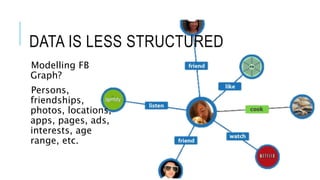
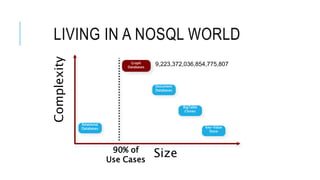
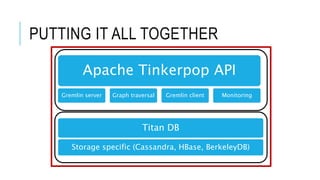
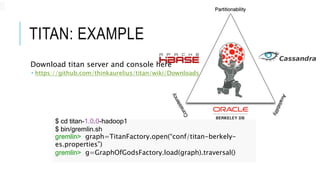
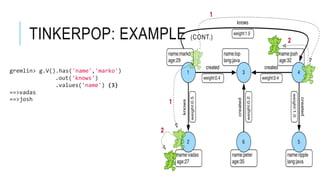
Graph databases are a solution for storing highly scalable semi-structured connected data. Apache Tinkerpop provides a unified API for graph databases to avoid vendor-specific code. Tinkerpop includes Gremlin for querying graphs and integrates with Titan, a scalable distributed graph database that can use backends like BerkeleyDB, HBase, or Cassandra for storage. This allows Titan graphs to scale linearly based on storage needs.






























































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)












