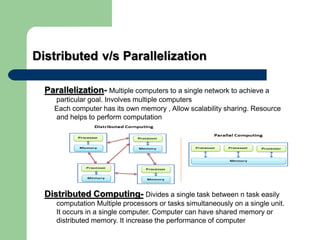
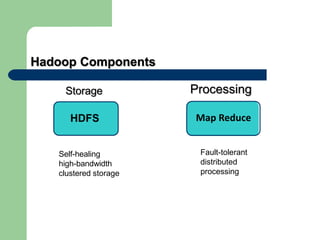
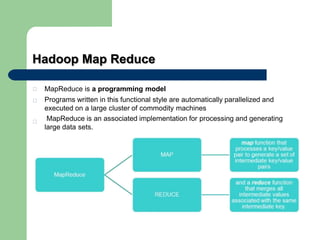
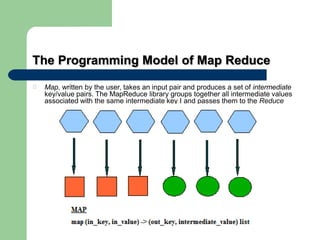
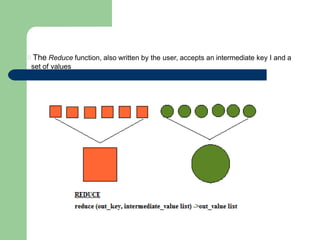
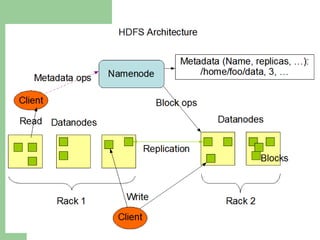
This document discusses big data and Hadoop. It defines big data as large amounts of unstructured data that would be too costly to store and analyze in a traditional database. It then describes how Hadoop provides a solution to this challenge through distributed and parallel processing across clusters of commodity hardware. Key aspects of Hadoop covered include HDFS for reliable storage, MapReduce for distributed computing, and how together they allow scalable analysis of very large datasets. Popular users of Hadoop like Amazon, Yahoo and Facebook are also mentioned.