Downloaded 102 times







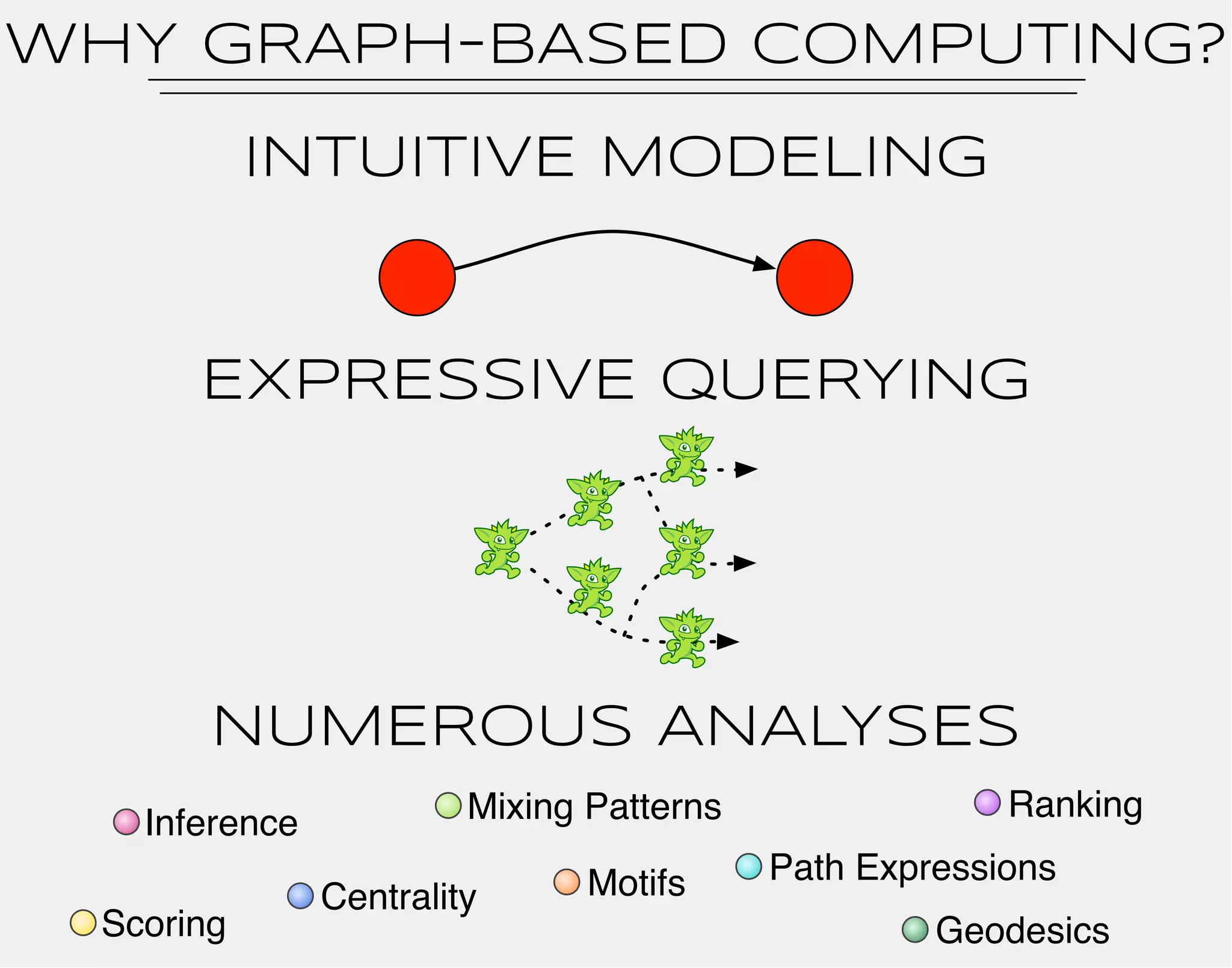



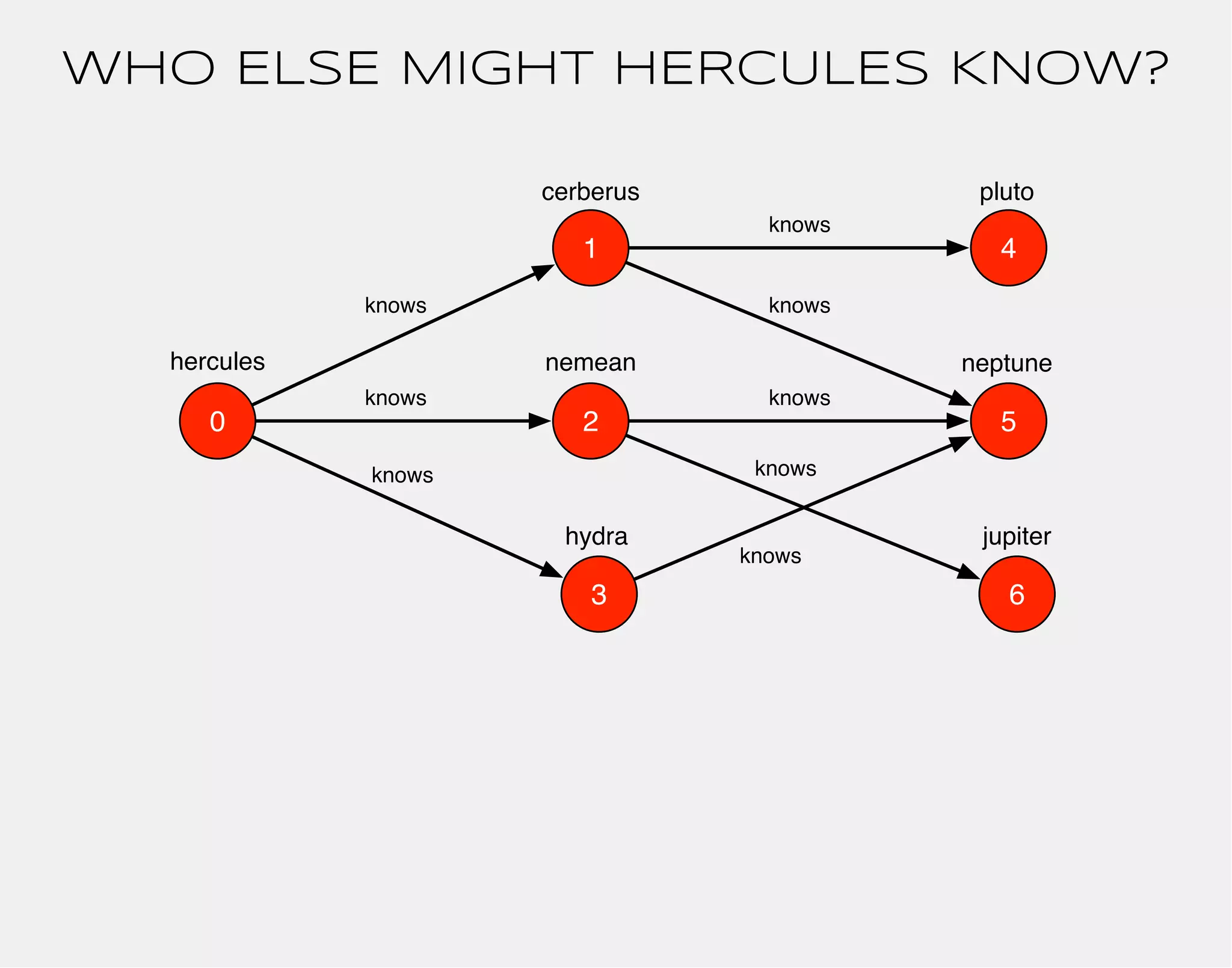
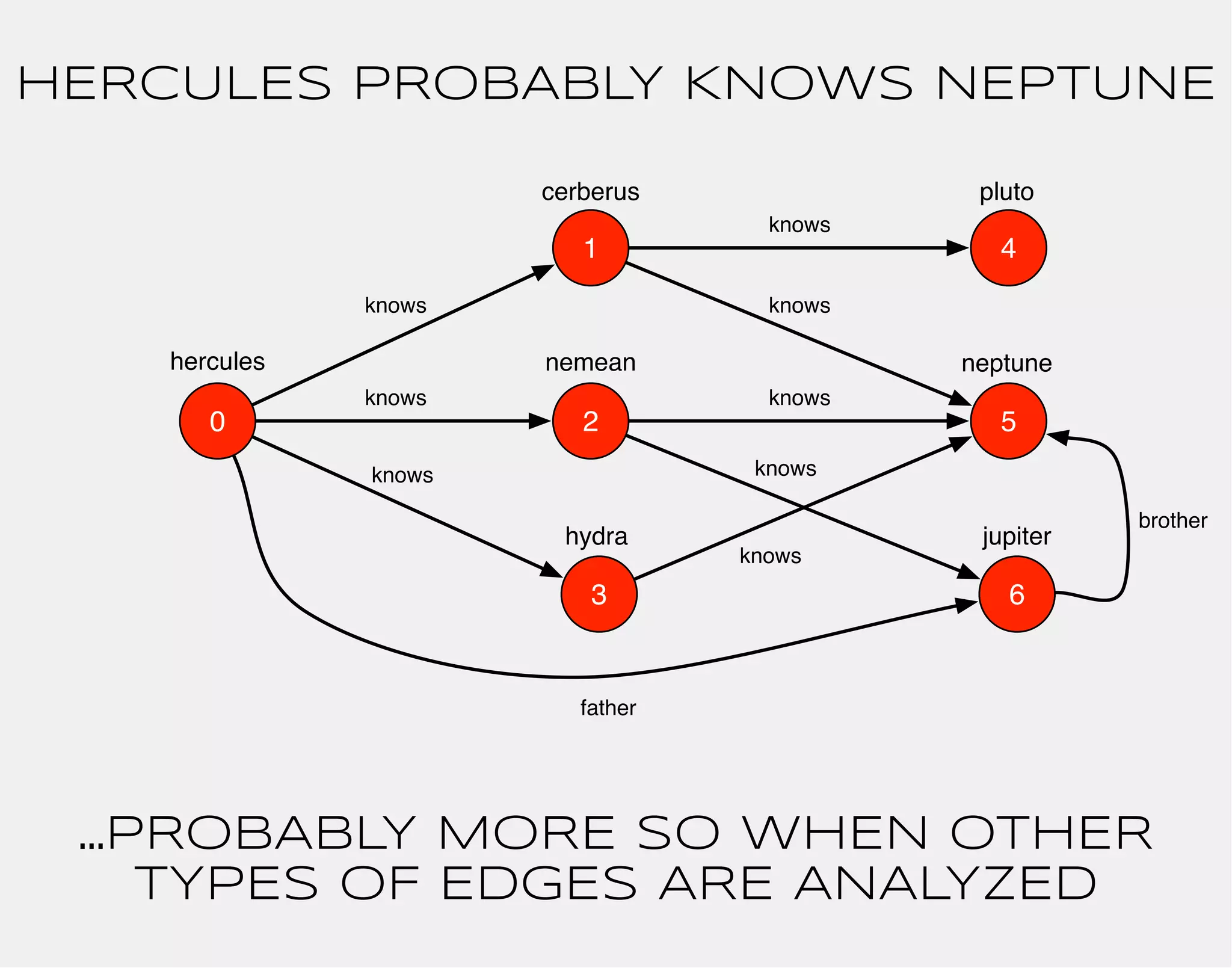
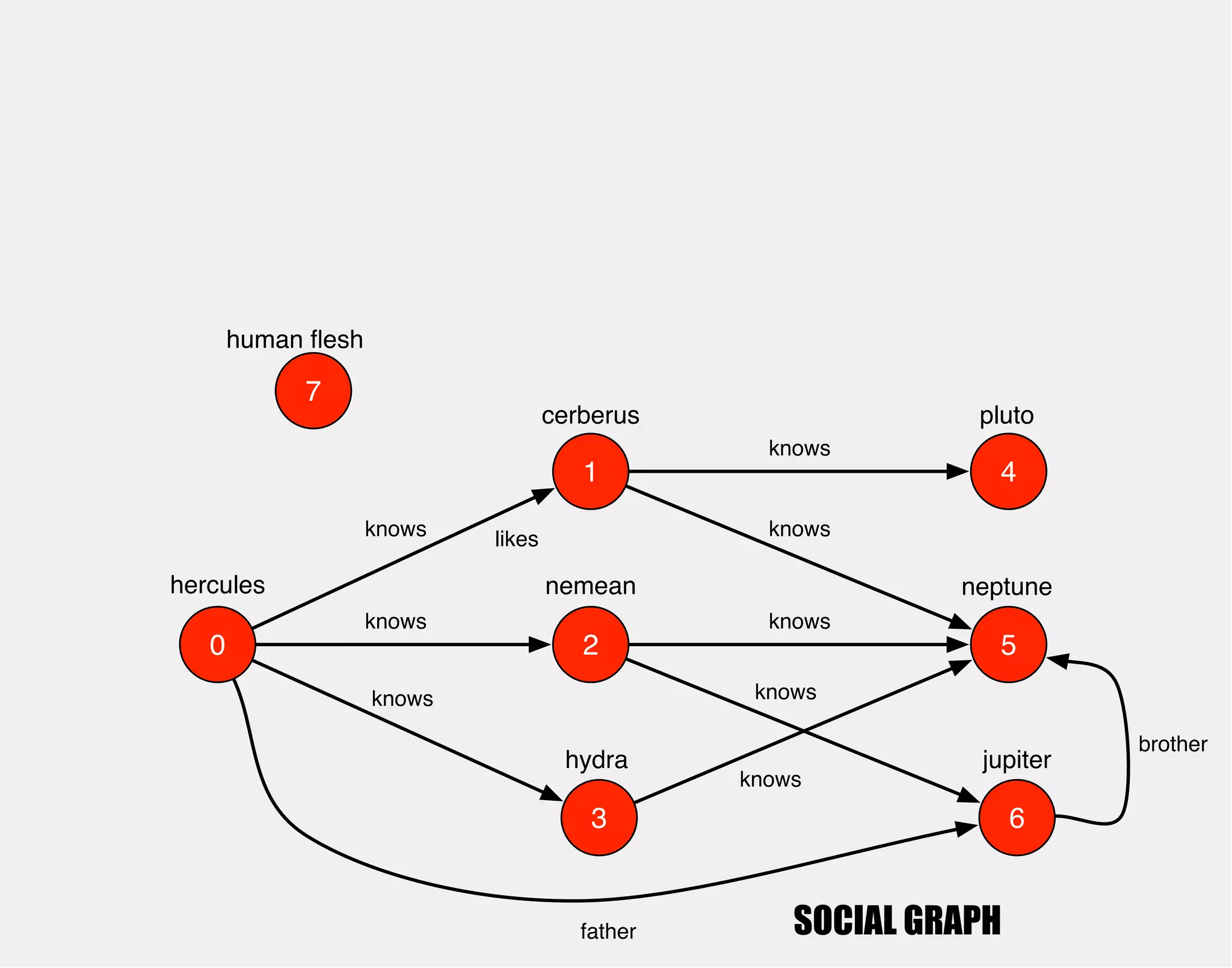
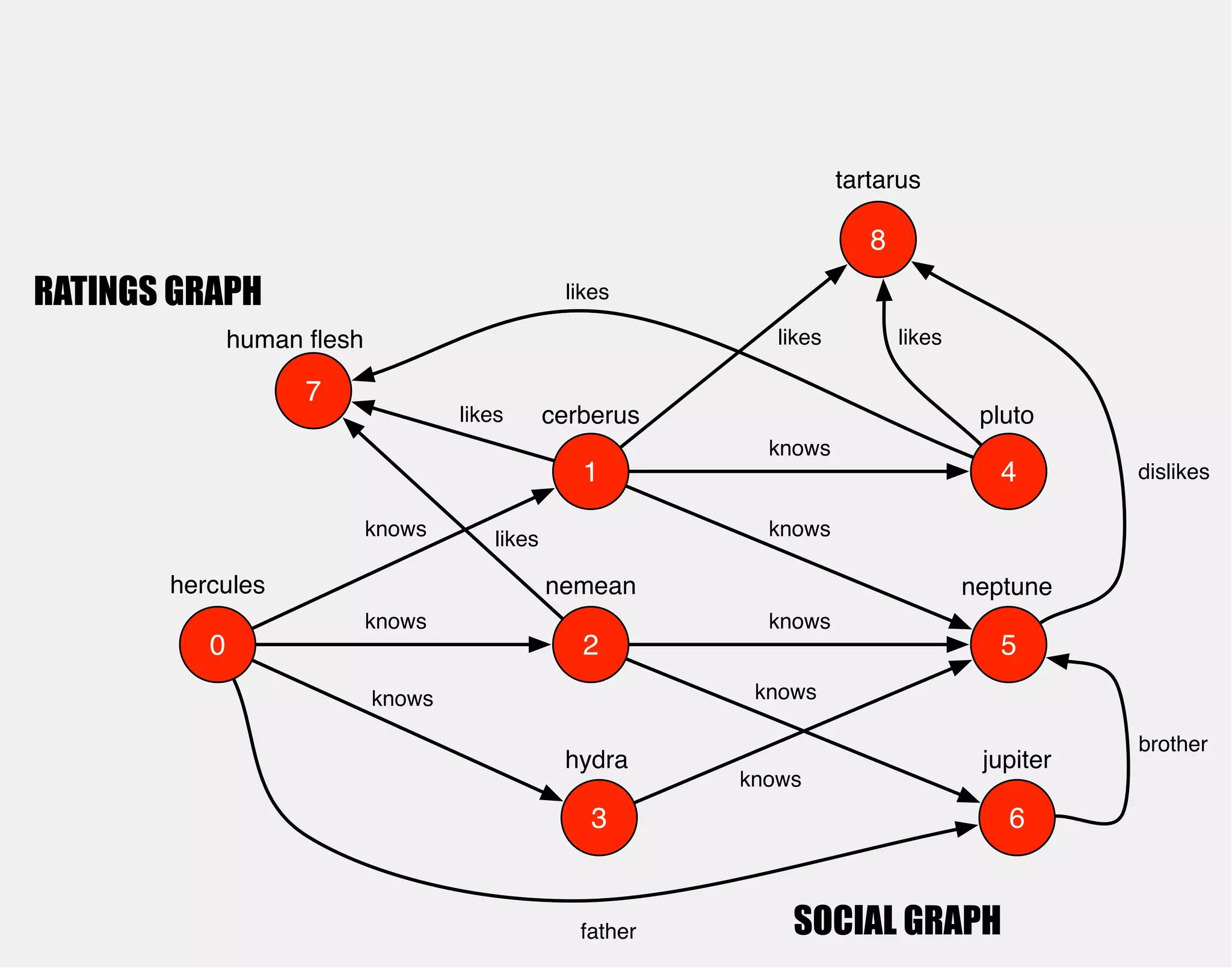
![hercules
1
0 2
3
4
5
6
cerberus
nemean
hydra
knows
knows
knows
pluto
neptune
jupiter
knows
knows
knows
knows
knows
gremlin> hercules
==>v[0]](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-26-2048.jpg)
