






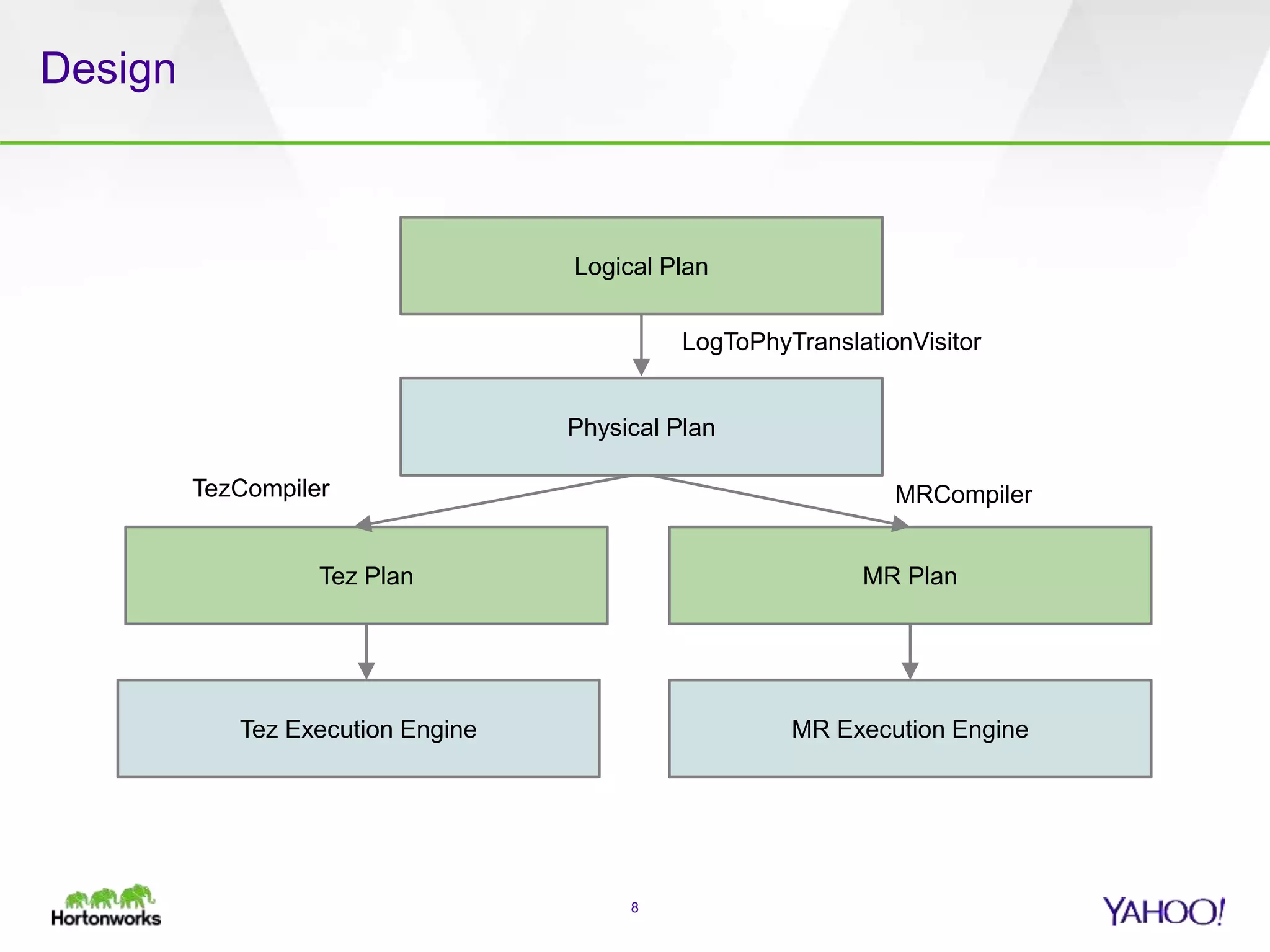
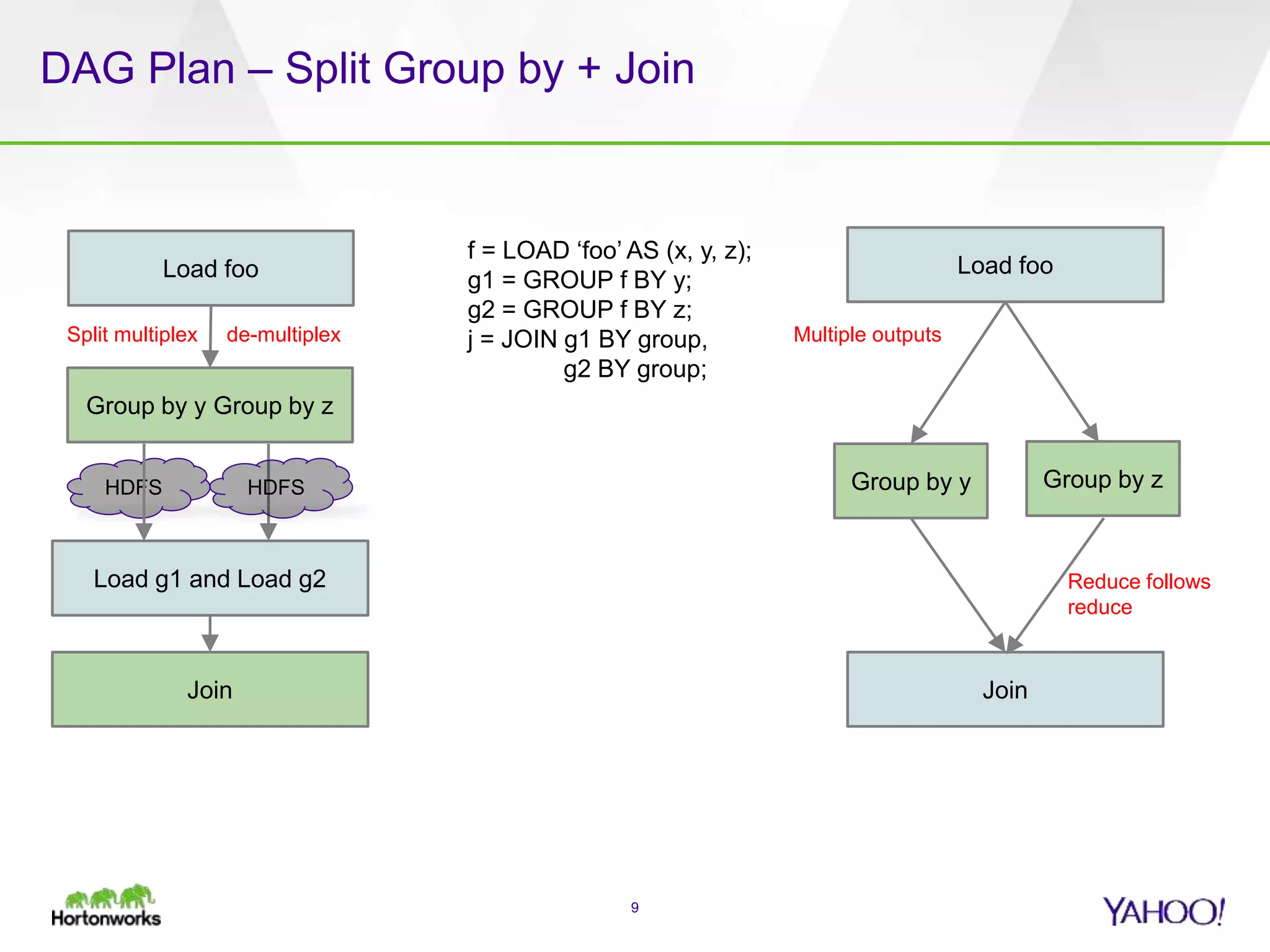
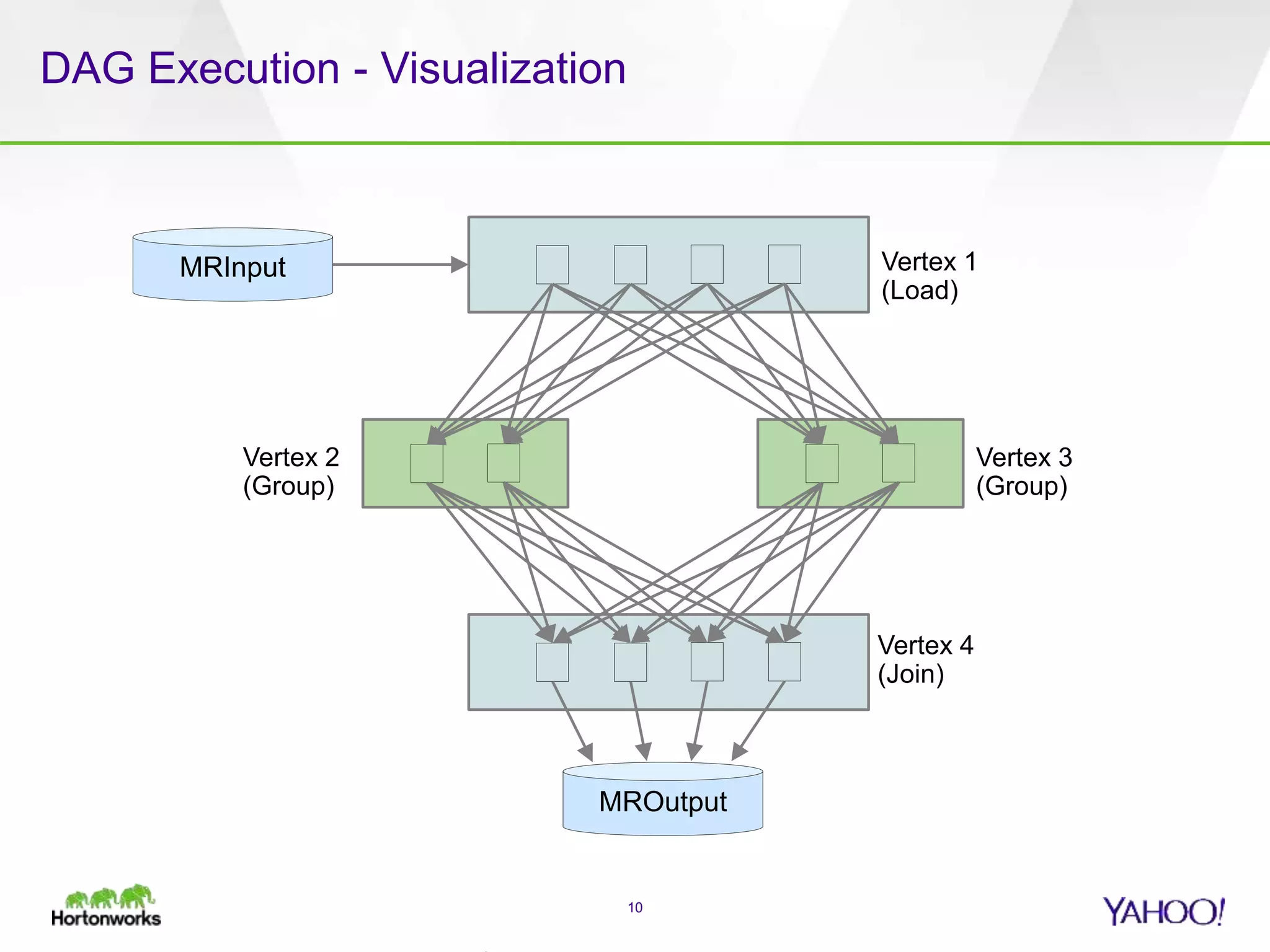
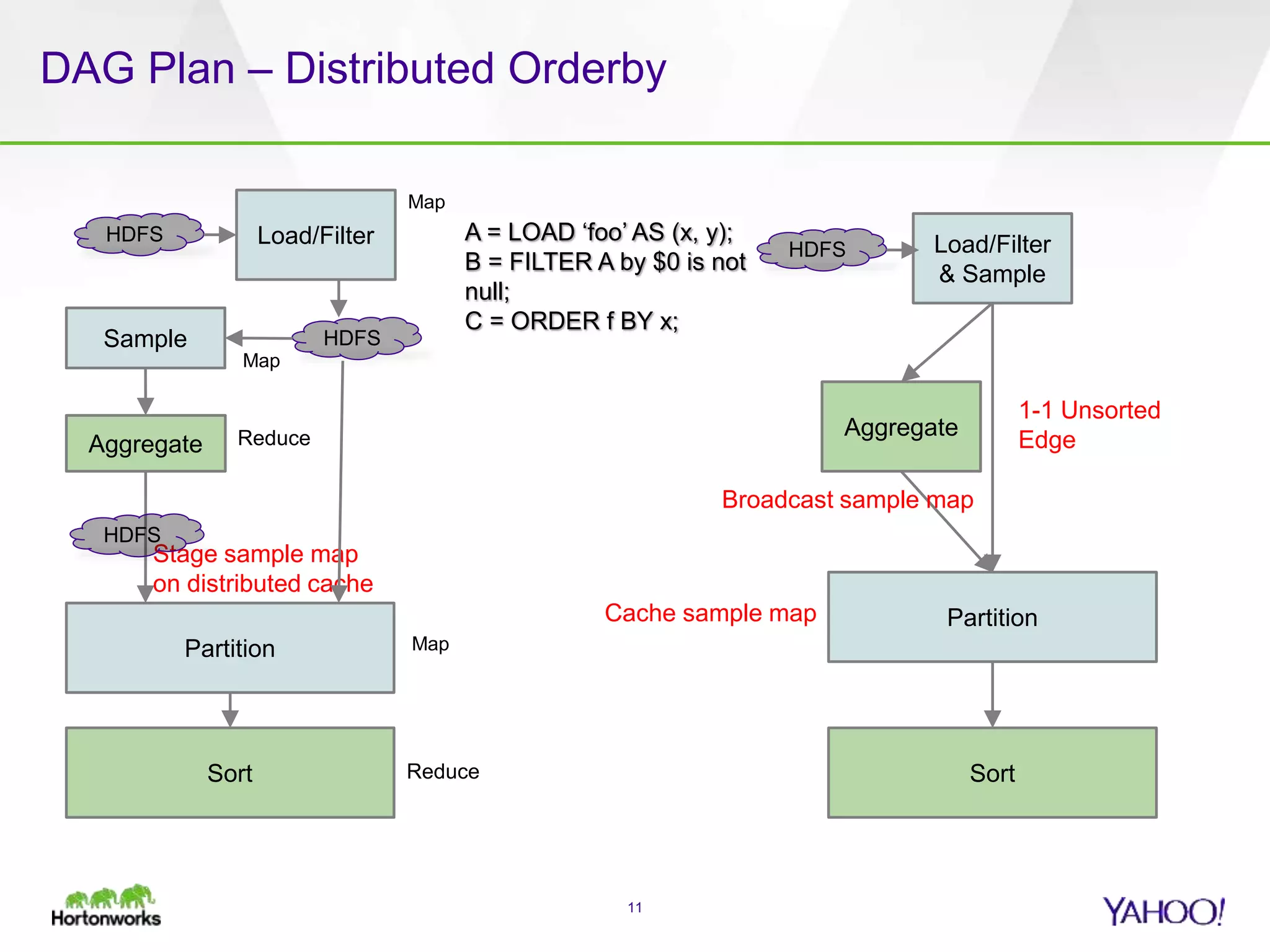



