Download as PDF, PPTX













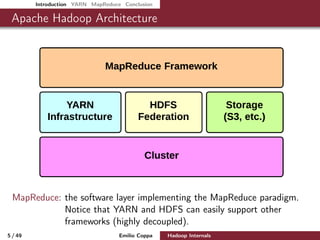

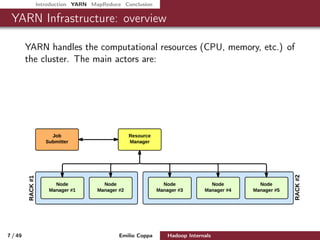





















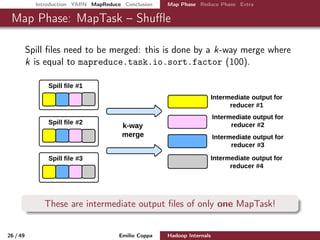
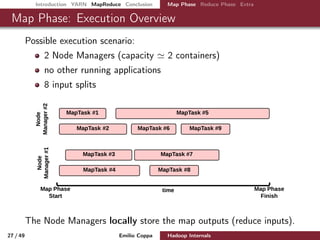
























This document presents an in-depth overview of Apache Hadoop, focusing on its architecture, the YARN resource management framework, and the MapReduce programming model. It details key components, contributors, and the processes involved in job submission, execution, and resource management within a Hadoop cluster. The document serves as a comprehensive guide for understanding Hadoop's design, implementation, and functionalities for processing big data.






























































![[db tech showcase Tokyo 2014] C32: Hadoop最前線 - 開発の現場から by NTT 小沢健史](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014c32ntthadoop-141203014329-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
