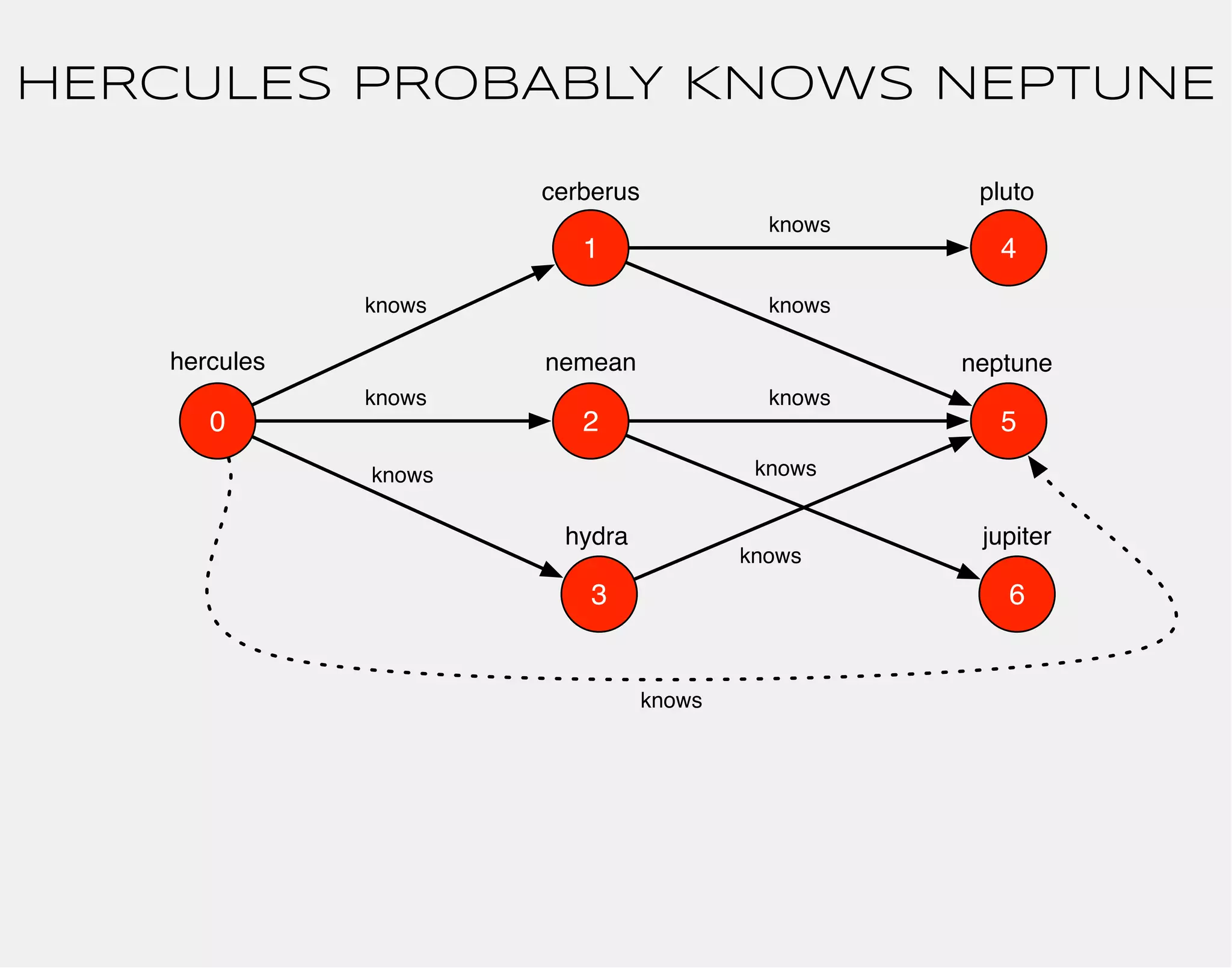
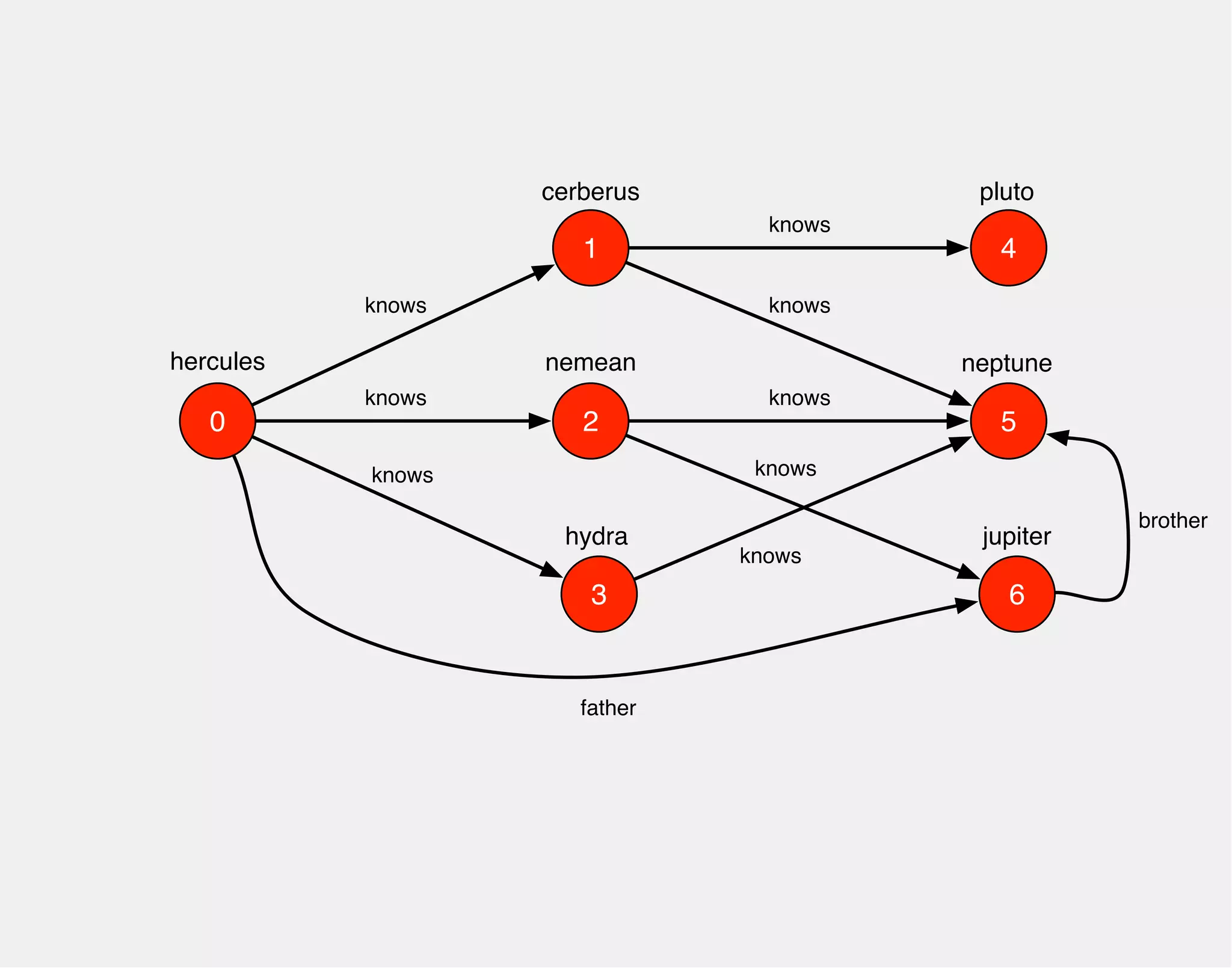
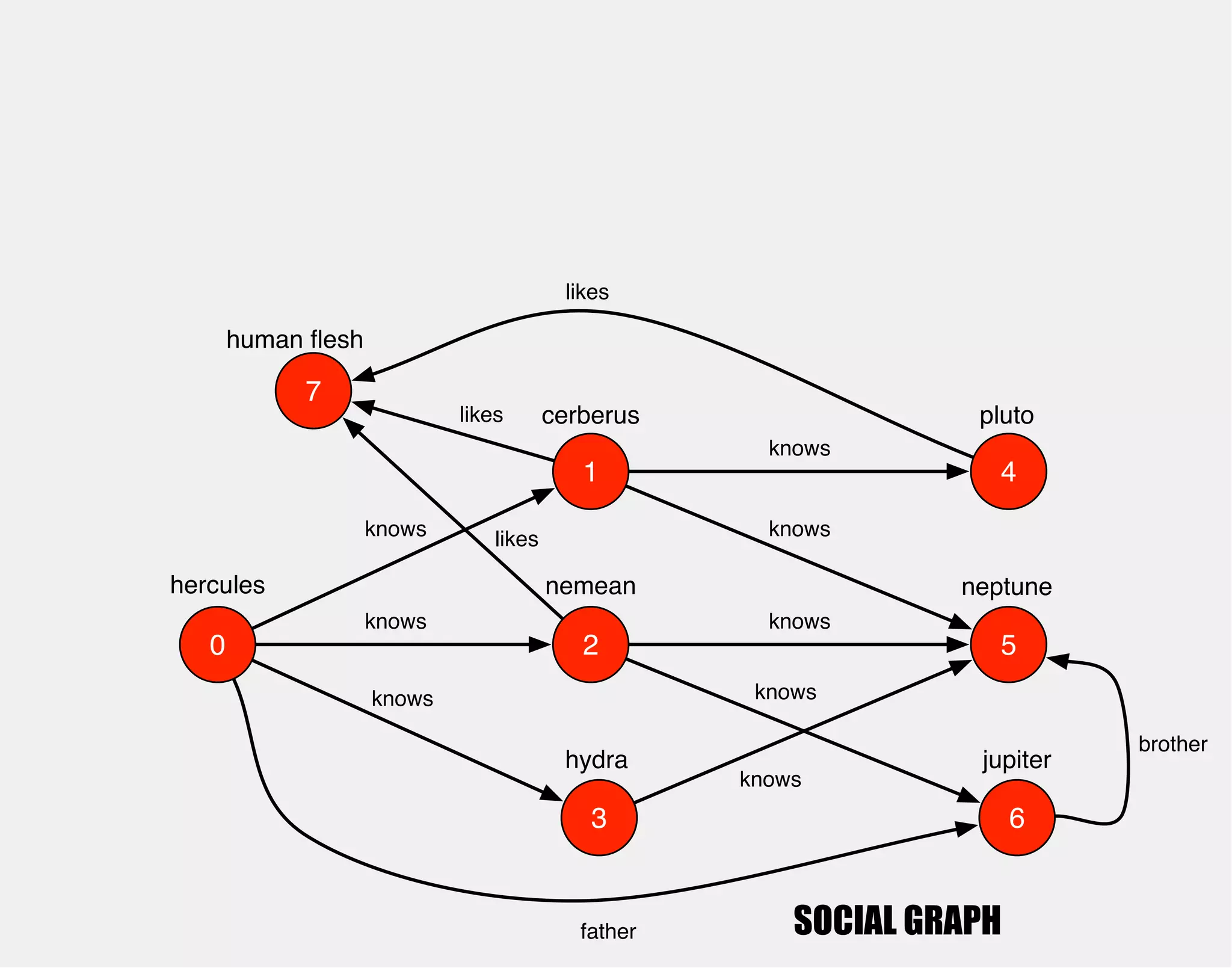
![hercules
1
0 2
3
4
5
6
cerberus
nemean
hydra
knows
knows
knows
pluto
neptune
jupiter
knows
knows
knows
knows
knows
gremlin> hercules.out('knows')
==>v[1]
==>v[2]
==>v[3]](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-27-2048.jpg)
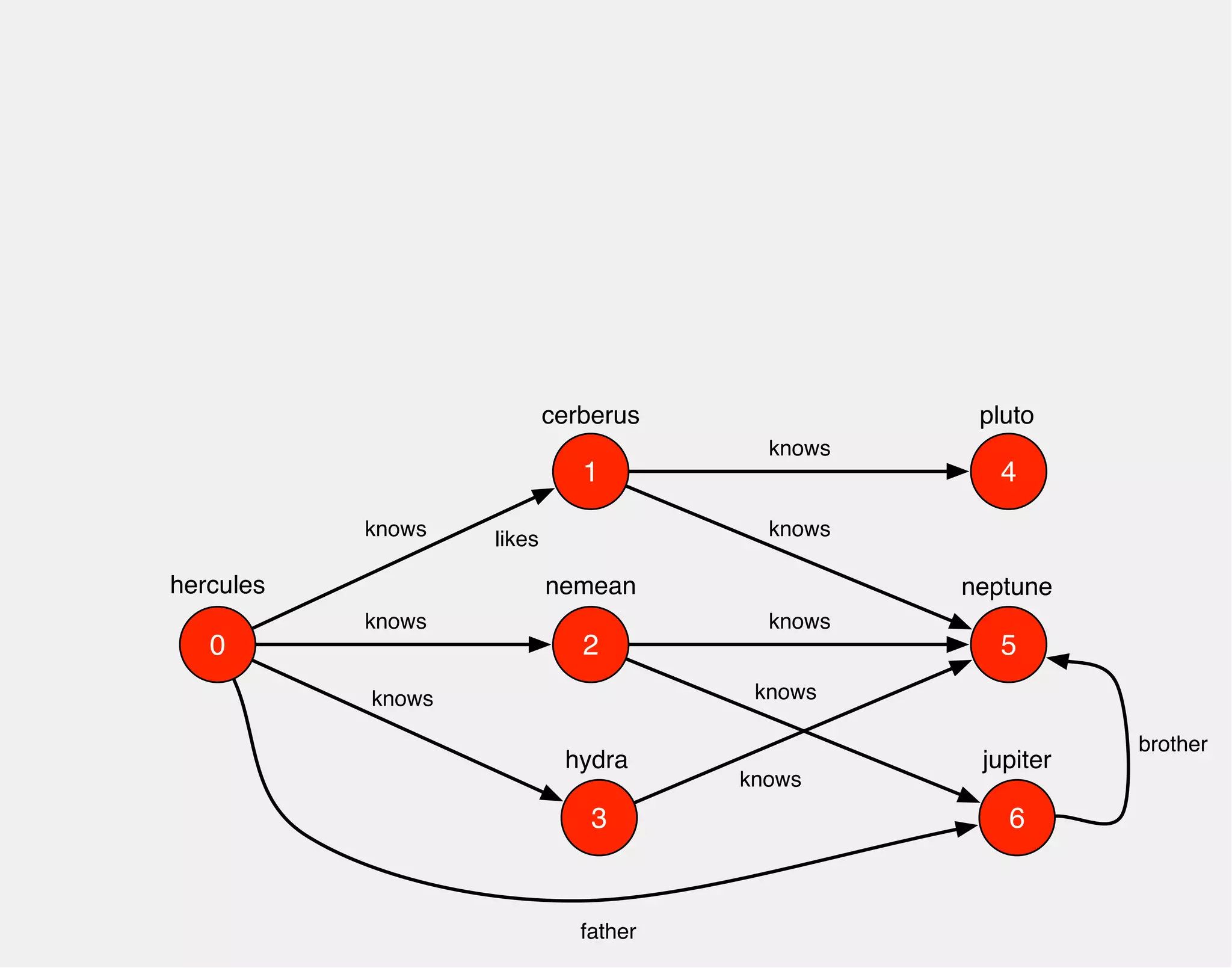
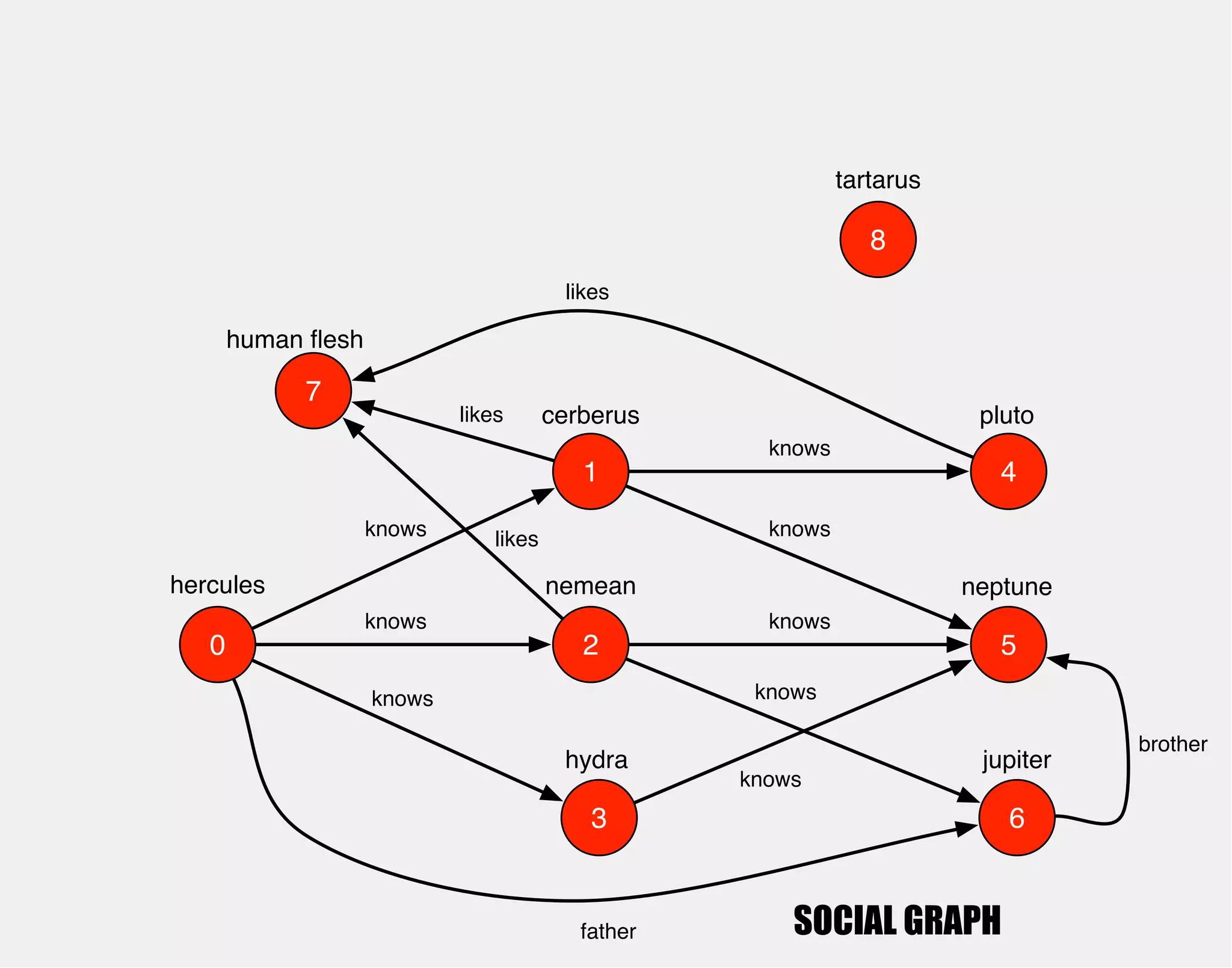
