Downloaded 47 times








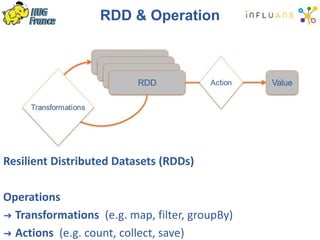
![Spark
scala> val textFile = sc.textFile("README.md")
➜ textFile: spark.RDD[String] = spark.MappedRDD@2ee9b6e3
scala> textFile.count()
➜ res0: Long = 126
scala> textFile.first()
➜ res1: String = # Apache Spark
scala> val linesWithSpark = textFile.filter(line =>
line.contains("Spark"))
➜ linesWithSpark: spark.RDD[String]=spark.FilteredRDD@7dd4
scala>
textFile.filter(line=>line.contains("Spark")).count()
➜ res3: Long = 15](https://image.slidesharecdn.com/20150204hug-sparkmeetup-ccarbone-150204131029-conversion-gate02/85/Paris-Spark-Meetup-Feb2015-ccarbone-SPARK-Streaming-vs-Storm-MLLib-NextProductToBuy-17-320.jpg)
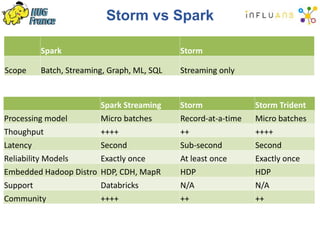
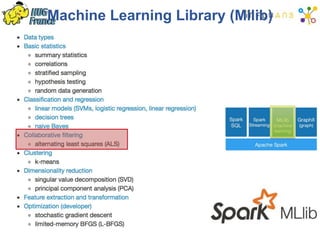


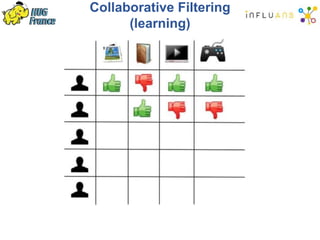
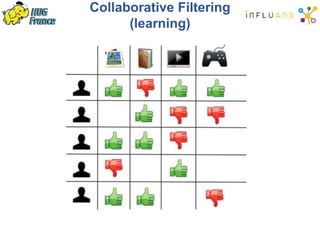


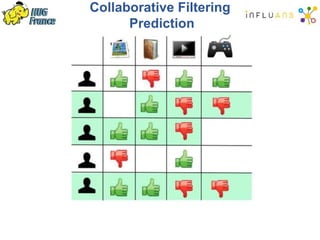


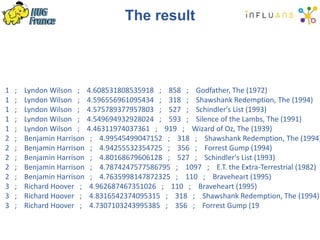



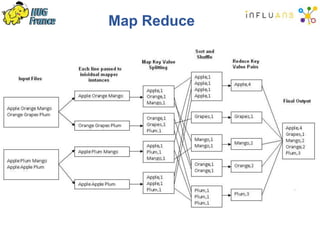
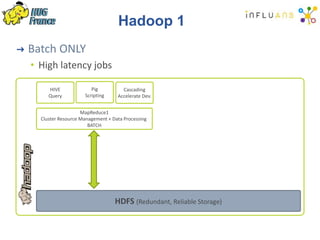
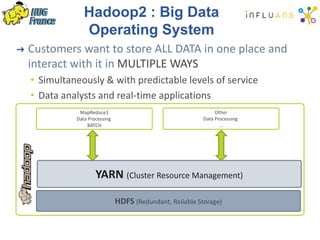
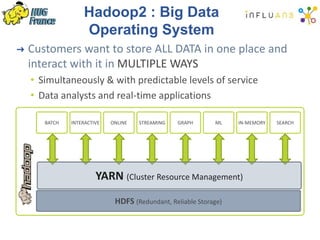
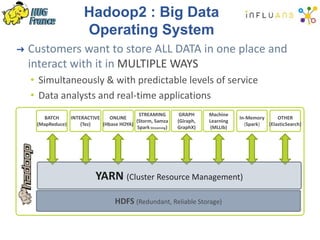
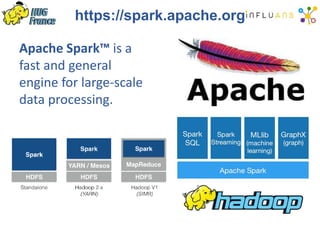
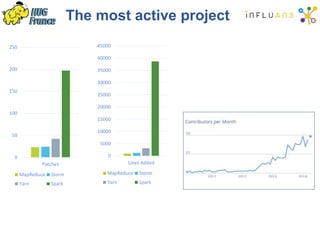
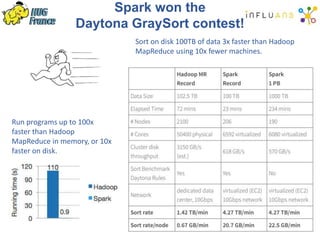
The document details a Spark meetup held on February 4, 2015, covering various aspects of Apache Spark and its applications in big data processing, including comparisons to Hadoop and discussions on Spark streaming and machine learning. Key speakers presented on topics such as real-time data processing, use cases like 'next product to buy,' and the integration of Spark with Cassandra for both batch and real-time analytics. The event highlighted Spark's advantages over traditional MapReduce, showcasing its speed and flexibility for data processing tasks.















