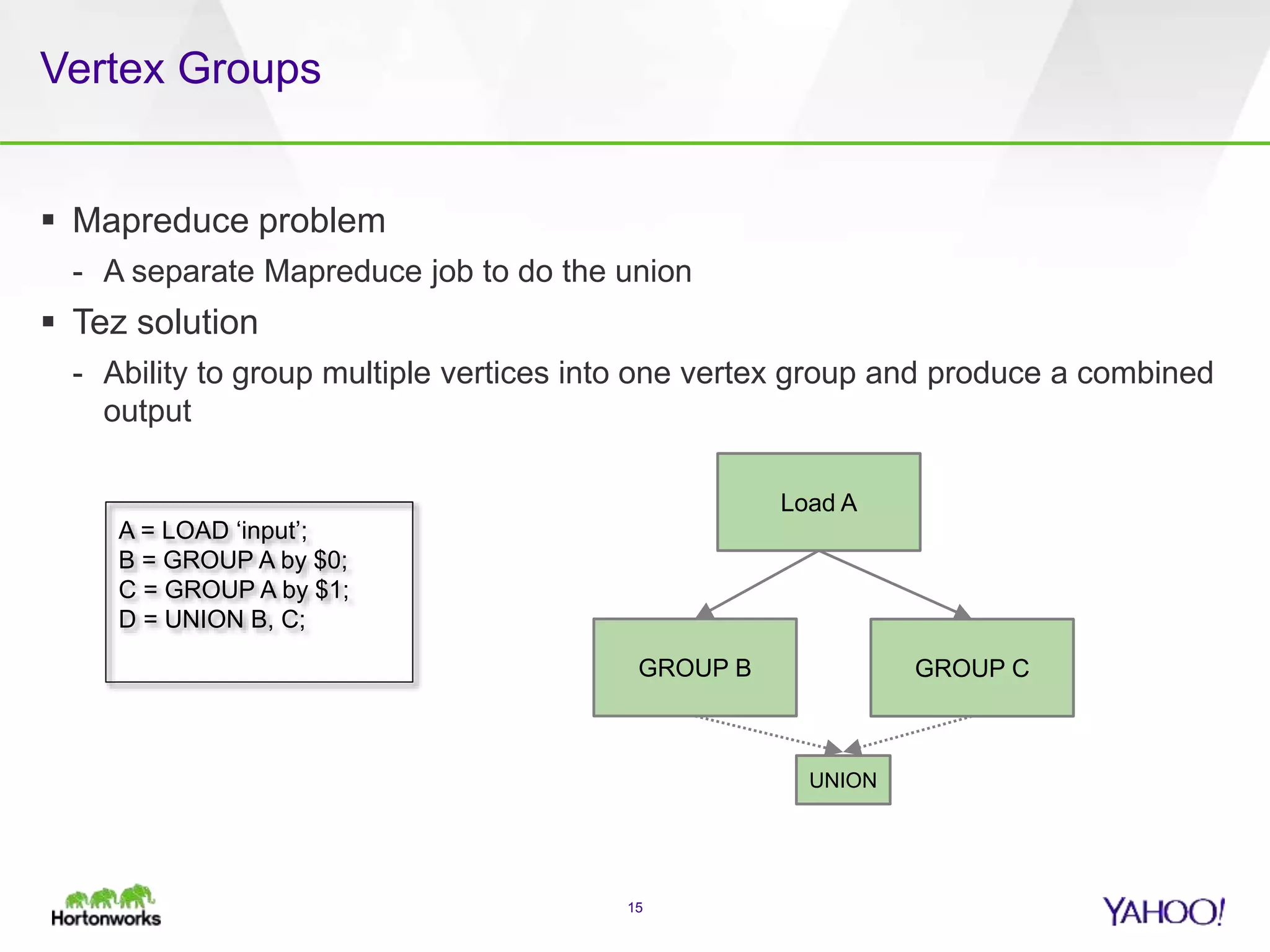


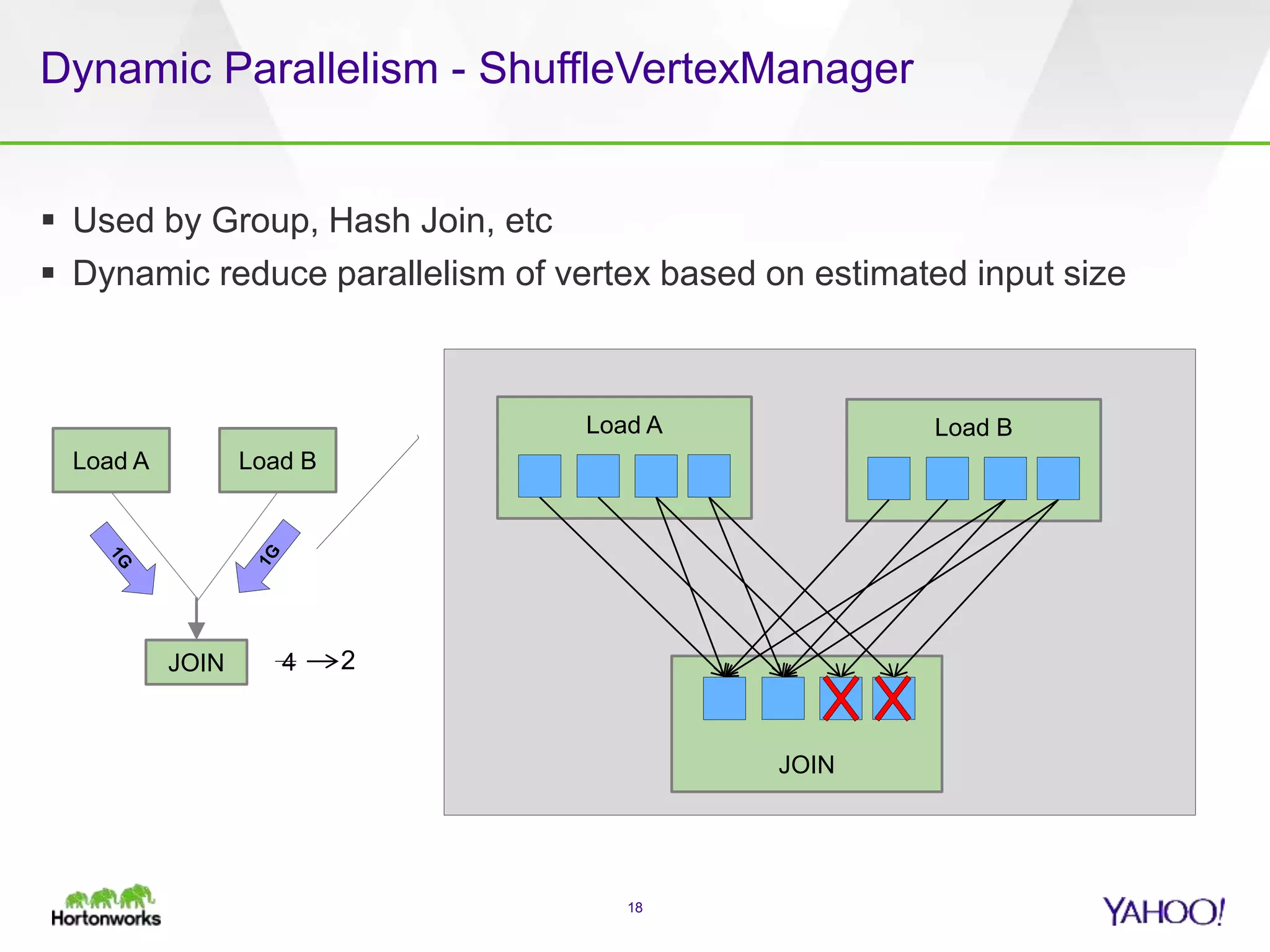
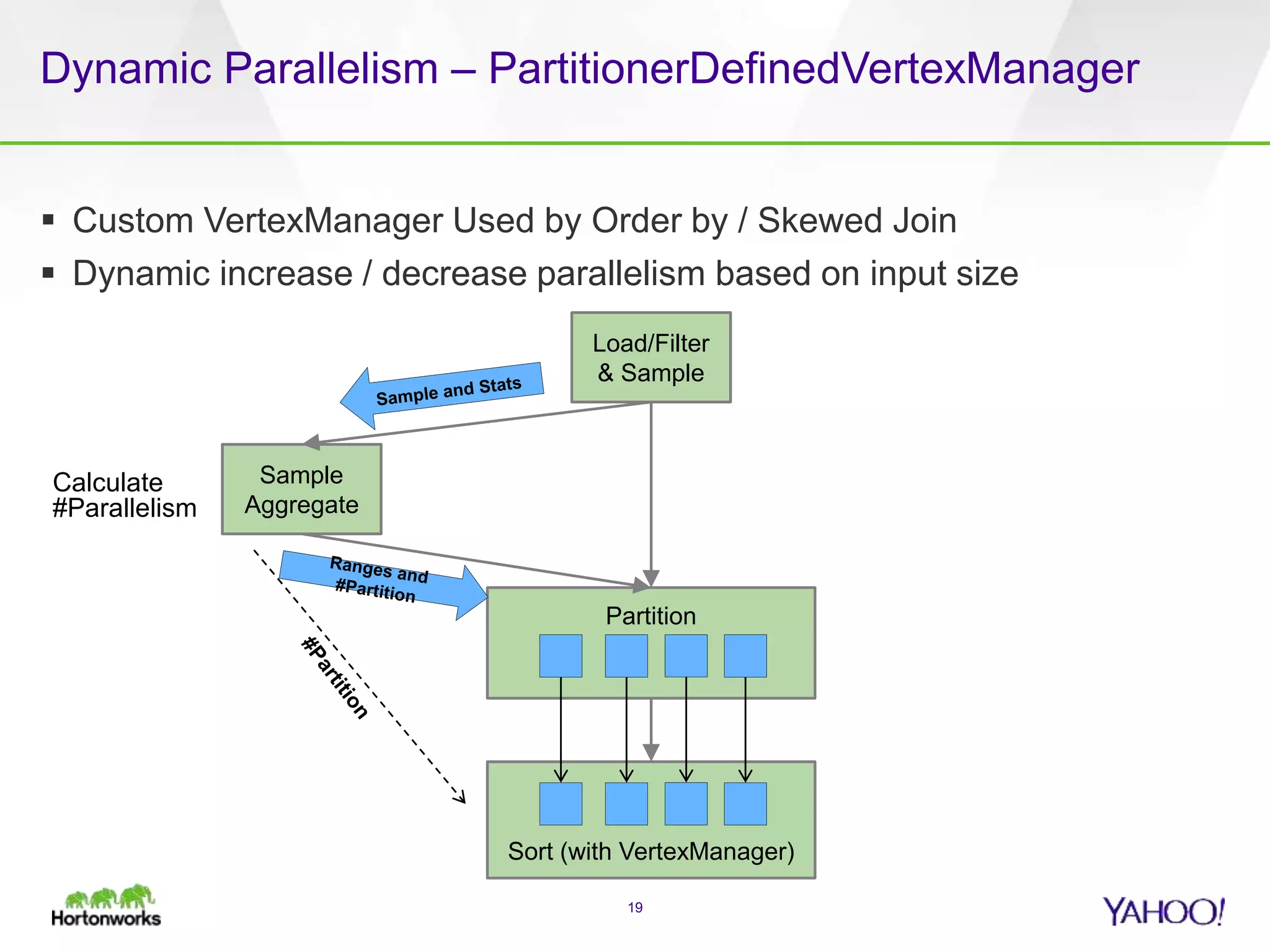