![hercules
1
0 2
3
4
5
6
cerberus
nemean
hydra
knows
knows
knows
pluto
neptune
jupiter
knows
knows
knows
knows
knows
gremlin> hercules.out('knows').out('knows')
==>v[4]
==>v[5]
==>v[5]
==>v[6]
==>v[5]](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-28-2048.jpg)
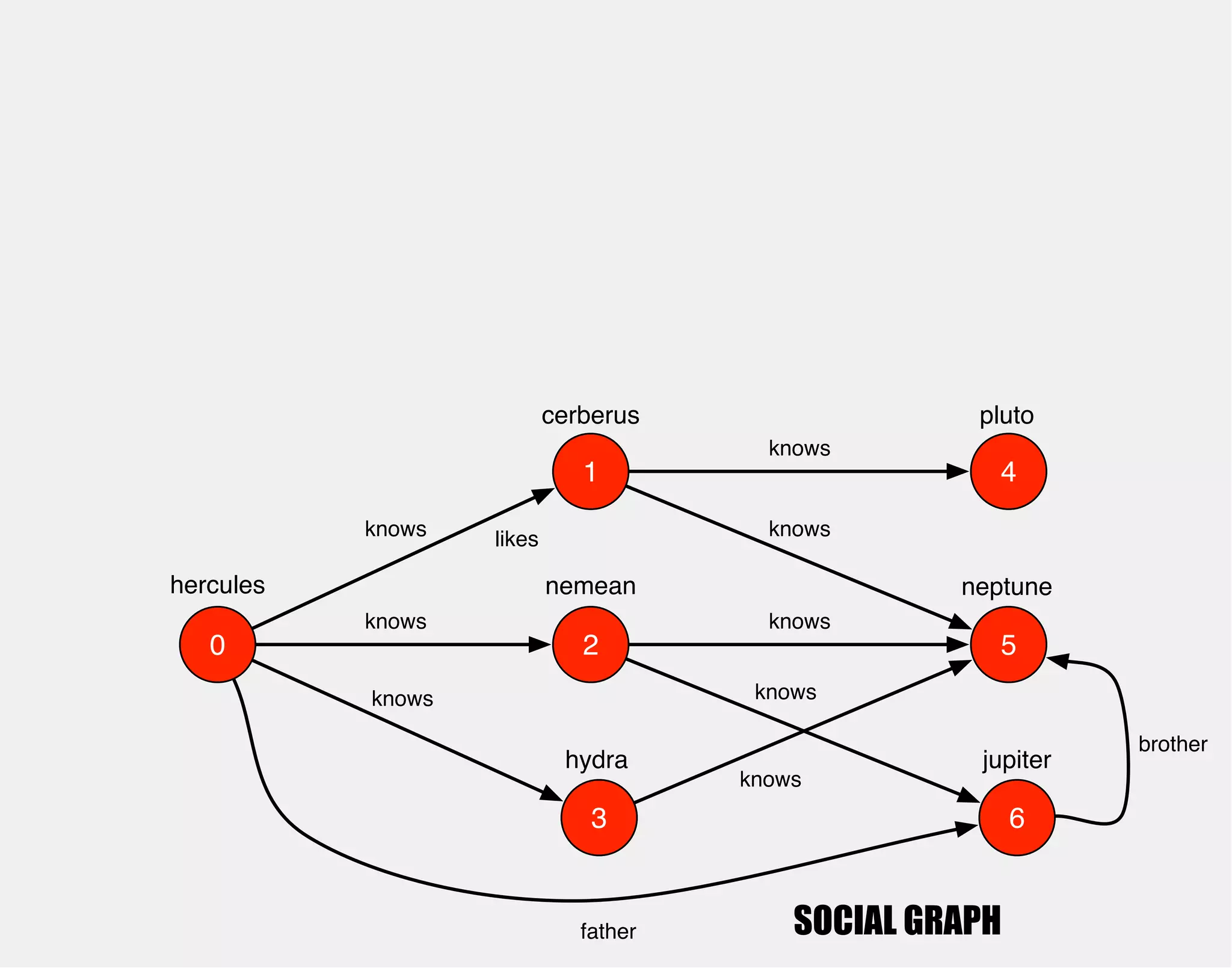
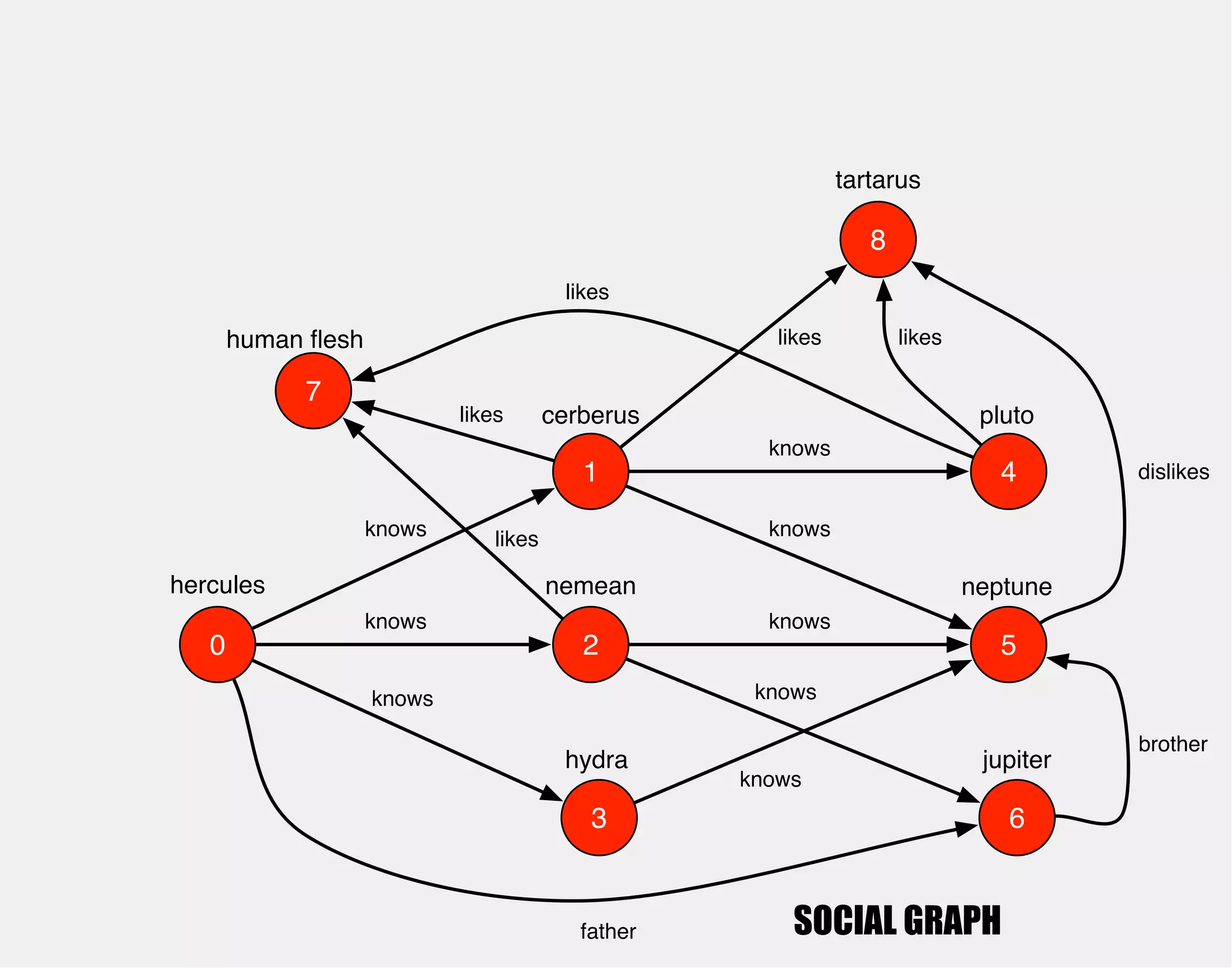
![hercules
1
0 2
3
4
5
6
cerberus
nemean
hydra
knows
knows
knows
pluto
neptune
