









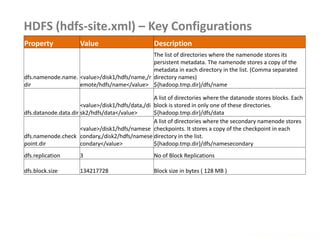



























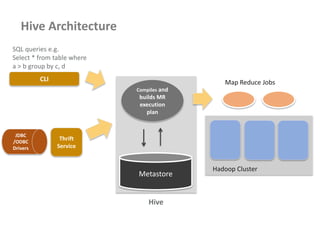
![Passing Parameters using Configuration
www.enablecloud.com
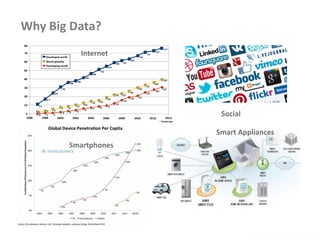
• Passing some parameters to mapper or reducer environments
• Configuration details can be passed using this technique
• Set the parameter in driver code as follows
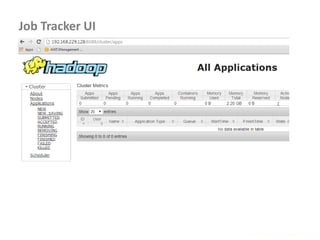
Configuration conf = new Configuration();
conf.set( "Product", args[0] );
conf.set( "Amount", args[1] );
• Retrieve the parameter in mapper or reducer code as follows
Configuration conf = context.getConfiguration();
String product = conf.get( "Product" ).trim();](https://image.slidesharecdn.com/hadoop2-160924154318/85/Hadoop-2-0-handout-5-0-60-320.jpg)
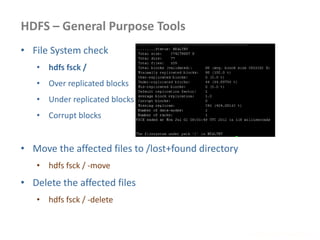
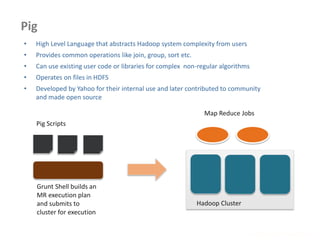
![Distribute Files and Retrieve in MR programs
www.enablecloud.com
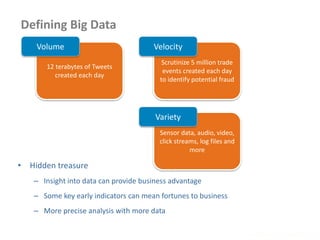
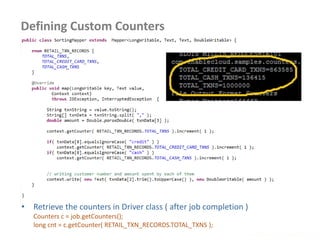
• Add cache file as follows
job.addCacheFile( new URI( <filepath>/<filename> ) );
yarn jar -files <file,file,file> <jar name> <Driver classname>
• Distributed cache can be used distribute jars and native libraries
job.addFileToClassPath( new Path( "/myapp/mylib.jar" ) );
yarn jar –libjars <f.jar, f2.jar> <jar name> <Driver classname>
• Retrieving the data files on the Map Reduce Programs
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
Path[] localPaths = context.getLocalCacheFiles();
if (localPaths.length == 0) {
throw new FileNotFoundException("Distributed cache file not found.");
}
File localFile = new File(localPaths[0].toUri());
}](https://image.slidesharecdn.com/hadoop2-160924154318/85/Hadoop-2-0-handout-5-0-61-320.jpg)
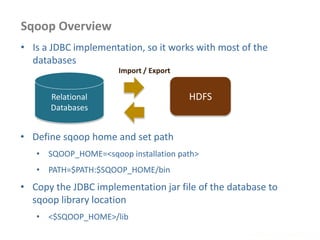
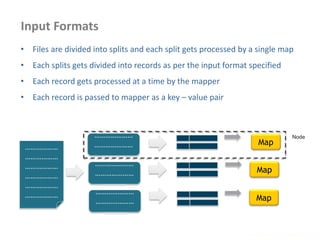
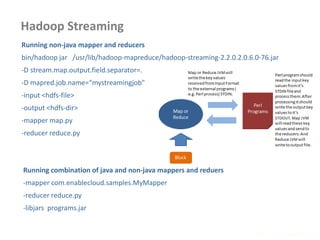
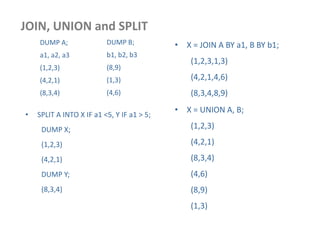
![Multiple Inputs
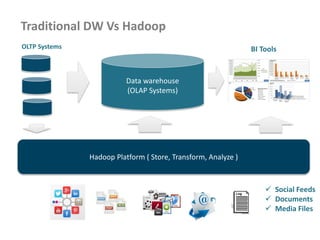
www.enablecloud.com
• Different input formats or
types
• Multiple mappers
needed to process
requests
MultipleInputs.addInputPath( job,
new Path( otherArgs[0] ),
FileInputFormat.class,
TxnSortingMapper.class );
MultipleInputs.addInputPath( job,
new Path( otherArgs[1] ),
KeyValueTextInputFormat.cla ss,
CustomerMapper.class );
Map 1
Passed to map()
Map 2
Passed to map()
Reduce](https://image.slidesharecdn.com/hadoop2-160924154318/85/Hadoop-2-0-handout-5-0-62-320.jpg)






















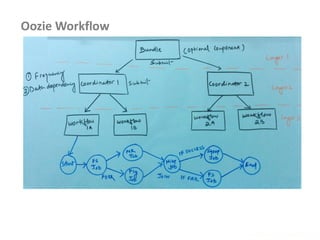



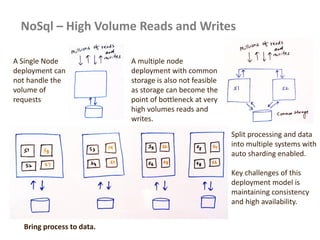
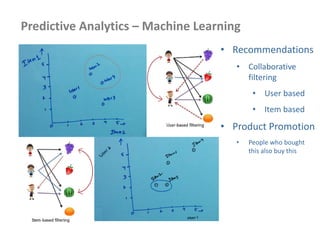




This document provides an overview of Hadoop and big data concepts. It discusses Hadoop core components like HDFS, YARN, MapReduce and how they work. It also covers related technologies like Hive, Pig, Sqoop and Flume. The document discusses common Hadoop configurations, deployment modes, use cases and best practices. It aims to help developers get started with Hadoop and build big data solutions.




















































