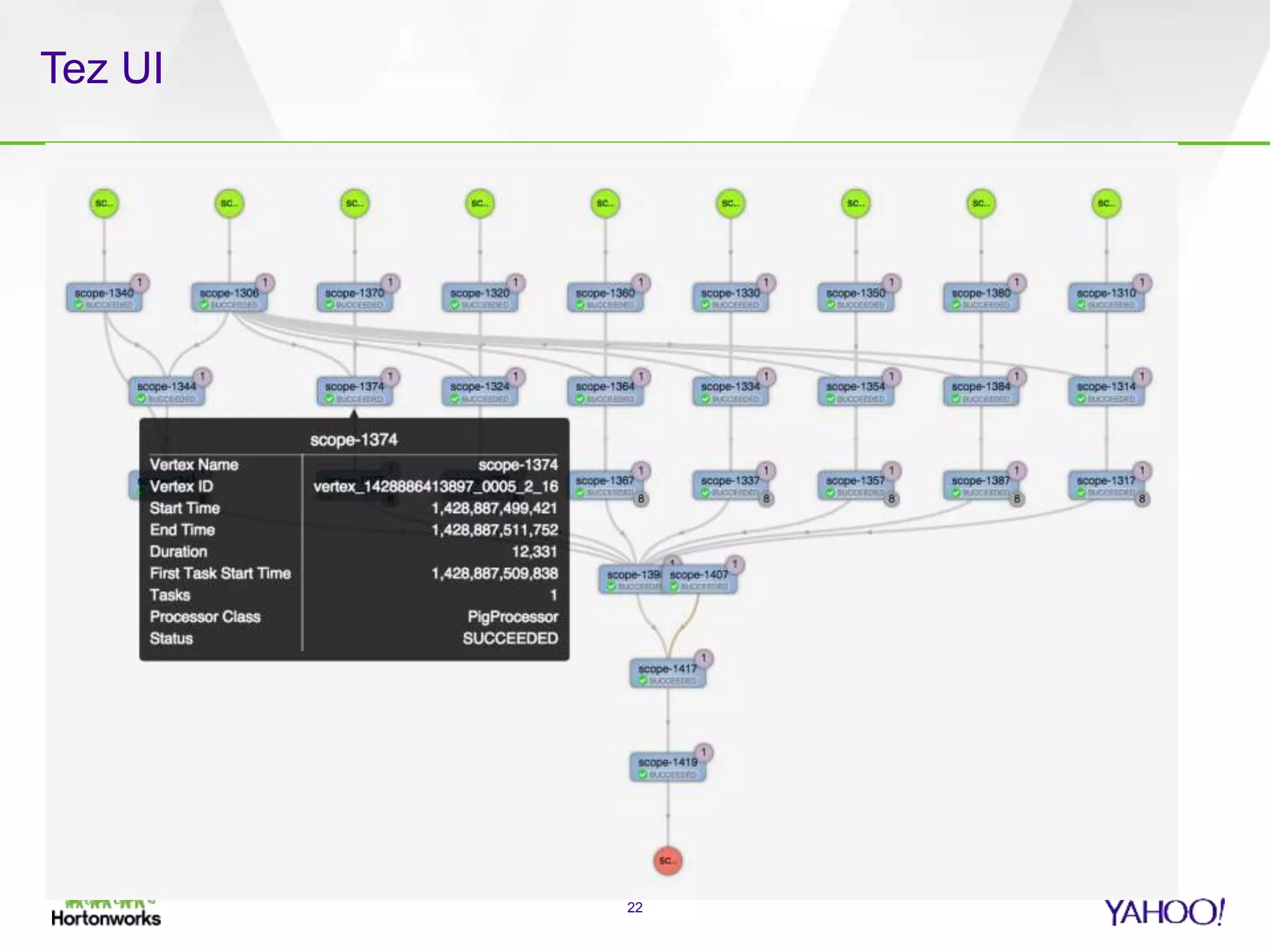


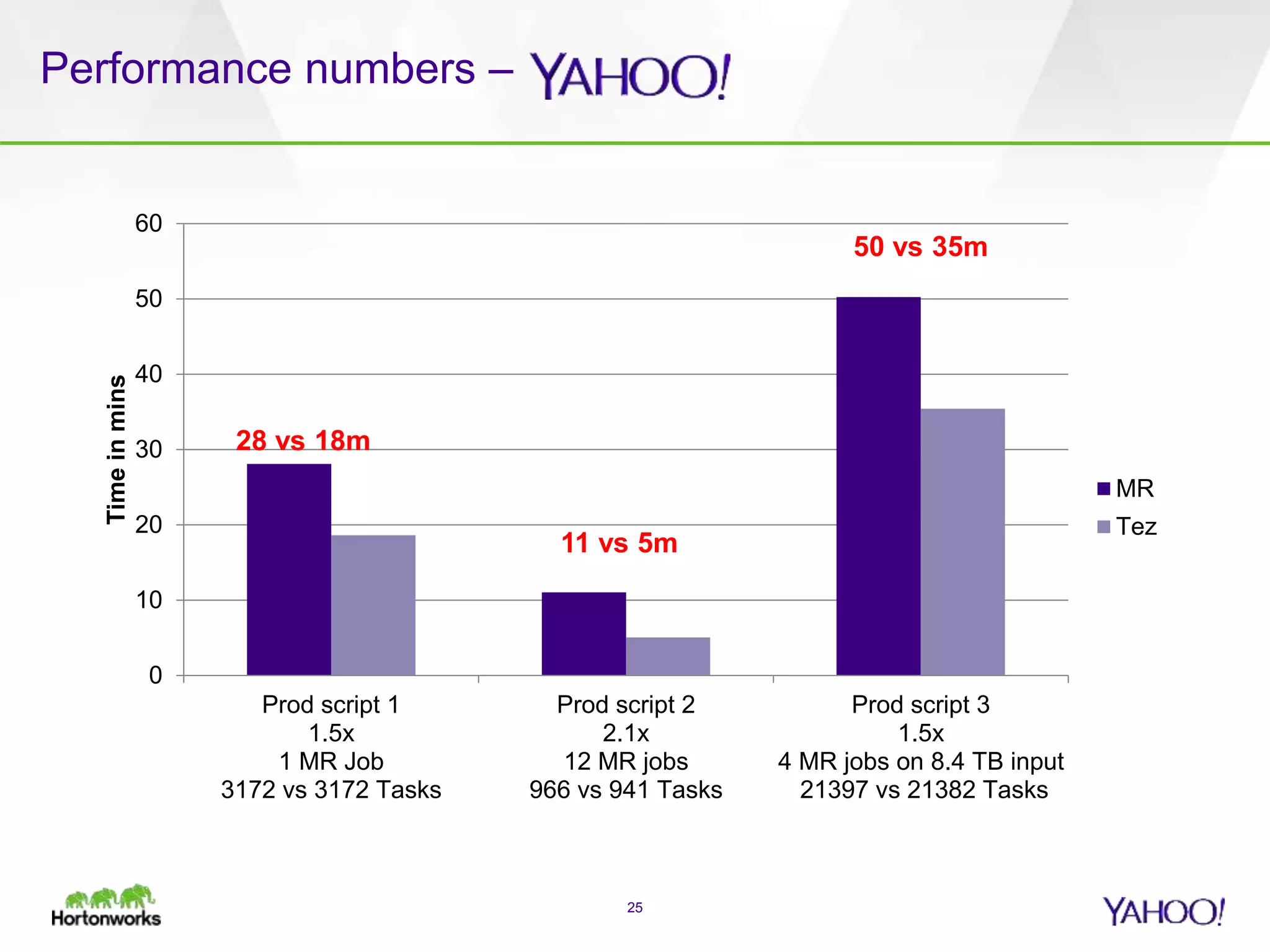
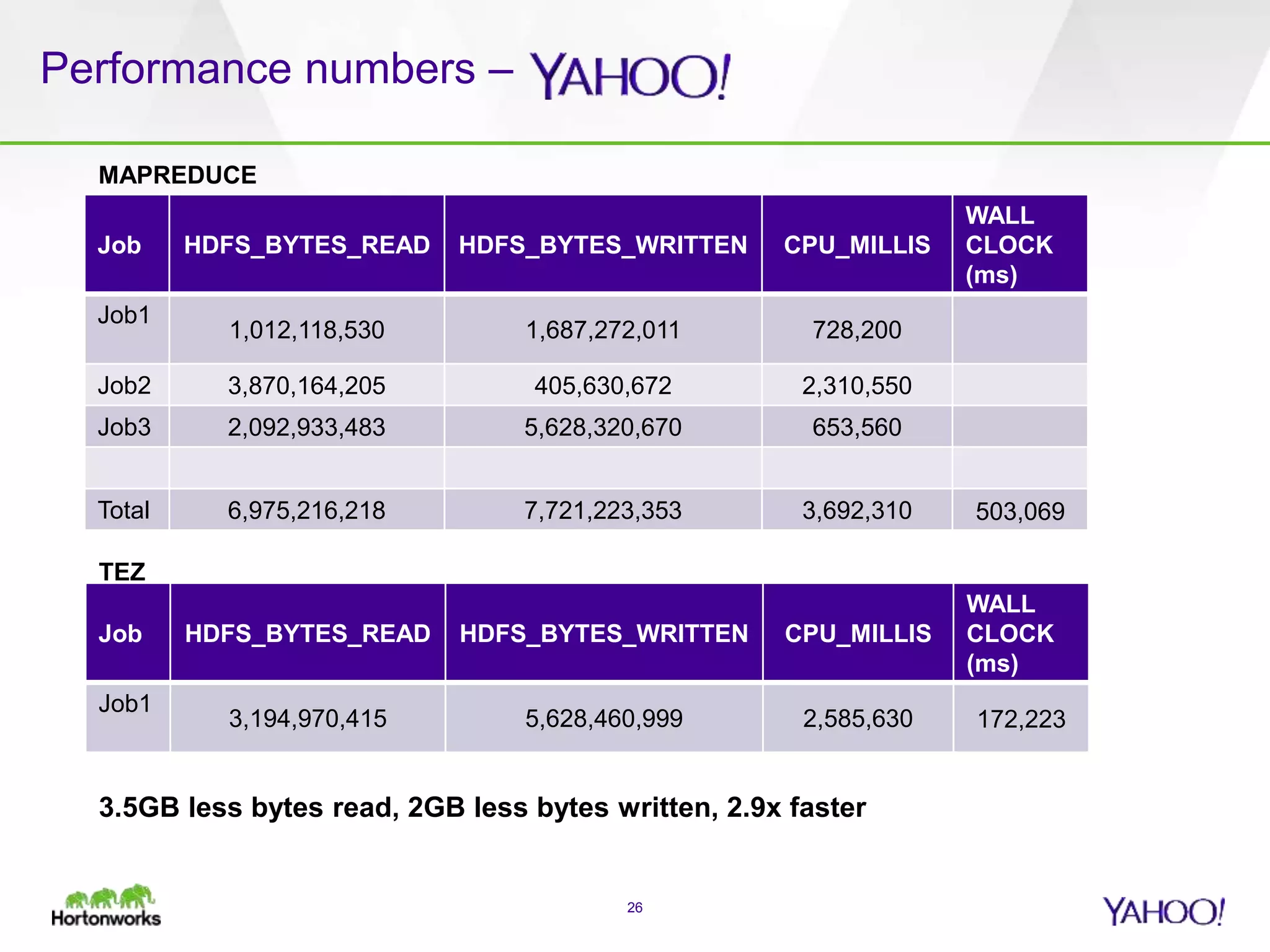
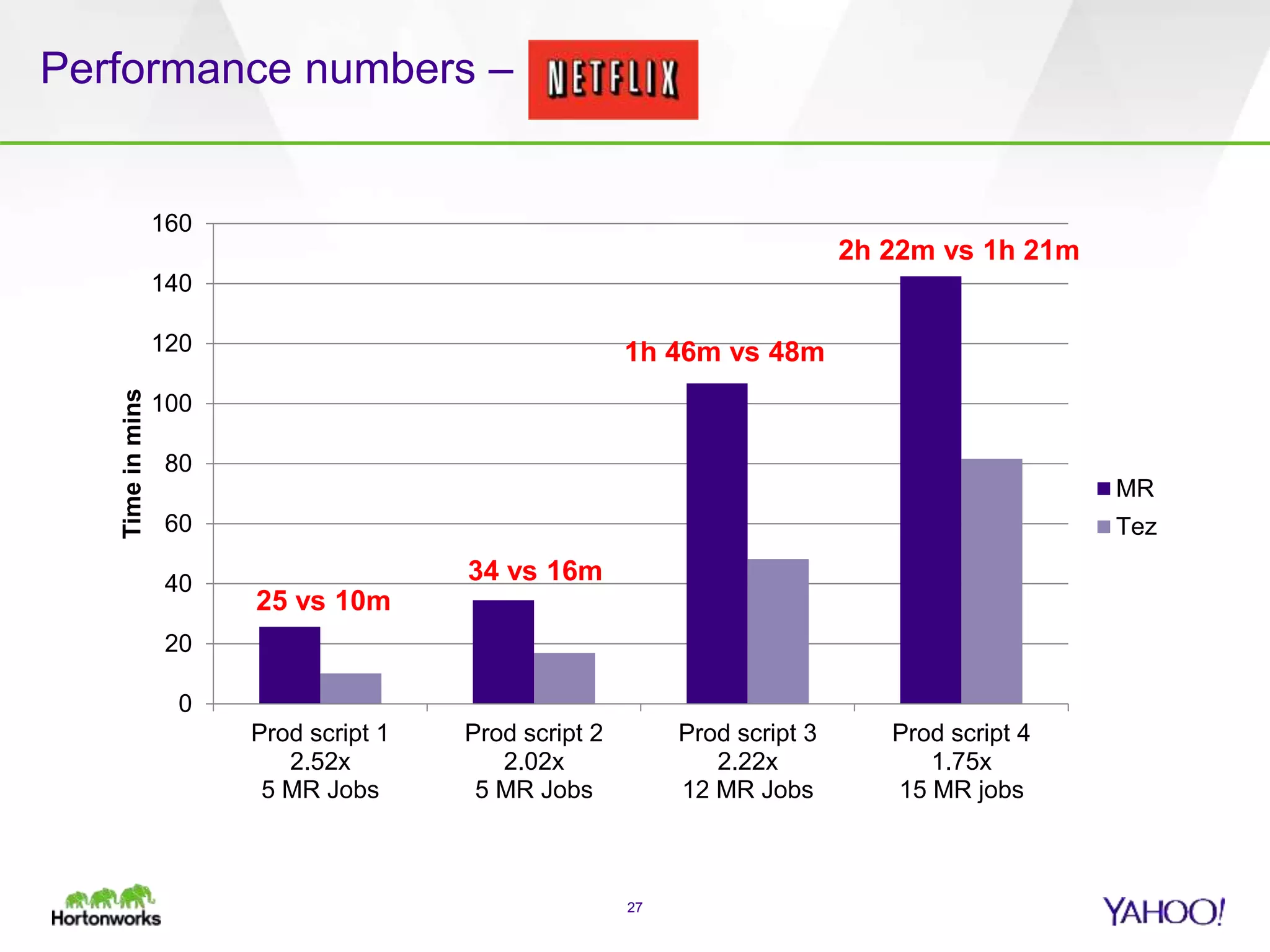