jupiter
knows
knows
knows
knows
knows
gremlin> hercules.out('knows').out('knows').groupCount()
==>v[4]=1
==>v[5]=3
==>v[6]=1](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-29-2048.jpg)

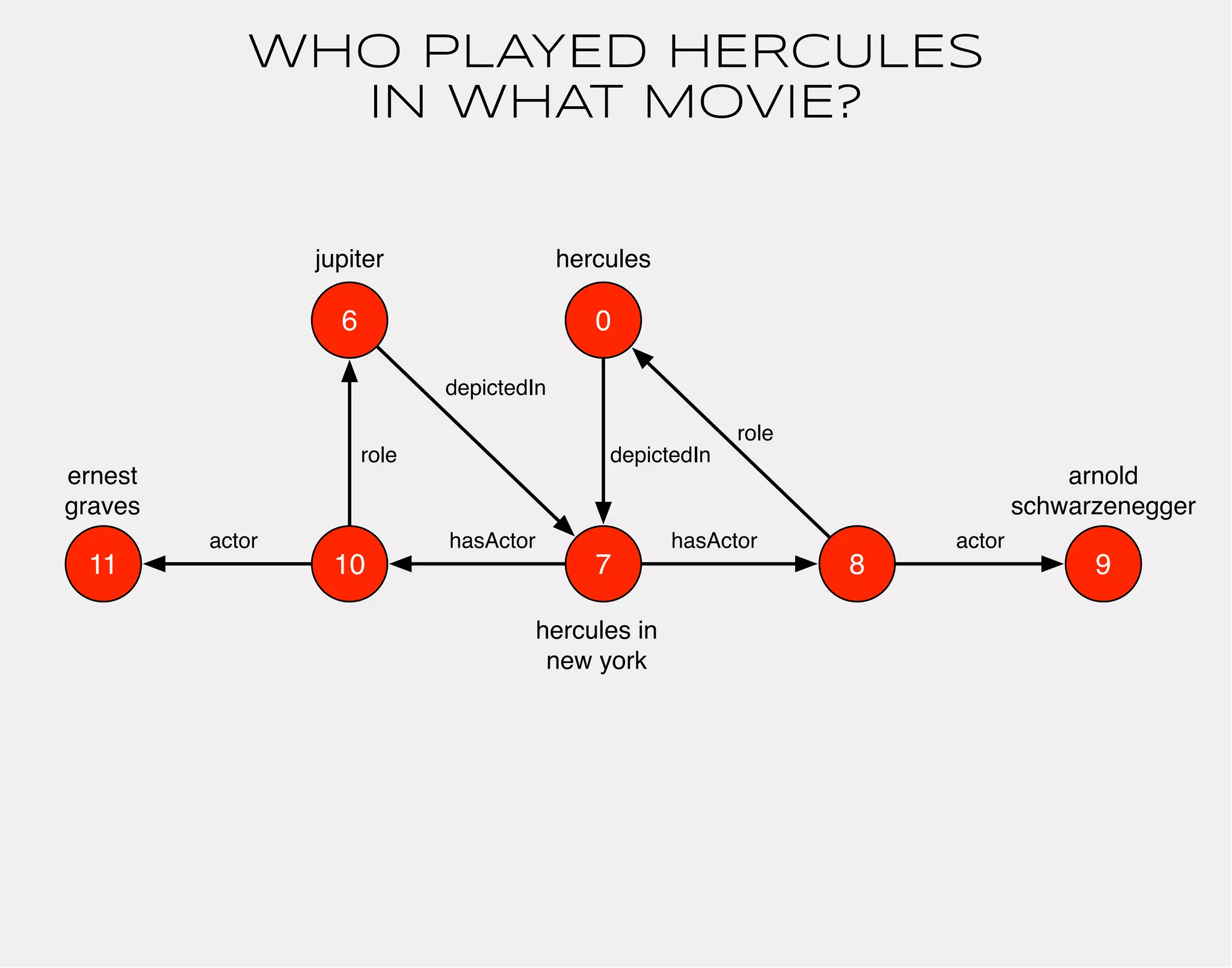

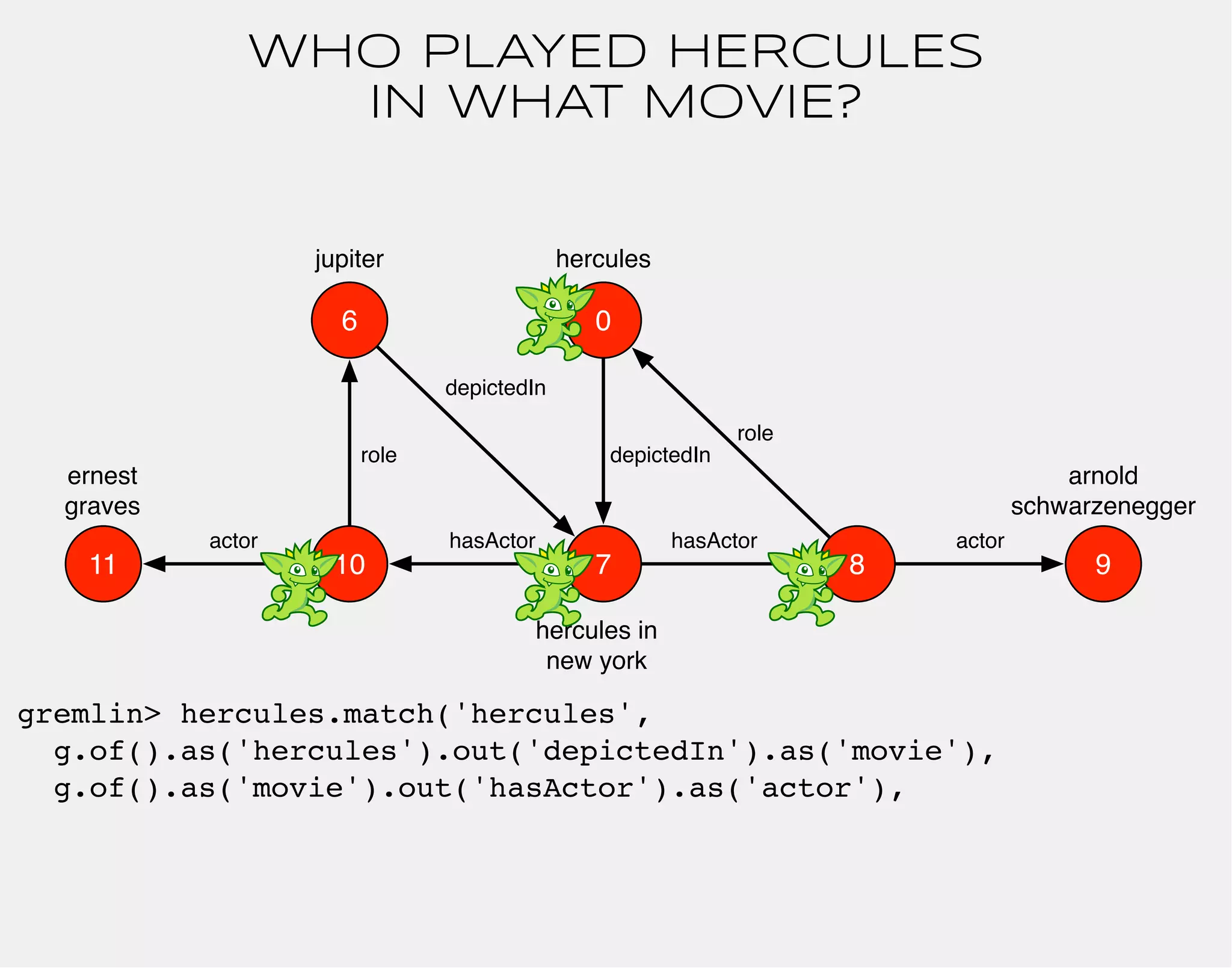

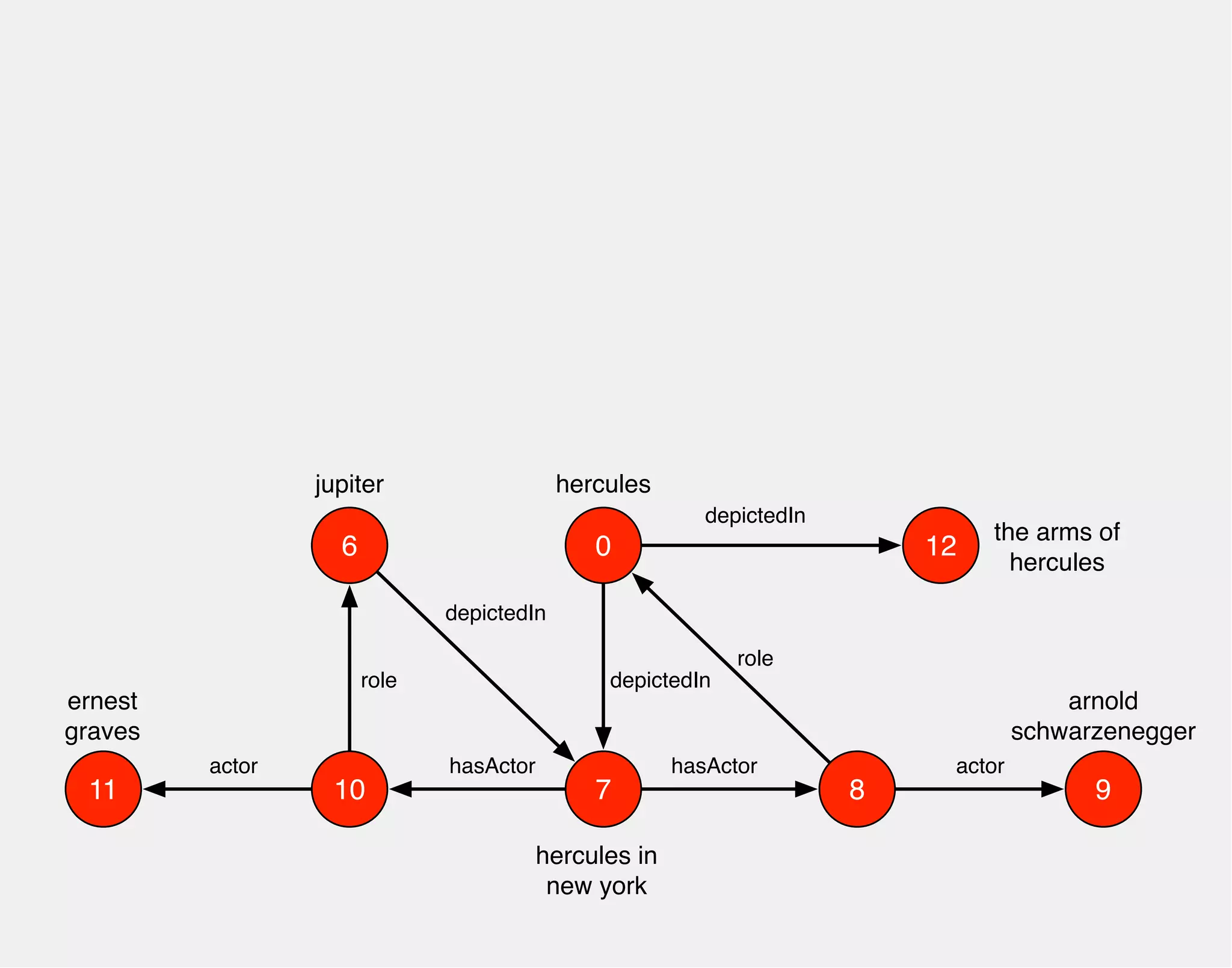
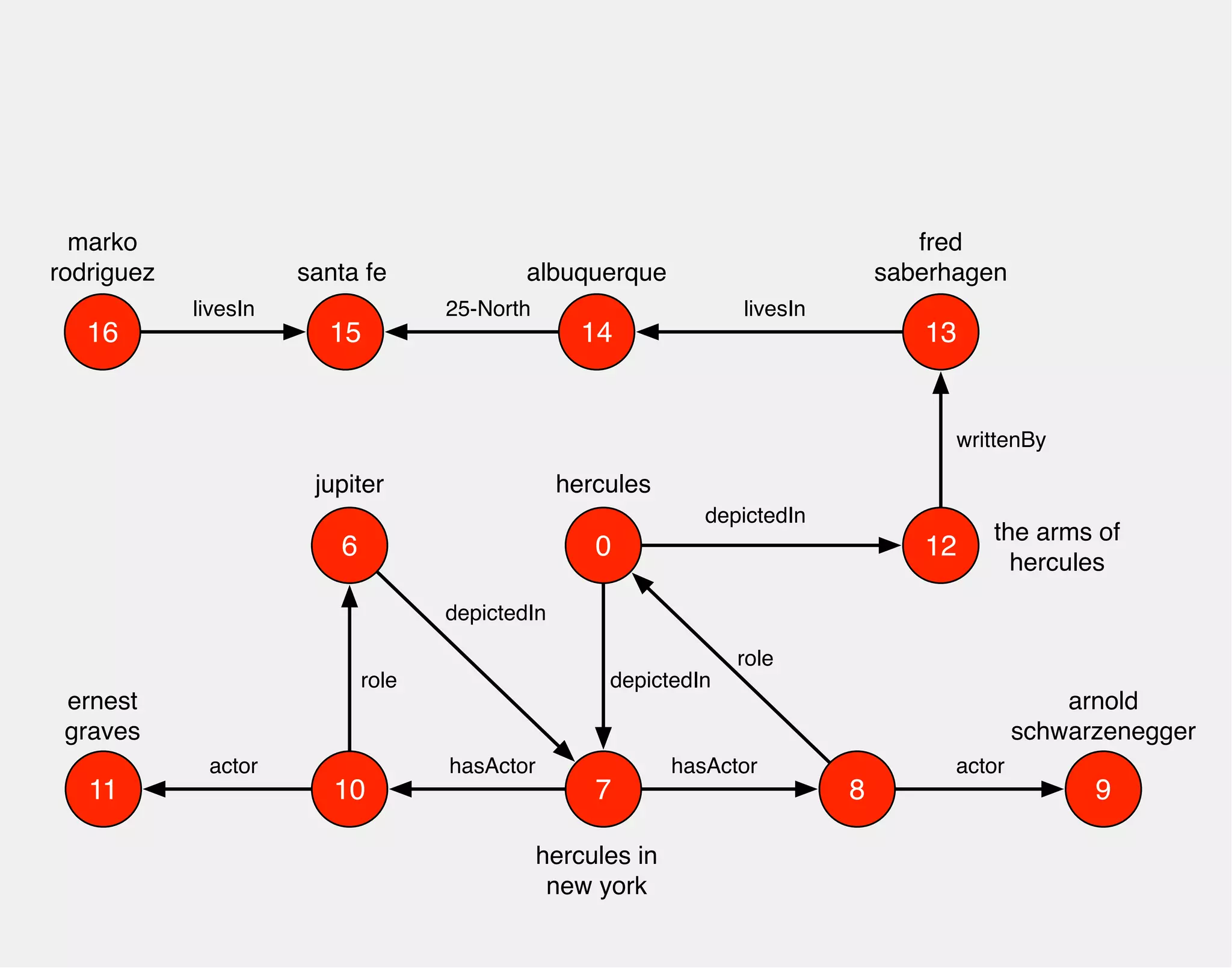
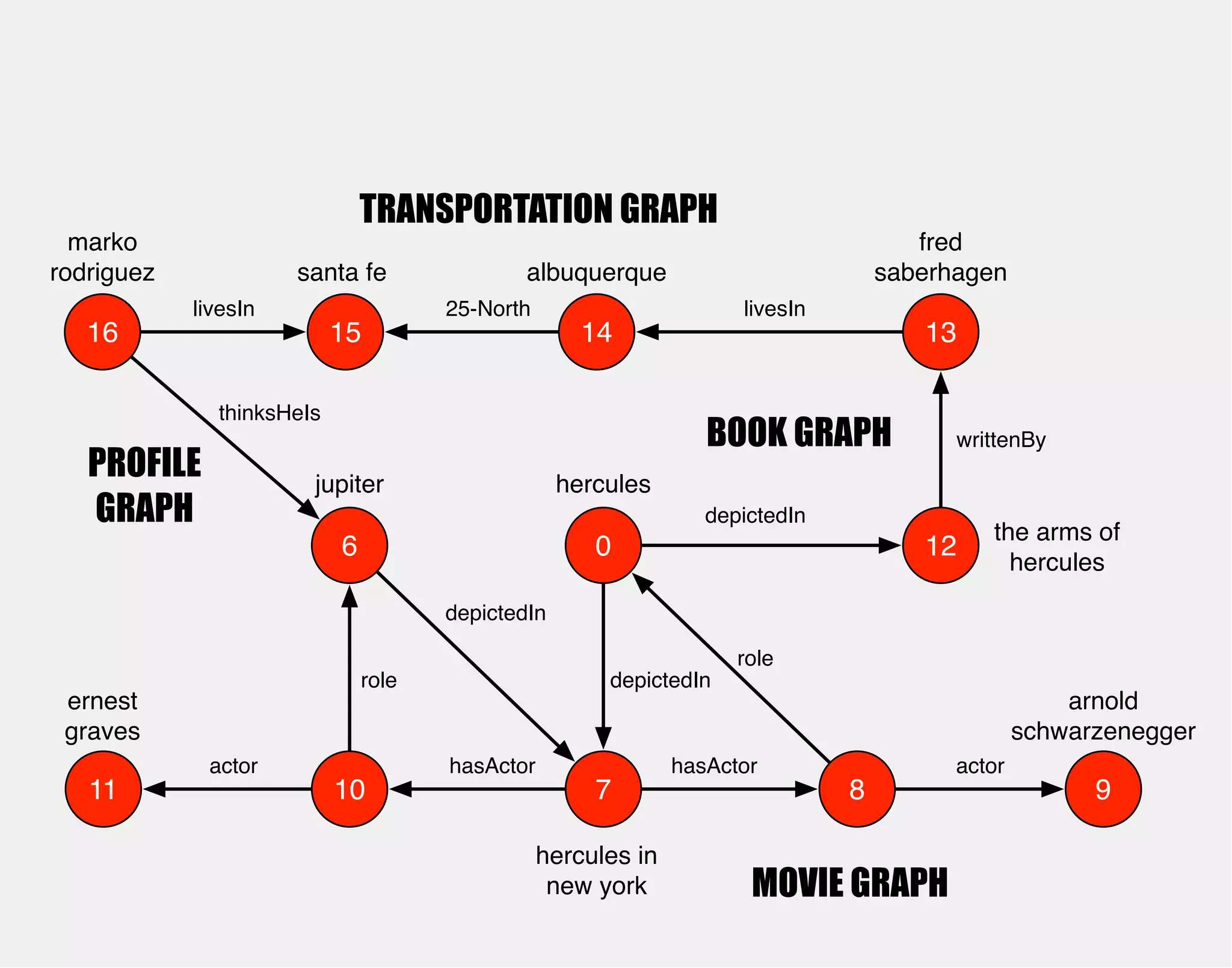
![WHO PLAYED HERCULES
IN WHAT MOVIE?
