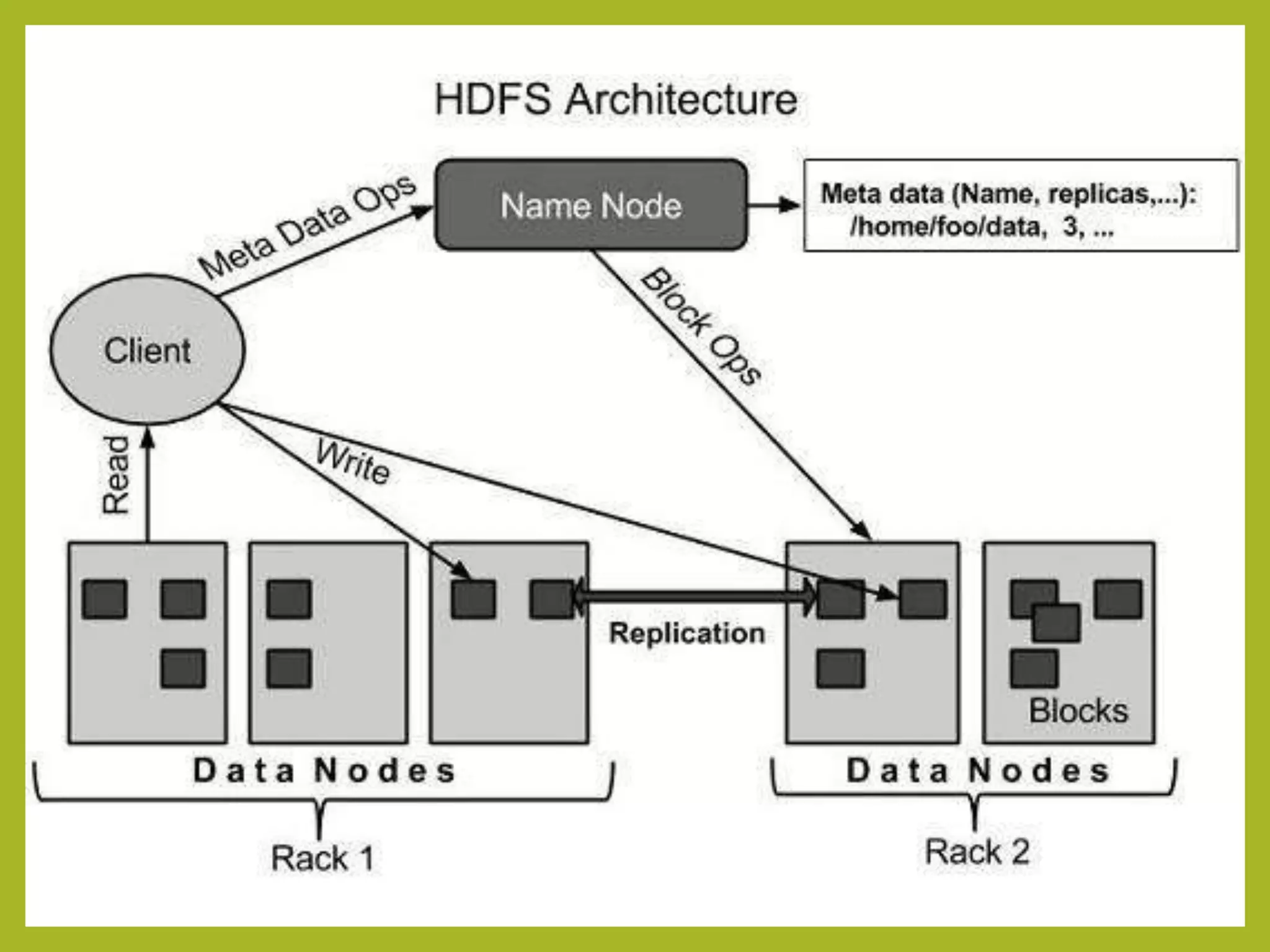
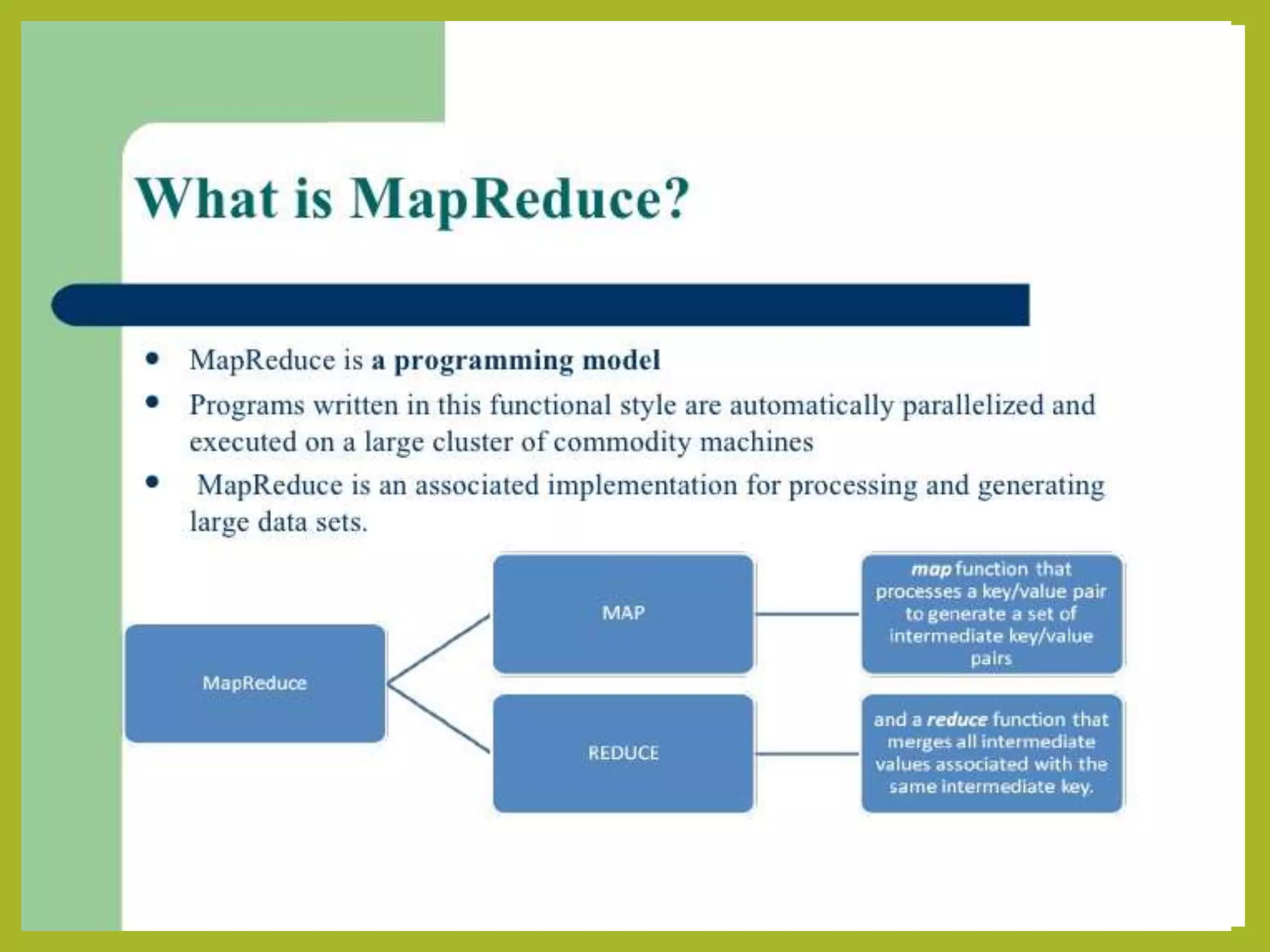
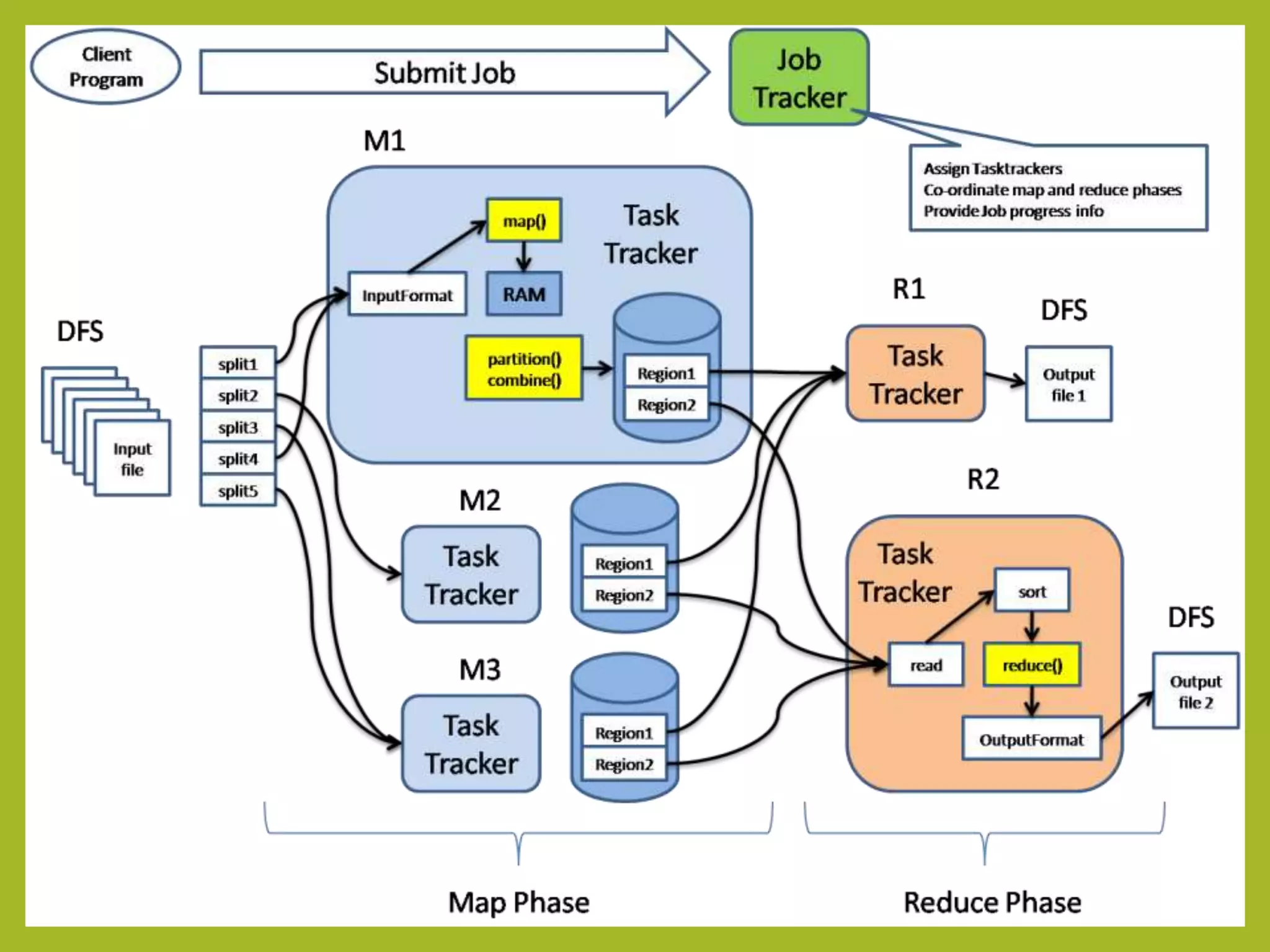
Big data and Hadoop are frameworks for processing and storing large datasets. Hadoop uses HDFS for distributed storage and MapReduce for distributed processing. HDFS stores large files across multiple machines for redundancy and parallel access. MapReduce divides jobs into map and reduce tasks that run in parallel across a cluster. Hadoop provides scalable and fault-tolerant solutions to problems like processing terabytes of data from jet engines or scaling to Google's data processing needs.
































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