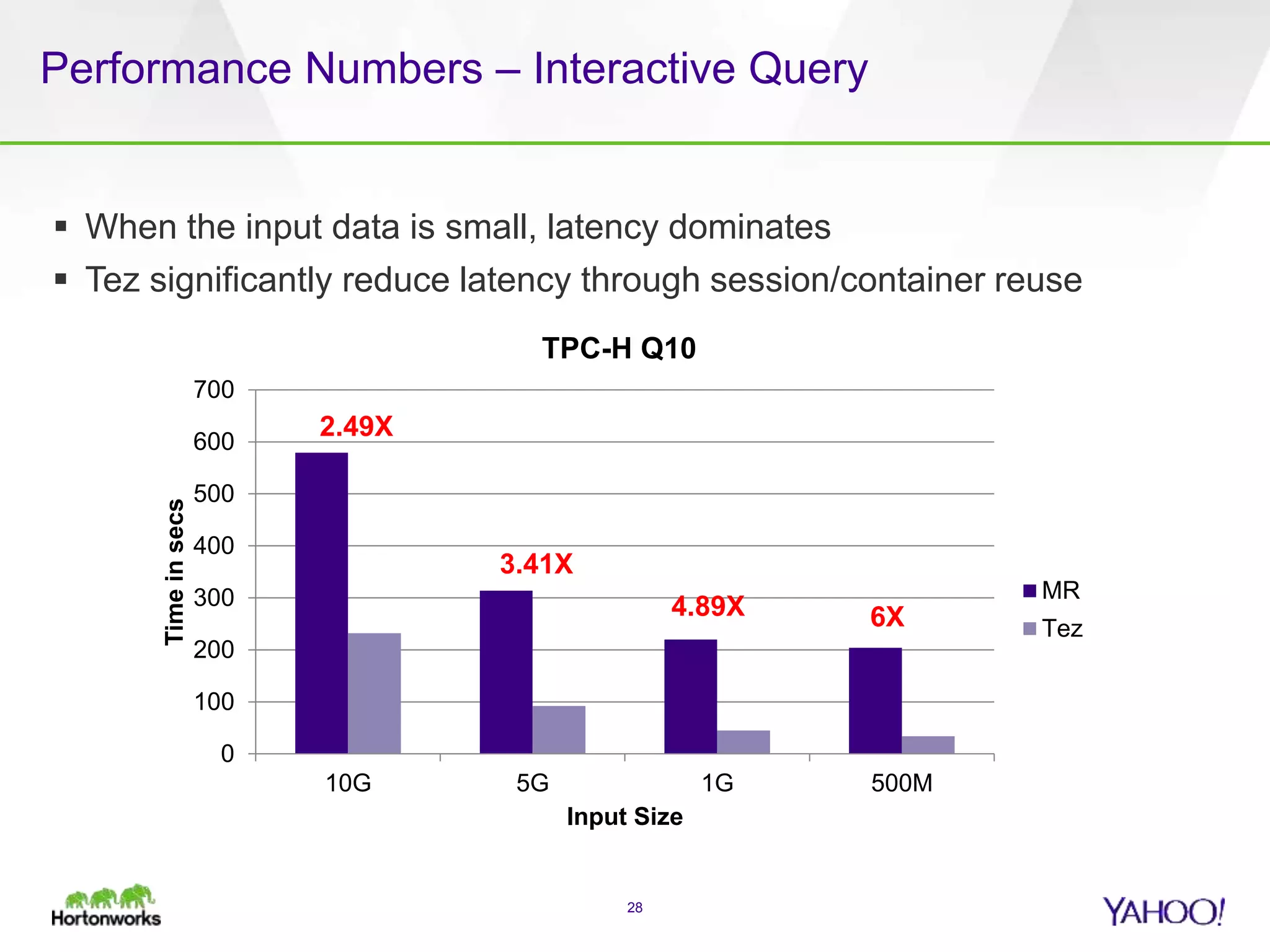









The document discusses the implementation of Apache Pig with the Tez execution engine for low-latency data processing, highlighting its design benefits, performance improvements, and current user experiences. It outlines how Tez enhances efficiency by allowing container reuse, automatic session handling, and dynamic parallelism adjustments. Additionally, it emphasizes Pig's rich features and its widespread use across major organizations, along with future enhancements planned for both Pig and Tez.










































![[2C1] 아파치 피그를 위한 테즈 연산 엔진 개발하기 최종](https://cdn.slidesharecdn.com/ss_thumbnails/2b1-140929191628-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