hercules
0
arnold
schwarzenegger
role
hasActor
jupiter
10 7
8
depictedIn
hercules in
new york
actor
gremlin> hercules.match('hercules',
g.of().as('hercules').out('depictedIn').as('movie'),
g.of().as('movie').out('hasActor').as('actor'),
g.of().as('actor').out('role').as('hercules'),
g.of().as('actor').out('actor').as('star'))
.select(['movie','star'])
==>[movie:v[7], star:v[9]]
9
hasActor
6
role
ernest
graves
actor
11
depictedIn](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-48-2048.jpg)
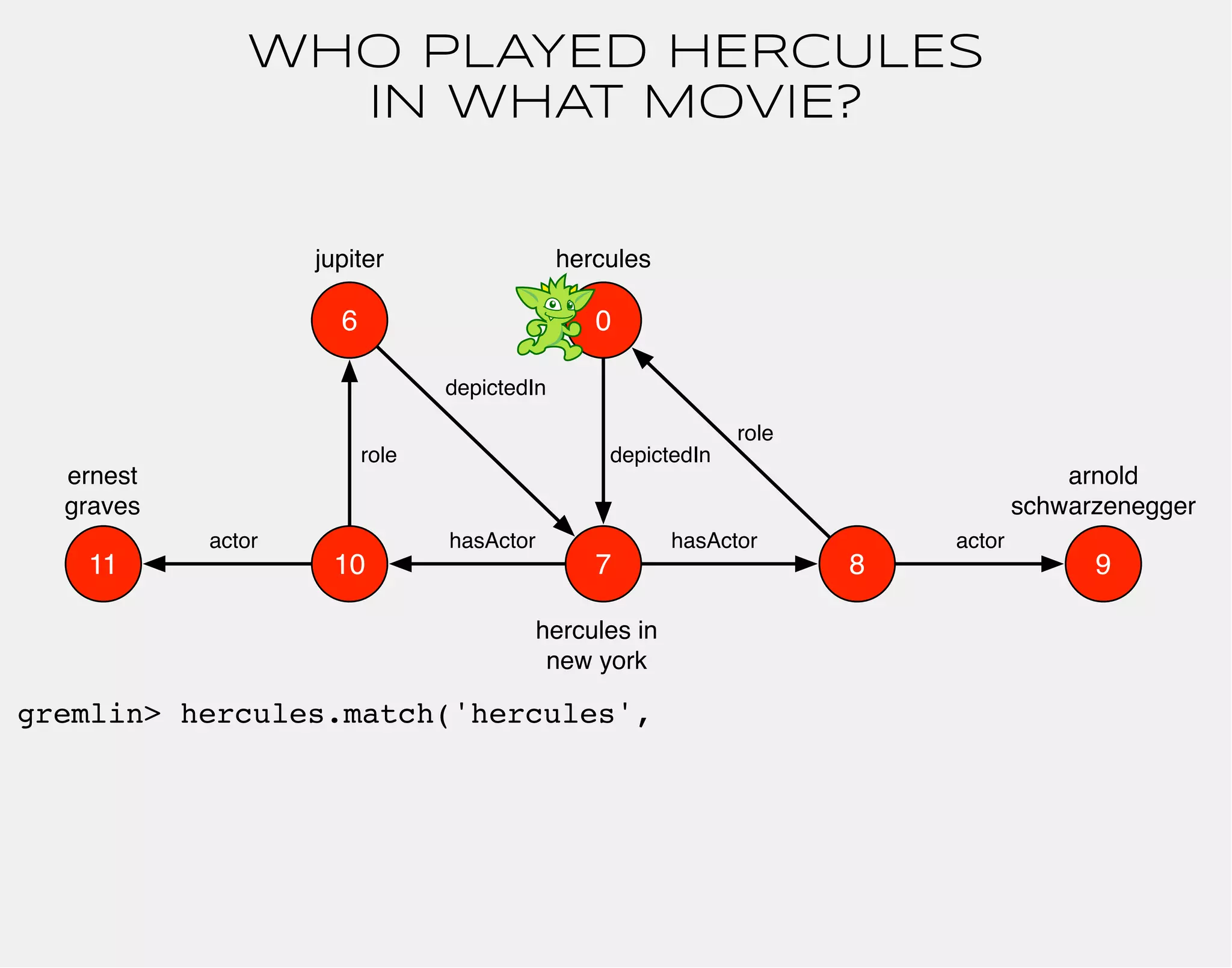
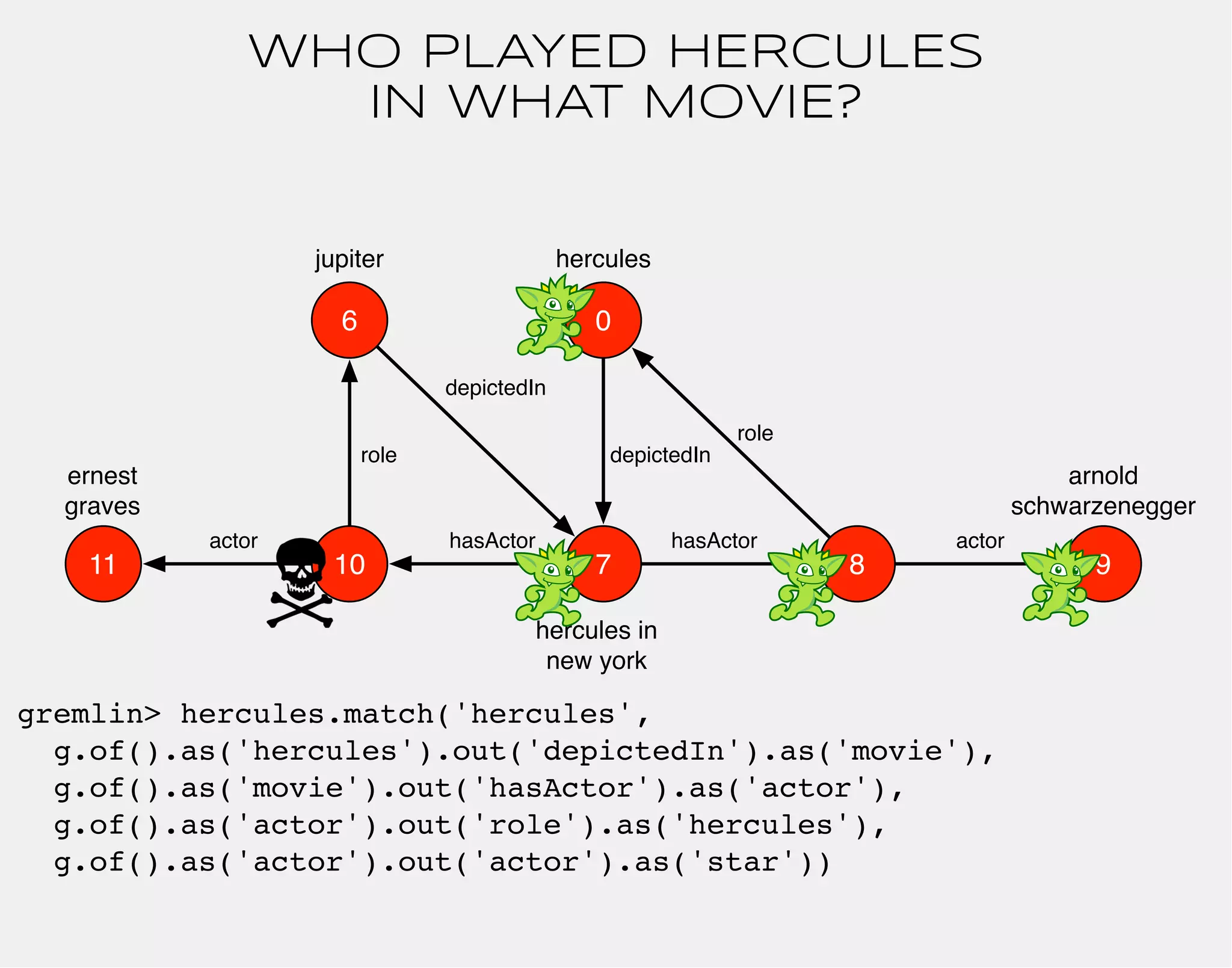
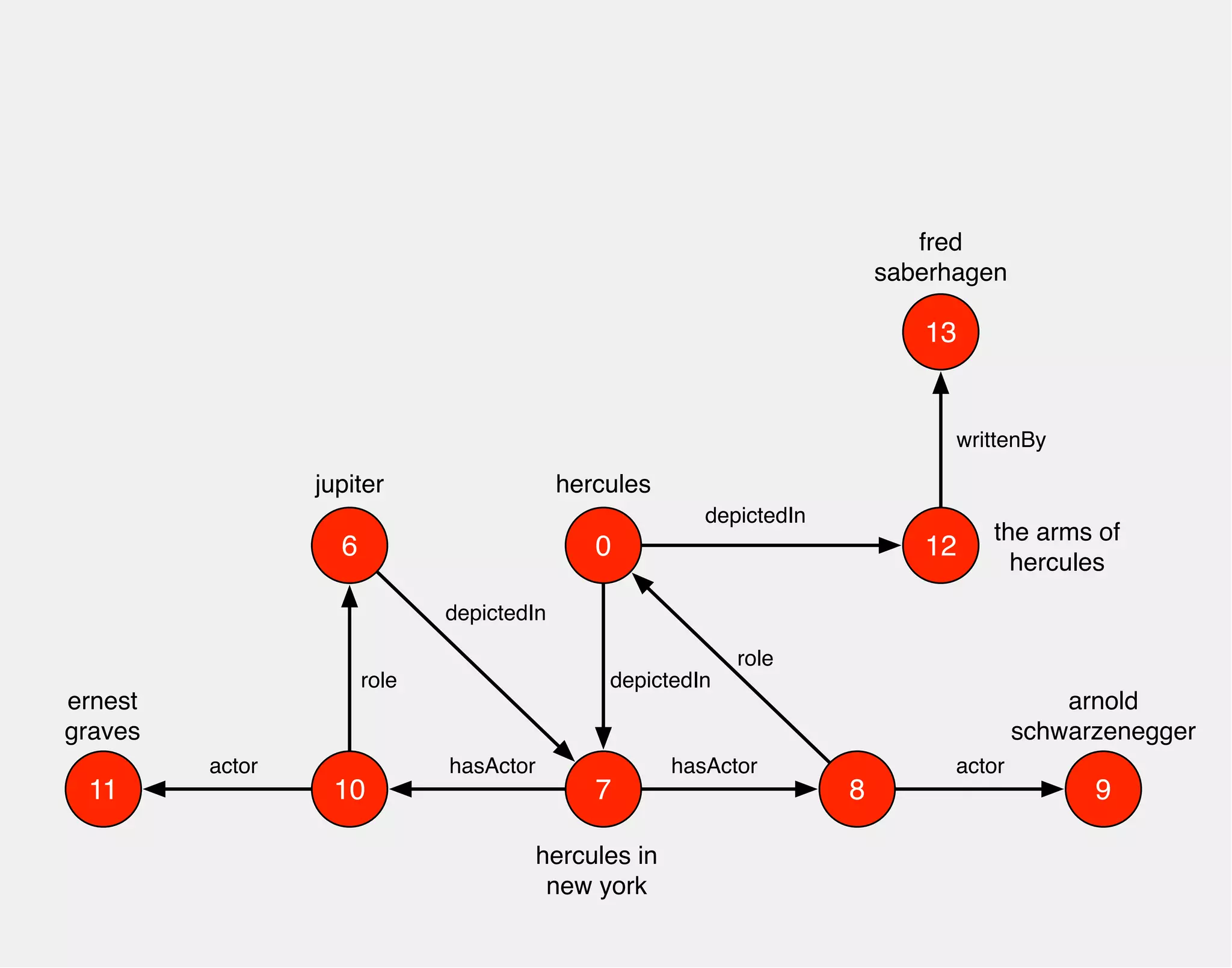
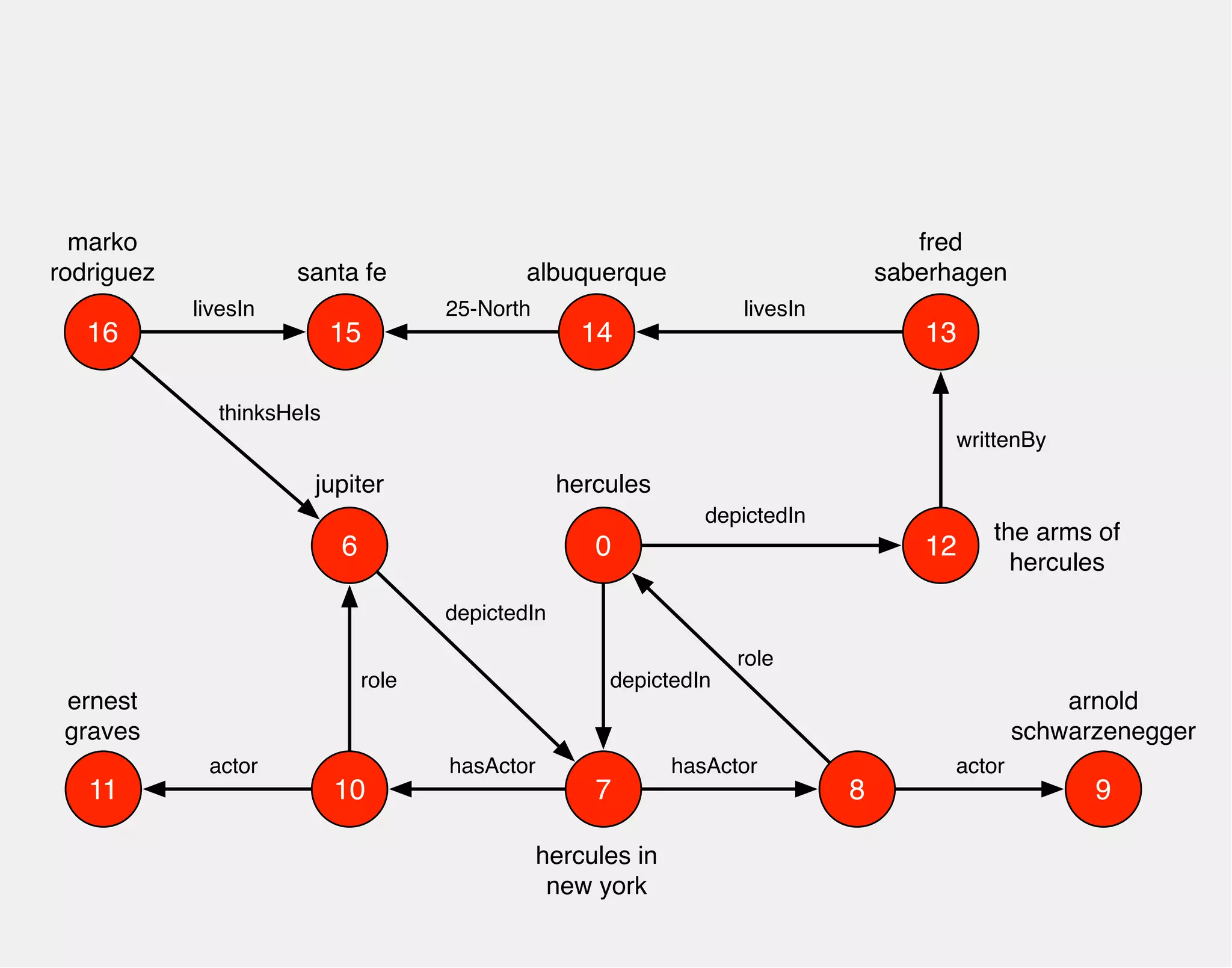
![WHO PLAYED HERCULES
IN WHAT MOVIE?
