Download as PDF, PPTX






![Log
Processing
A
Perfect
Fit
• Common
uses
of
logs
• Find
or
count
events
(grep)
grep
“ERROR”
file
grep
-‐c
“ERROR”
file
• Calculate
metrics
(performance
or
user
behavior
analysis)
awk
‘{sums[$1]+=$2;
counts[$1]+=1}
END
{for(k
in
counts)
{print
sums[k]/counts
[k]}}’
• InvesBgate
user
sessions
grep
“USER”
files
…
|
sort
|
less](https://image.slidesharecdn.com/commonanduniqueusecases-110831113310-phpapp01/85/Common-and-unique-use-cases-for-Apache-Hadoop-9-320.jpg)
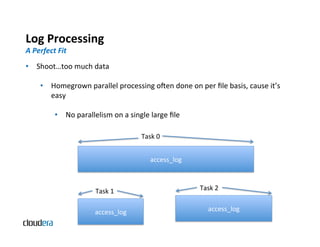
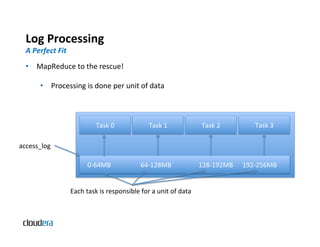
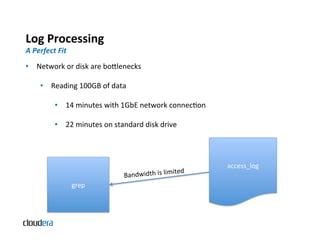
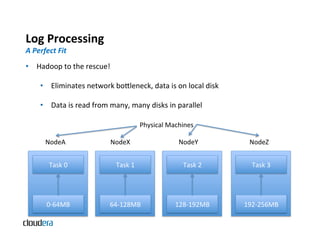




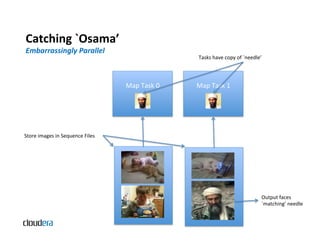


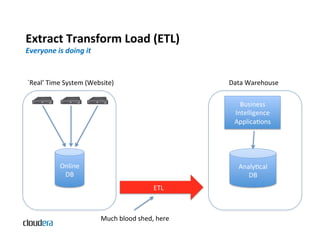
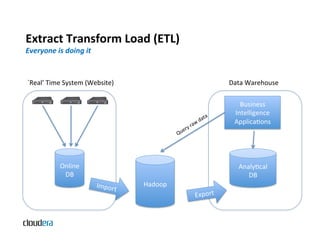
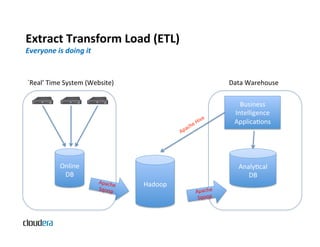














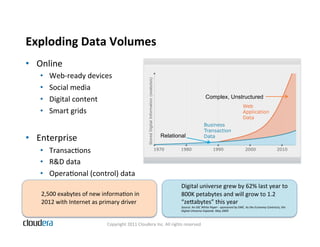
The document provides an overview of Apache Hadoop and common use cases. It describes how Hadoop is well-suited for log processing due to its ability to handle large amounts of data in parallel across commodity hardware. Specifically, it allows processing of log files to be distributed per unit of data, avoiding bottlenecks that can occur when trying to process a single large file sequentially.









































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)












