





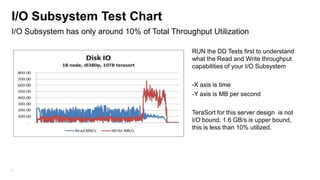
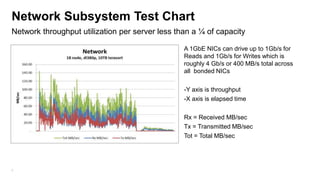
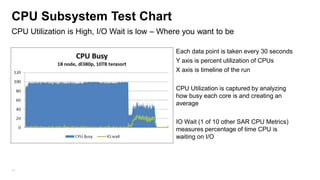
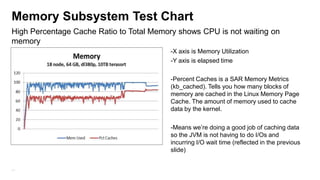
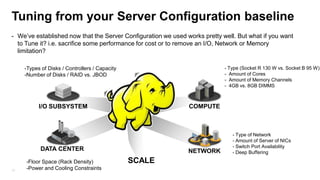


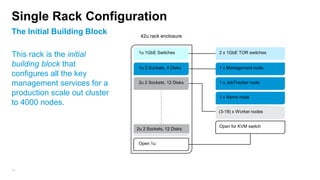
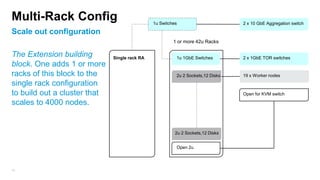






The document details the design, profiling, and performance analysis of Hadoop infrastructure, emphasizing the importance of accurately assessing hardware needs based on application requirements. It outlines a structured approach to instrumenting the cluster and gathering performance data using tools like sar, as well as considerations for tuning system configurations to achieve a balance of cost and performance. The presentation concludes with future directions for Hadoop operations and scaling recommendations.






















































