hercules
0
arnold
schwarzenegger
role
hasActor
jupiter
10 7
8
depictedIn
hercules in
new york
actor
gremlin> hercules.match('hercules',
g.of().as('hercules').out('depictedIn').as('movie')
g.of().as('movie').out('hasActor').as('actor')
g.of().as('actor').out('role').as('hercules')
g.of().as('actor').out('actor').as('star'))
.select(['movie','star']){it.name}
==>[movie:hercules in new york, star:arnold schwarzenegger]
9
hasActor
6
role
ernest
graves
actor
11
depictedIn](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-49-2048.jpg)






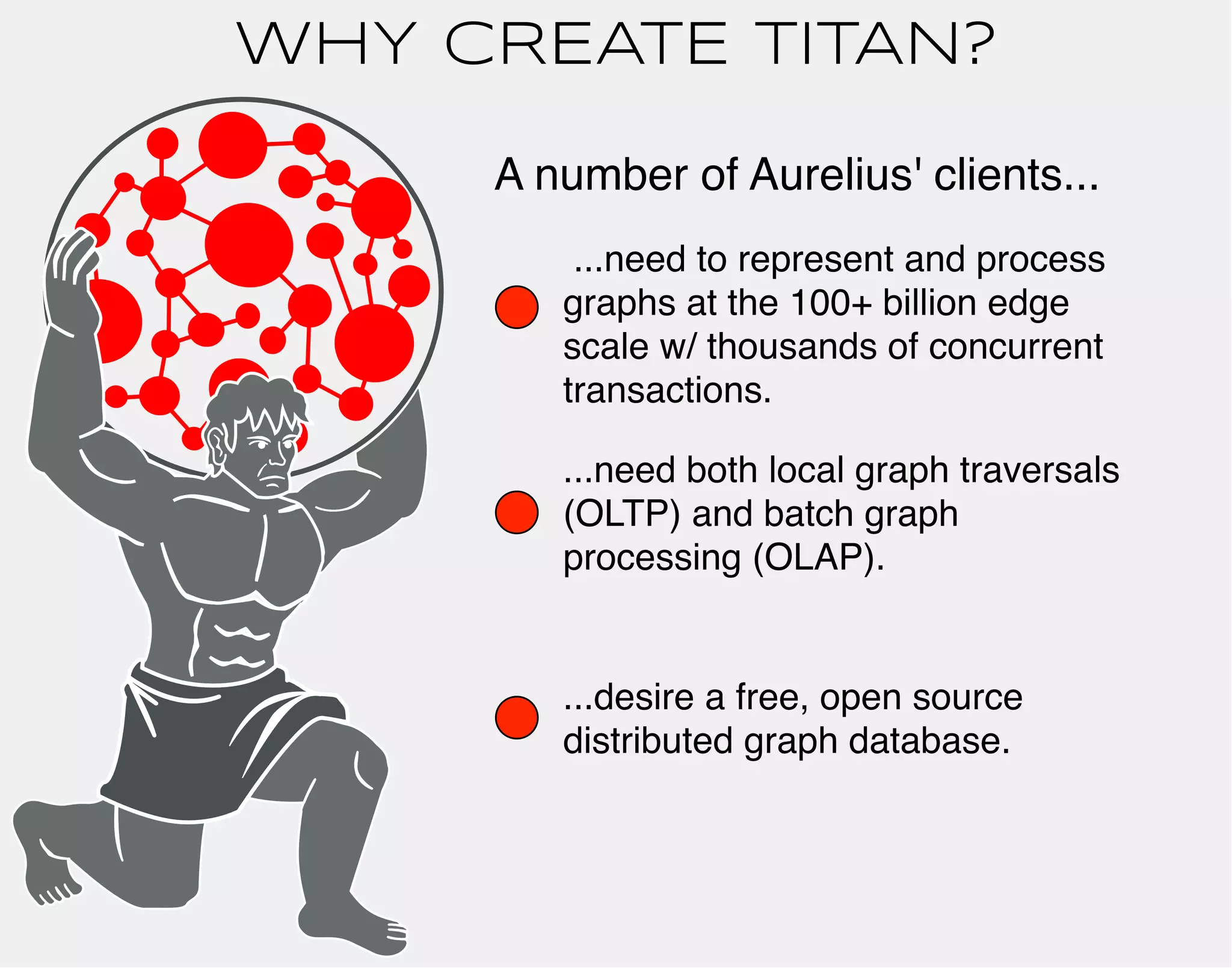
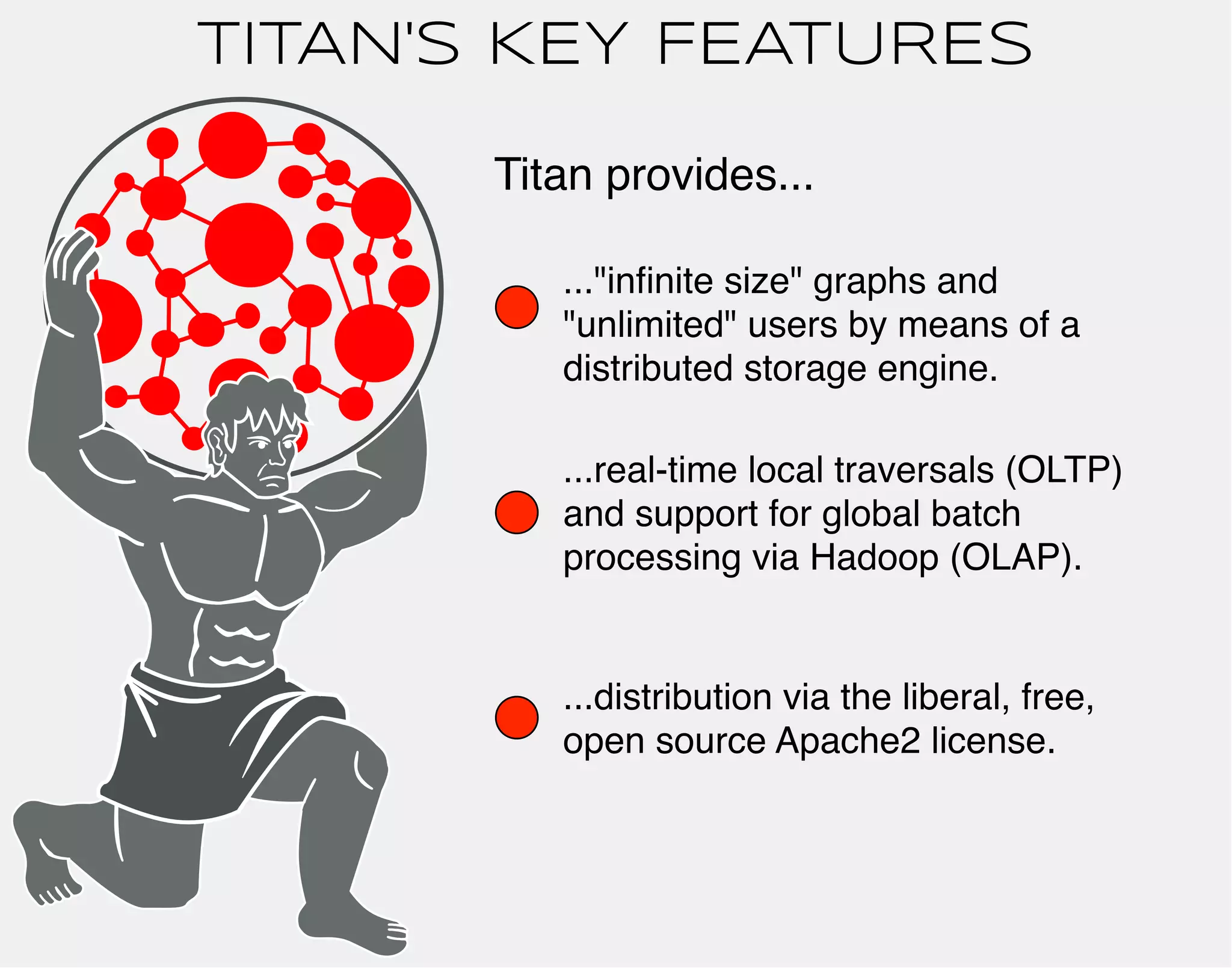

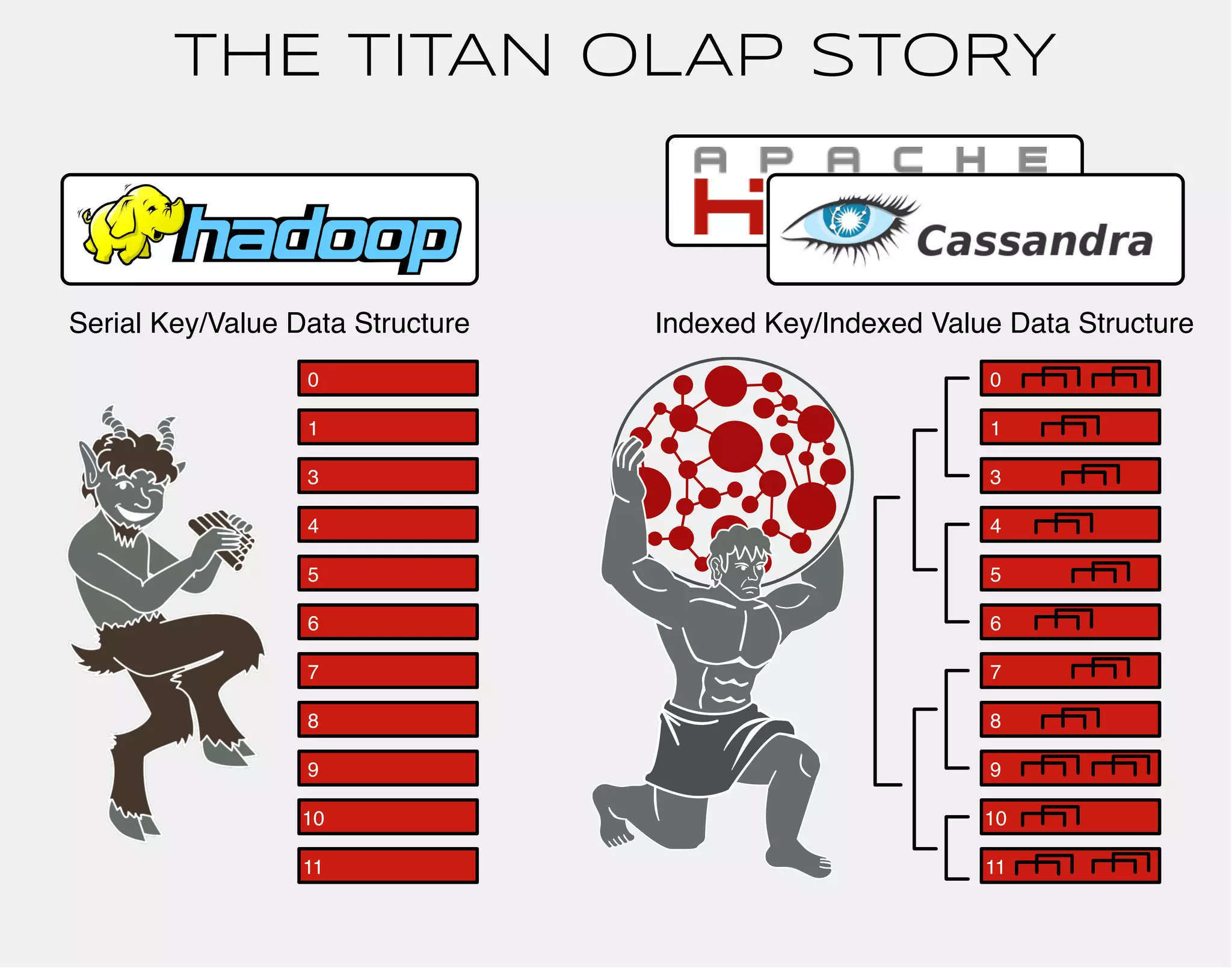
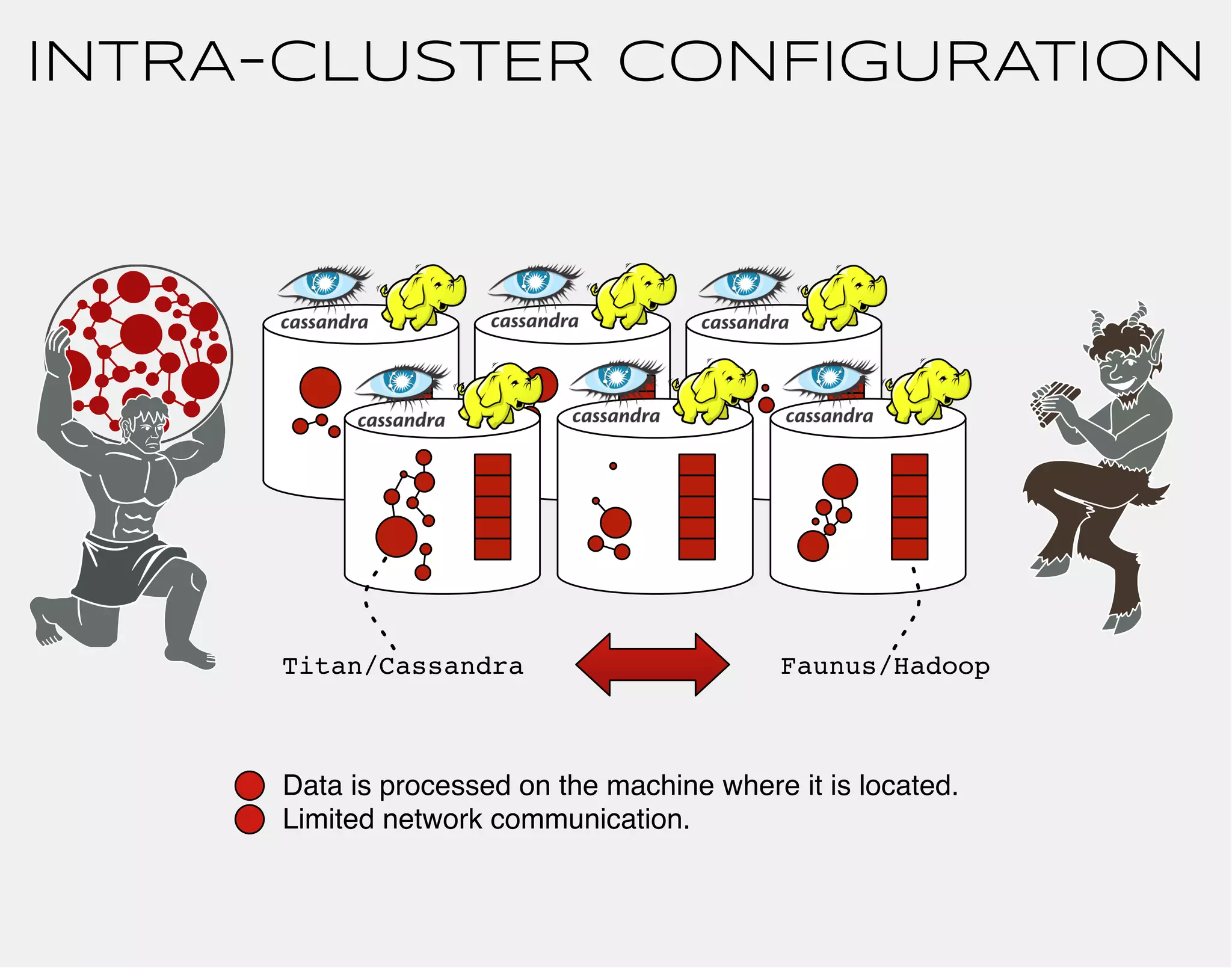
![TITAN DISTRIBUTED
VIA CASSANDRA
titan$ bin/gremlin.sh
,,,/
(o o)
-----oOOo-(_)-oOOo-----
gremlin> conf = new BaseConfiguration();
