Downloaded 237 times



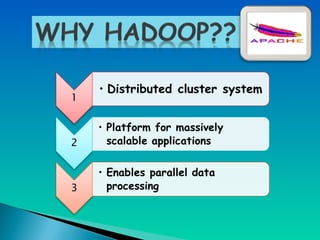


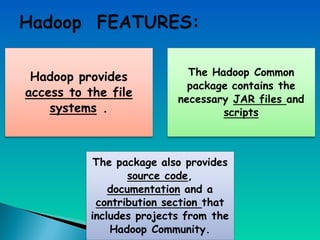
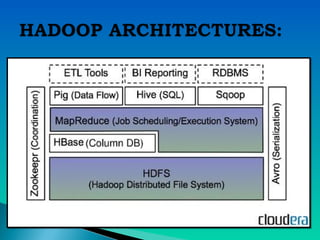


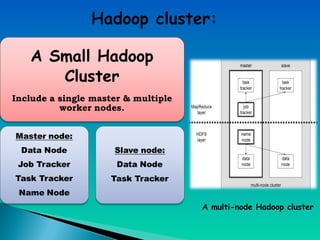
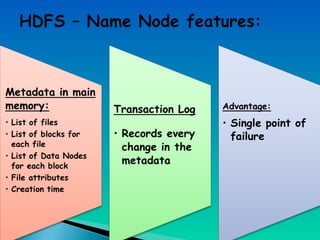
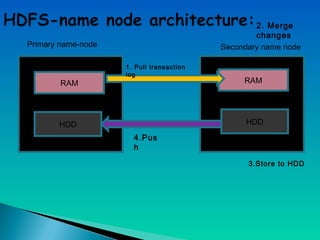
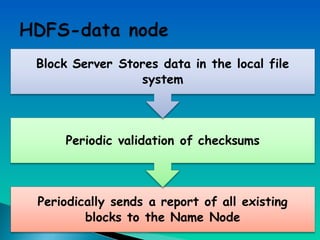




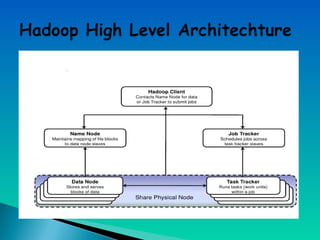
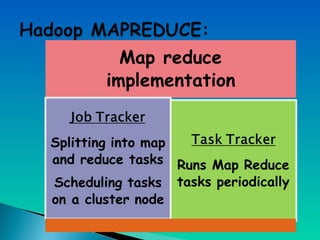
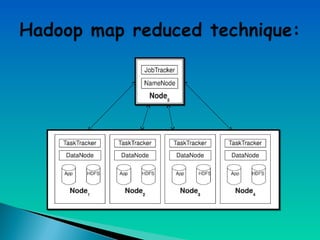






A document describes a multi-node Hadoop cluster used for processing large amounts of data. The cluster includes multiple nodes with RAM and HDD storage. It uses a primary and secondary name node to pull transaction logs, merge changes, and store data to HDD. Hadoop provides a cost effective and reliable solution for processing large datasets across standard servers in a parallel and scalable way.














































