Downloaded 131 times














![MAPREDUCE
Output Mapper
(‘Galatasaray’, 1), (‘sampiyon’, 1), (‘olur’, 1), (‘beşiktas’, 1),
(‘sampiyon, 1), (‘olur’, 1), (‘Galatasaray’, 1), (‘Türkiyedir’, 1)
Intermediate Data Reducer’a gönderilen
(‘Galatasaray’,[1,1])
(‘sampiyon’,[1,1])
(‘olur’,[1])
(‘beşiktas’,[1])
(‘Türkiyedir’,[1])
Reducer’ın son cıktısı
(‘Galatasaray’,2)
(‘sampiyon’,2)
(‘olur’,1)
(‘beşiktas’,1)
(‘Türkiyedir’,1)](https://image.slidesharecdn.com/bigdata-150509181220-lva1-app6892/85/Bigdata-Nedir-Hadoop-Nedir-MapReduce-Nedir-Big-Data-22-320.jpg)







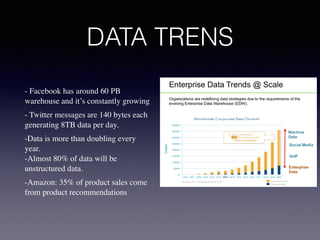
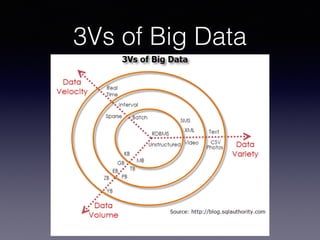
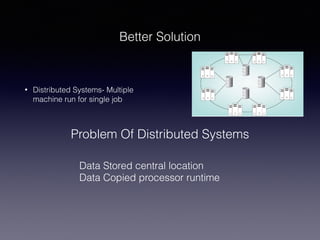
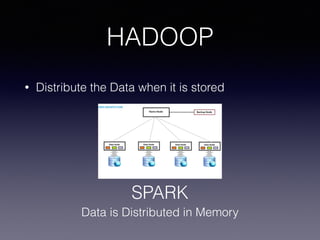
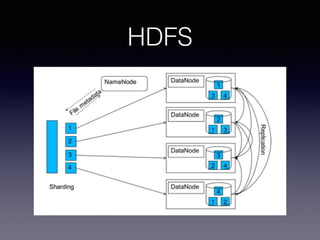
The document discusses big data, emphasizing its increasing volume, velocity, and variety, which challenge traditional data processing systems. It introduces Hadoop as a solution, detailing its components such as HDFS and MapReduce, which facilitate distributed data storage and processing. Additionally, the document outlines various applications of big data across industries and career paths related to Hadoop development and administration.




























































