==>org.apache.commons.configuration.BaseConfiguration@763861e6
gremlin> conf.setProperty("storage.backend","cassandra");
gremlin> conf.setProperty("storage.hostname","77.77.77.77");
gremlin> g = TitanFactory.open(conf);
==>titangraph[cassandra:77.77.77.77]
gremlin>](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-70-2048.jpg)

![TITAN DISTRIBUTED
titan$ bin/gremlin.sh
,,,/
(o o)
VIA HBASE
-----oOOo-(_)-oOOo-----
gremlin> conf = new BaseConfiguration();
==>org.apache.commons.configuration.BaseConfiguration@763861e6
gremlin> conf.setProperty("storage.backend","hbase");
gremlin> conf.setProperty("storage.hostname","77.77.77.77");
gremlin> g = TitanFactory.open(conf);
==>titangraph[hbase:77.77.77.77]
gremlin>](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-72-2048.jpg)




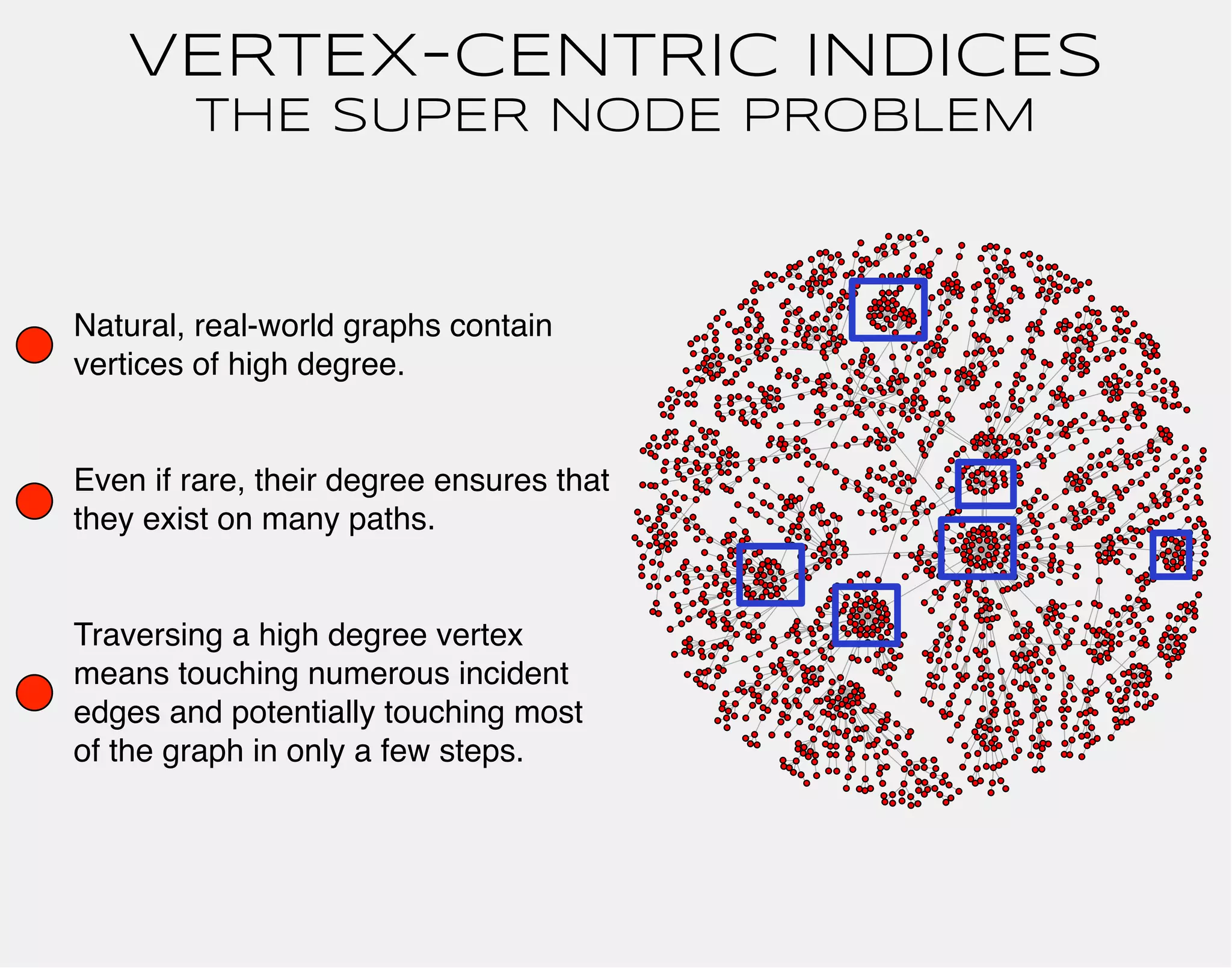

