Downloaded 135 times













![using Microsoft.Hadoop.MapReduce;
using System.Text.RegularExpressions;
public class TotalHitsForPageMap : MapperBase
{
public override void Map(string inputLine, MapperContext context)
{
context.Log(inputLine);
var parts = Regex.Split(inputLine, "s+");
if (parts.Length != expected) //only take records with all values
{
return;
}
context.EmitKeyValue(parts[pagePos], hit);
}
}
MapReduce Framework (Map)](https://image.slidesharecdn.com/bigdataanalyticsprojects-140510182216-phpapp01/85/Big-Data-Analytics-Projects-Real-World-with-Pentaho-19-320.jpg)




![{
_id : ObjectId("4e2e3f92268cdda473b628f6"),
sourceIDs: {
ABCSystemIDPart1: 8397897,
ABCSystemIDPart2: 2937430,
ABCSystemIDPart3: 932018 }
accountType: “Checking”,
accountOwners: [
{ firstName : ”John",
lastName: “Smith”,
contactMethods: [
{ type: “phone”, subtype: “mobile”, number: 8743927394},
{ type: “mail”, address: “58 3rd St.”, city: …} ]
possibleMatchCriteria: {
govtID: 2938932432, fullName: “johnsmith”, dob: … } },
{ firstName : ”Anne",
maidenName: “Collins”,
lastName: “Smith”, …} ],
openDate: ISODate("2013-02-15 10:00”),
accountFeatures { Overdraft: true, APR: 20, … }
}
General document per customer per account
OR creditCardNumber: 8392384938391293
OR mortgageID: 2374389
OR policyID: 18374923](https://image.slidesharecdn.com/bigdataanalyticsprojects-140510182216-phpapp01/85/Big-Data-Analytics-Projects-Real-World-with-Pentaho-26-320.jpg)


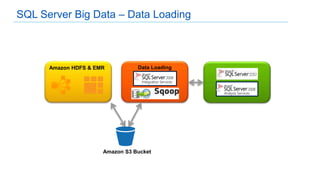

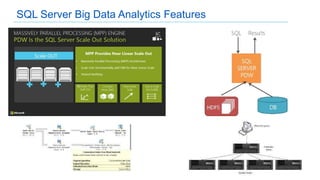

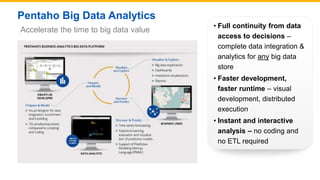



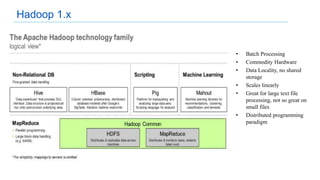
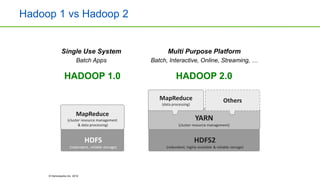
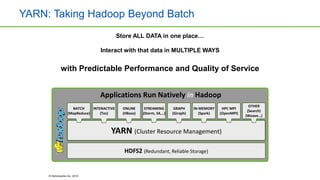
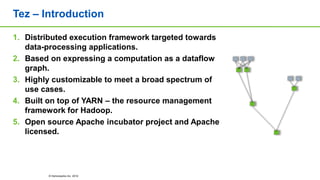
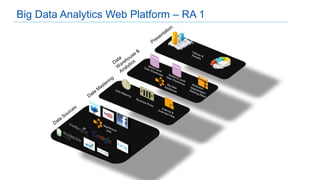
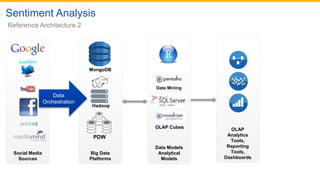
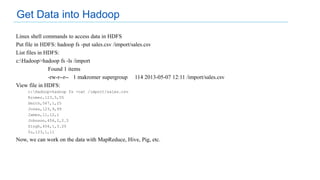
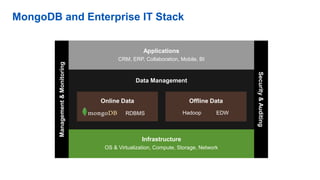
This document discusses big data analytics projects and technologies. It provides an overview of Hadoop, MapReduce, YARN, Spark, SQL Server, and Pentaho tools for big data analytics. Specific scenarios discussed include digital marketing analytics using Hadoop, sentiment analysis using MongoDB and SQL Server, and data refinery using Hadoop, MPP databases, and Pentaho. The document also addresses myths and challenges around big data and provides code examples of MapReduce jobs.





























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)