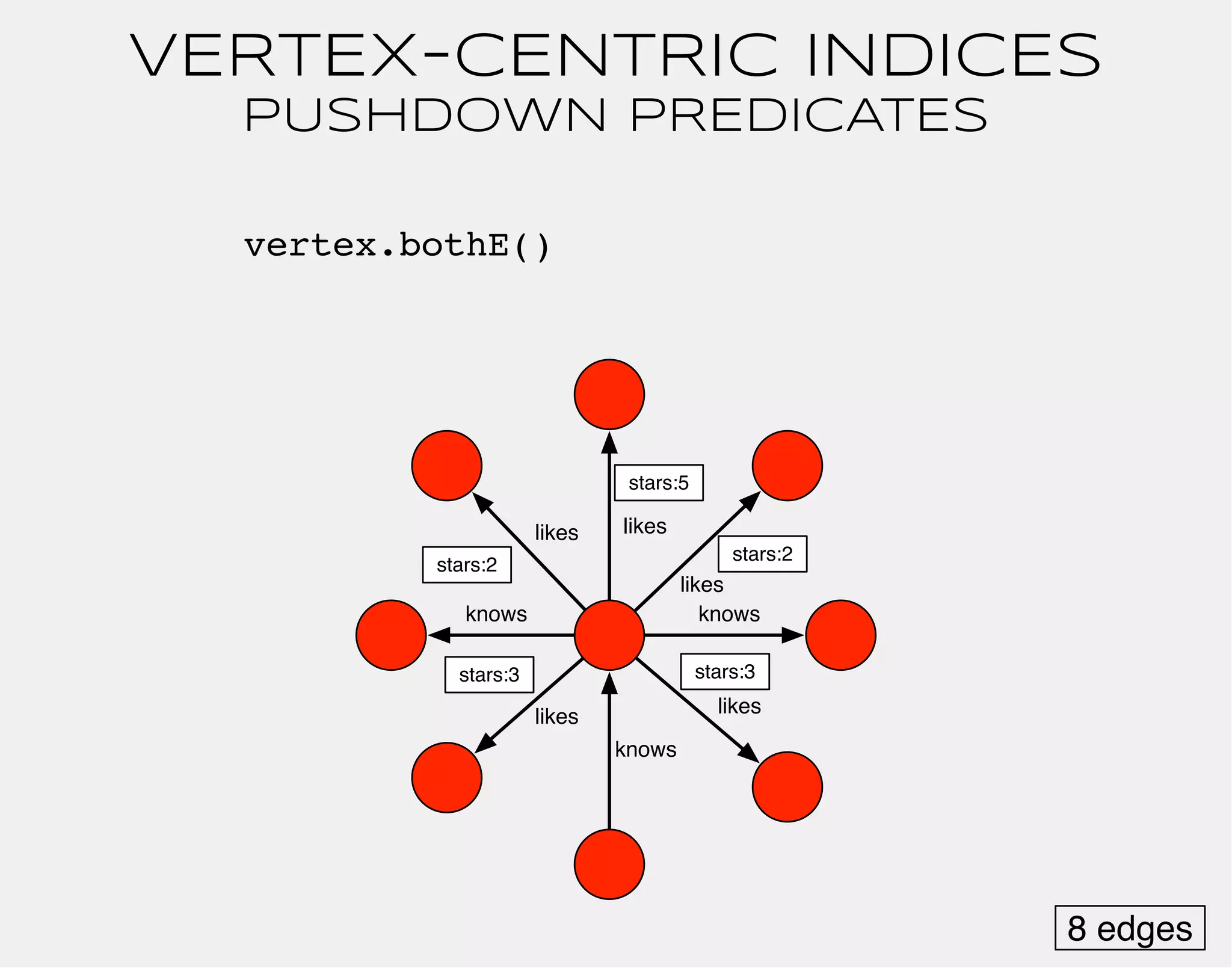
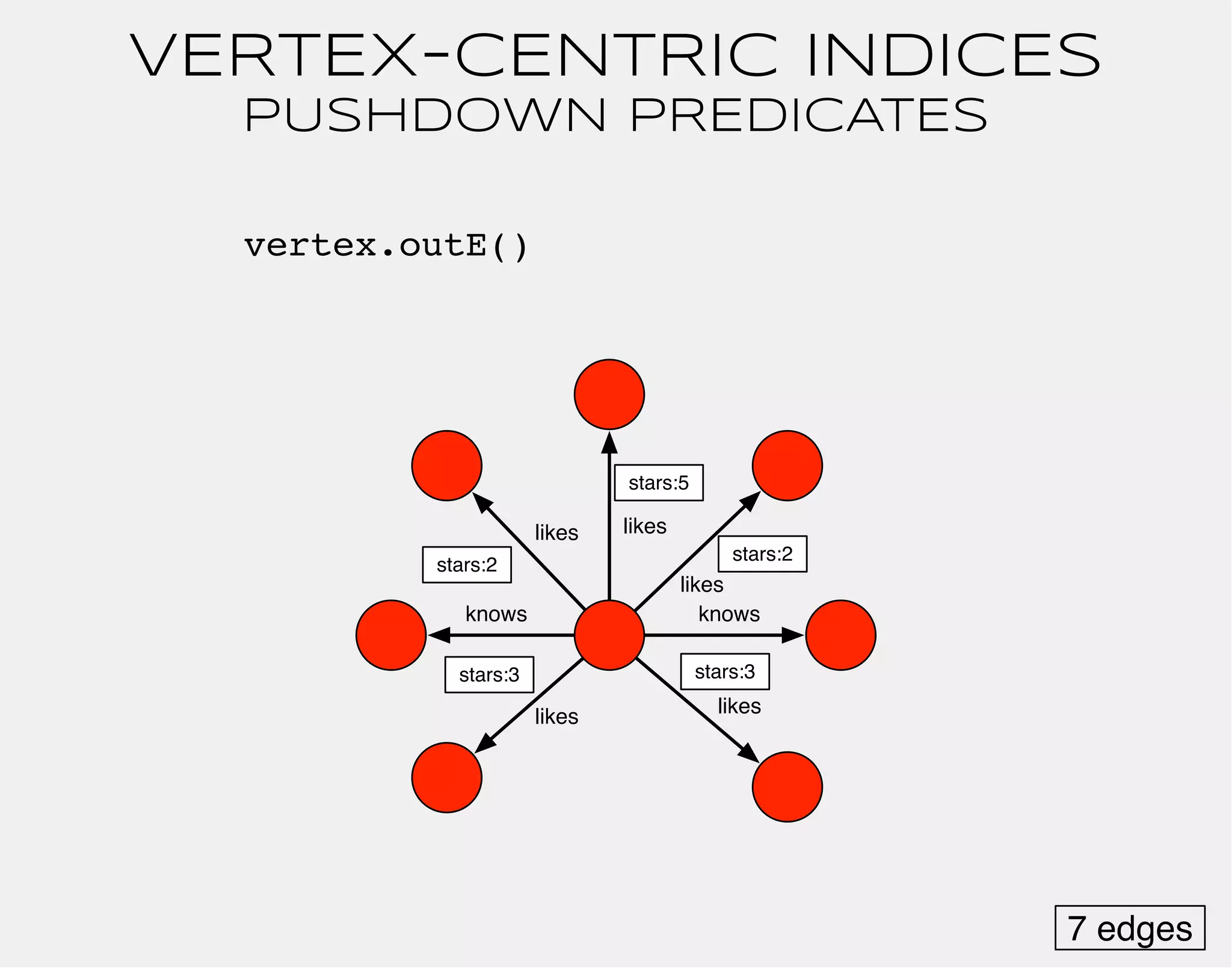
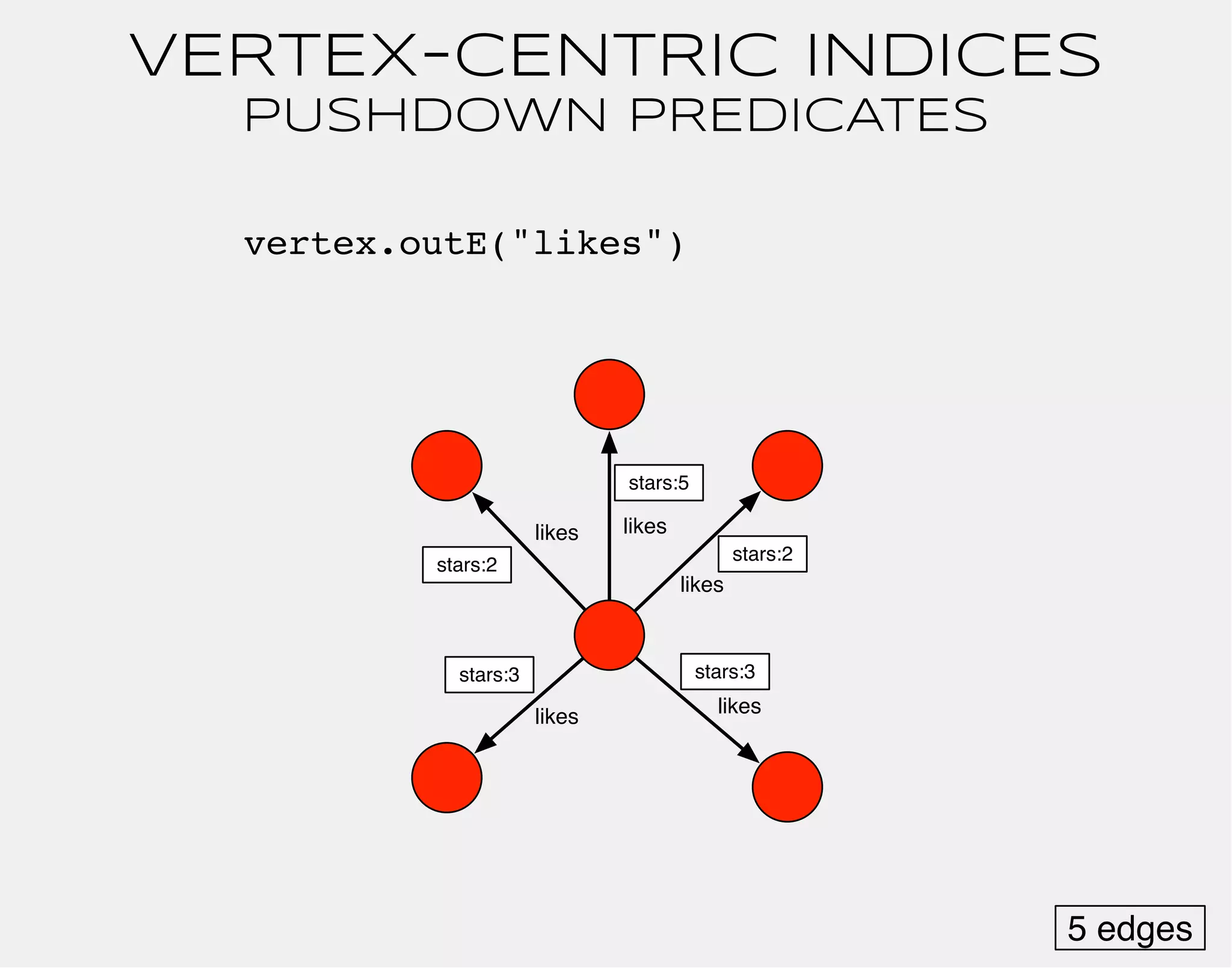













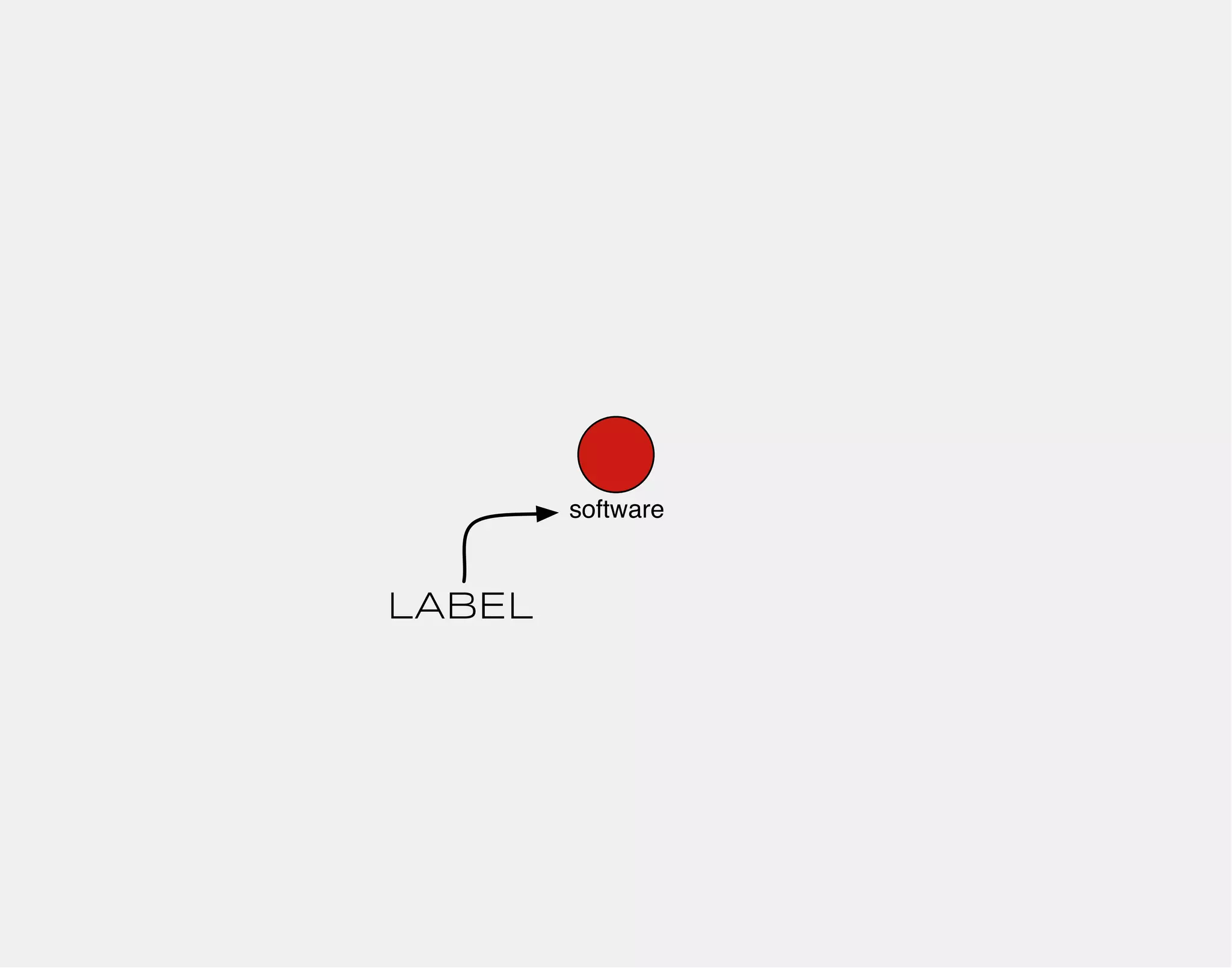
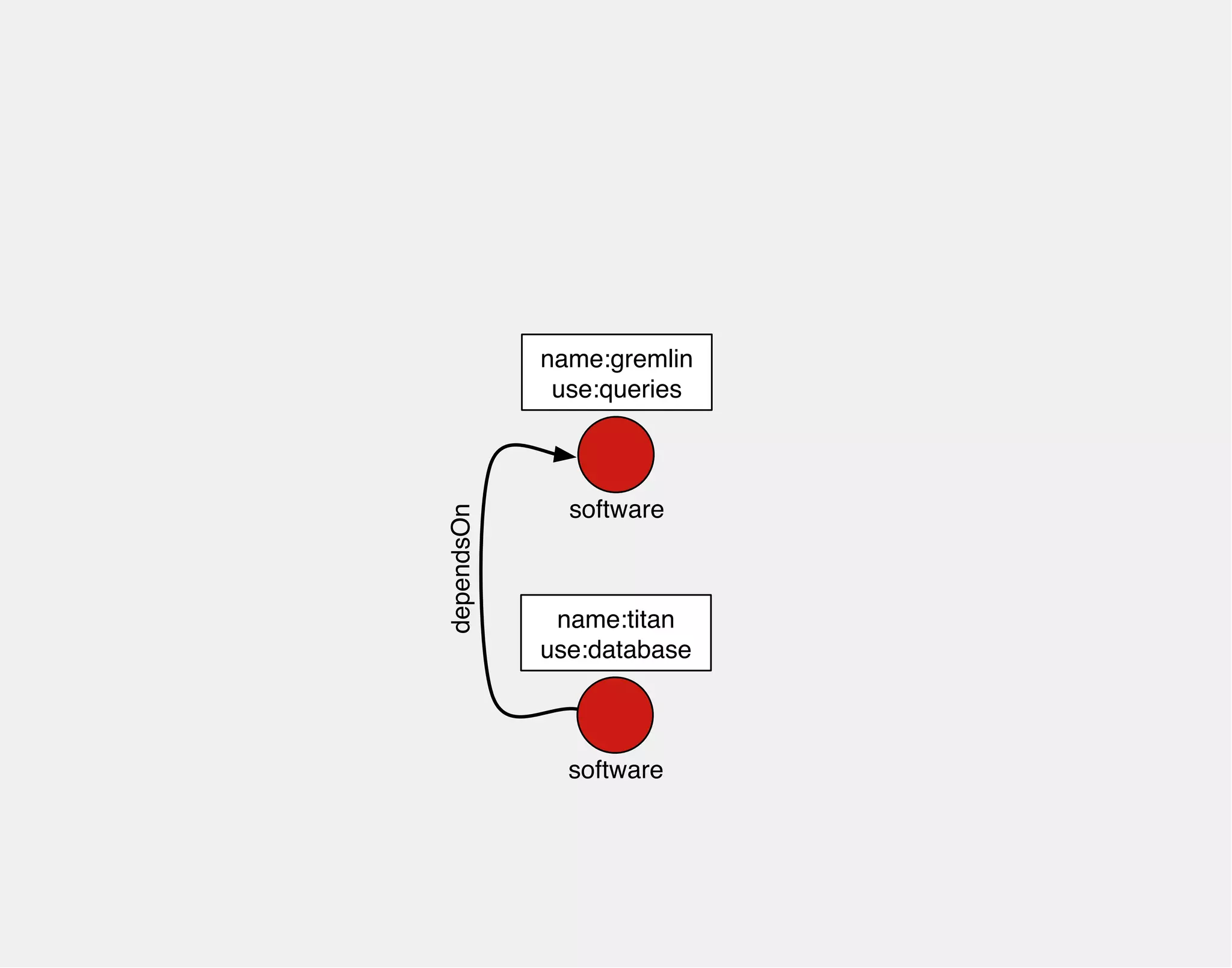
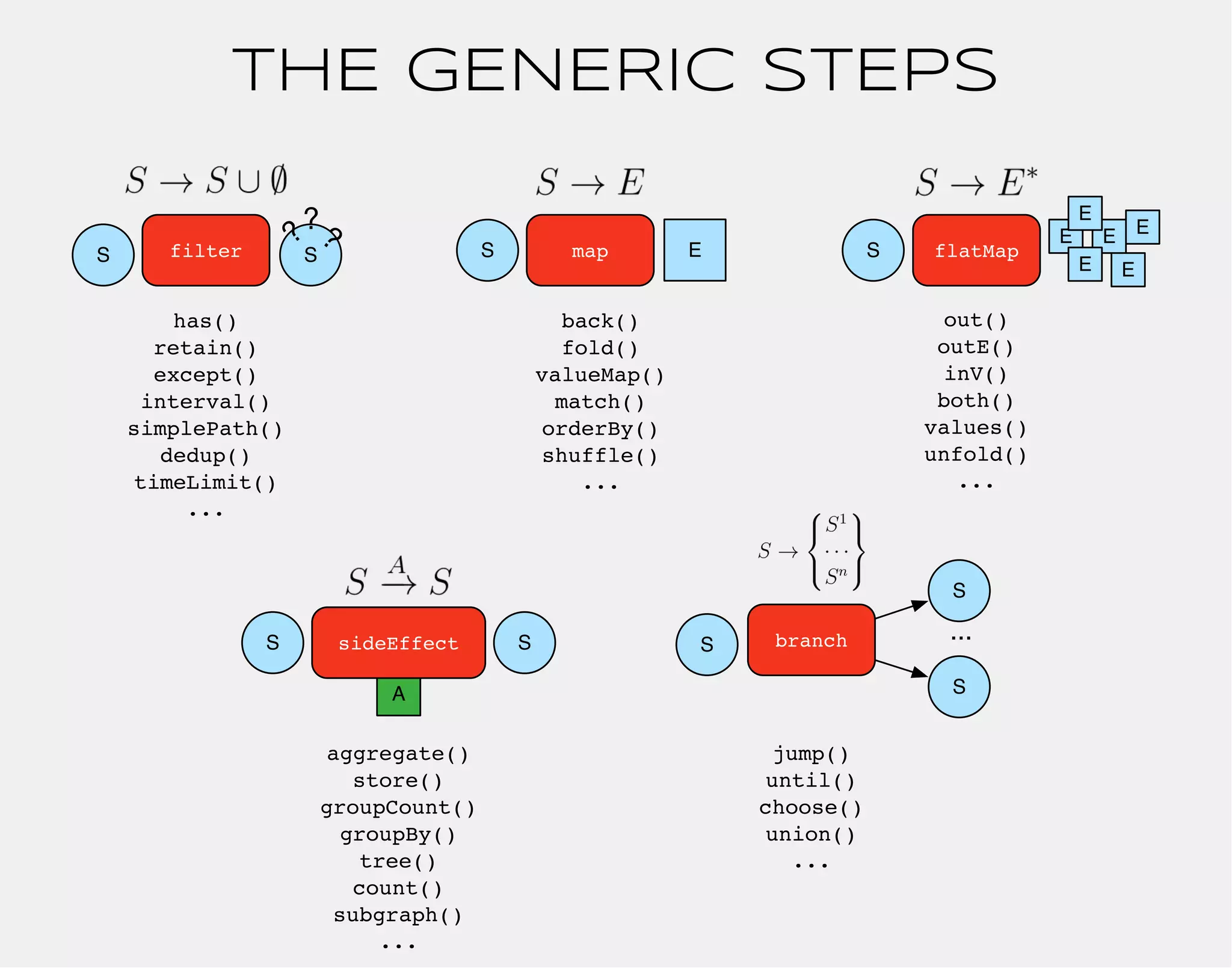
![gremlin> gremlin = g.addVertex(label,'software','name','gremlin')
==>v[0]
name:gremlin
0
software](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-102-2048.jpg)
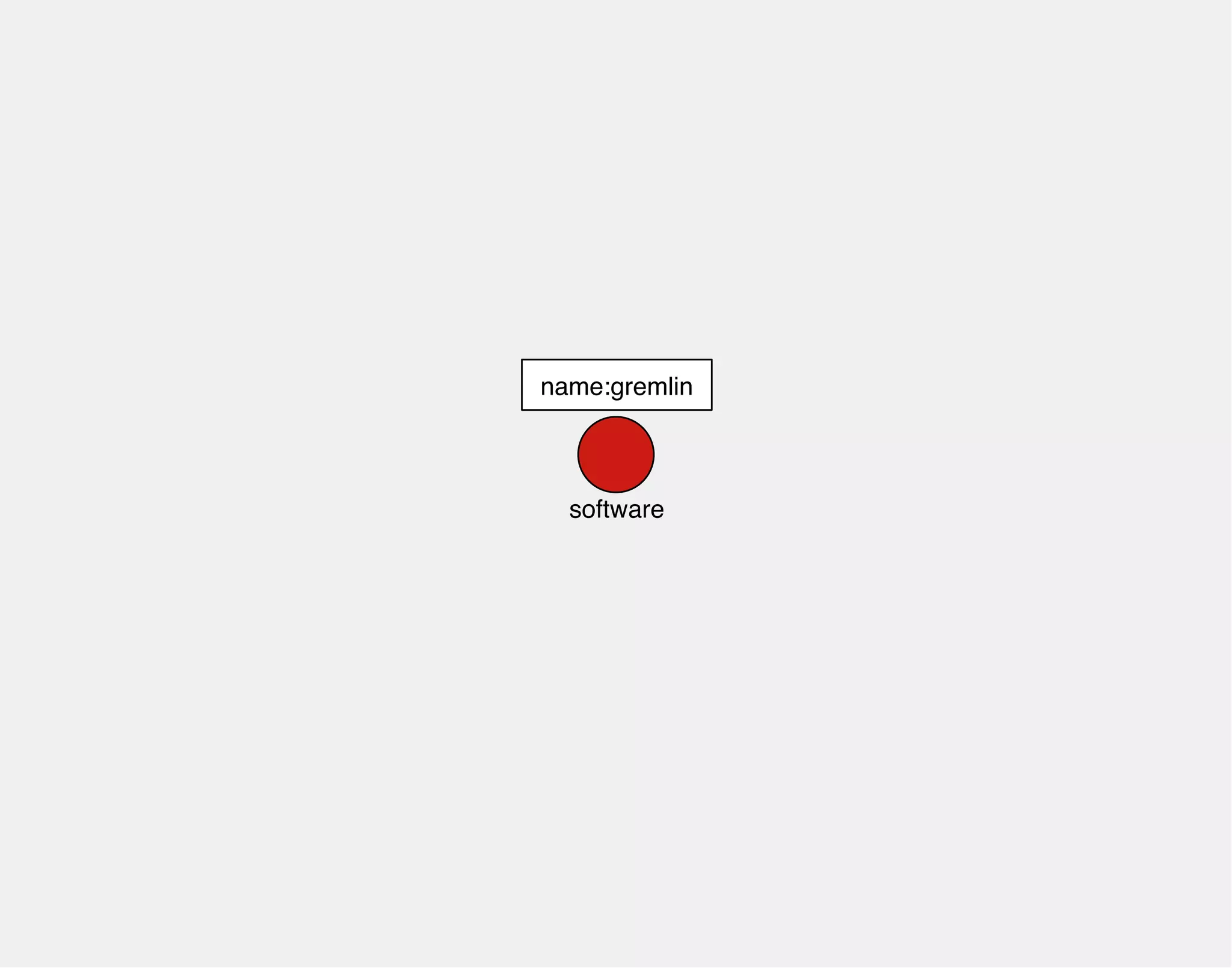
![gremlin> gremlin = g.addVertex(label,'software','name','gremlin')
==>v[0]
gremlin> titan = g.addVertex(label,'software','name','titan')
==>v[2]
name:titan name:gremlin
0
software
2
software](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-103-2048.jpg)
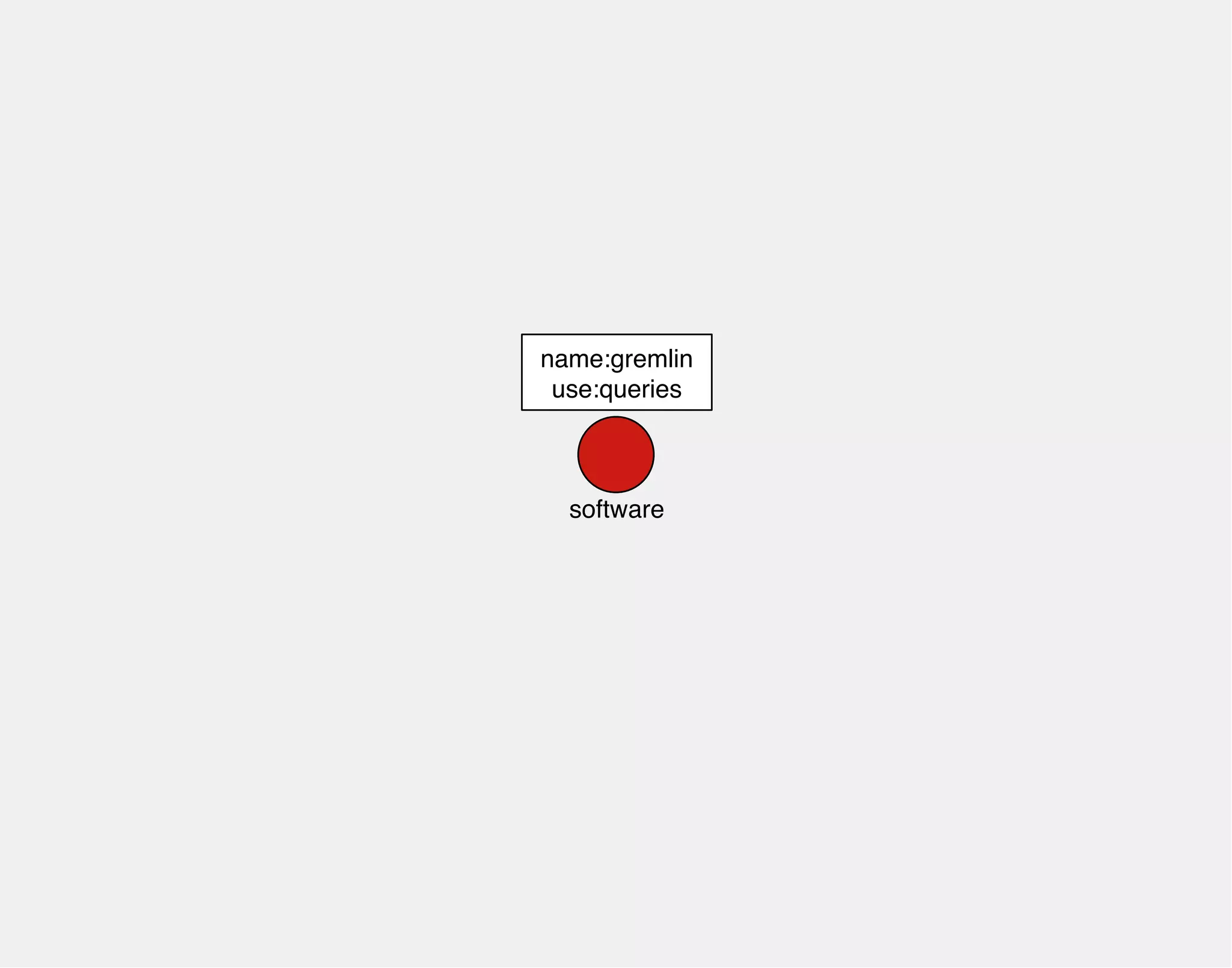
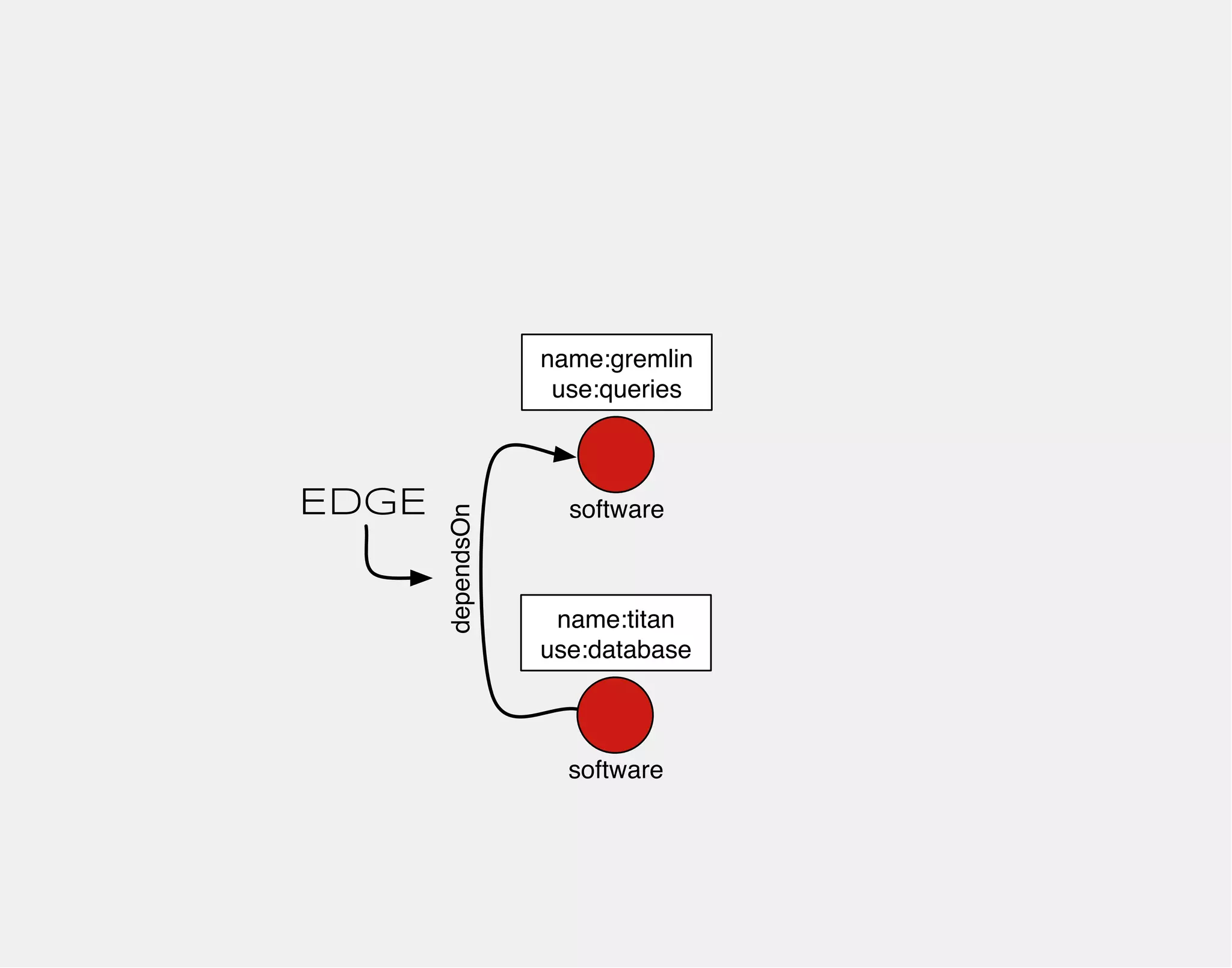
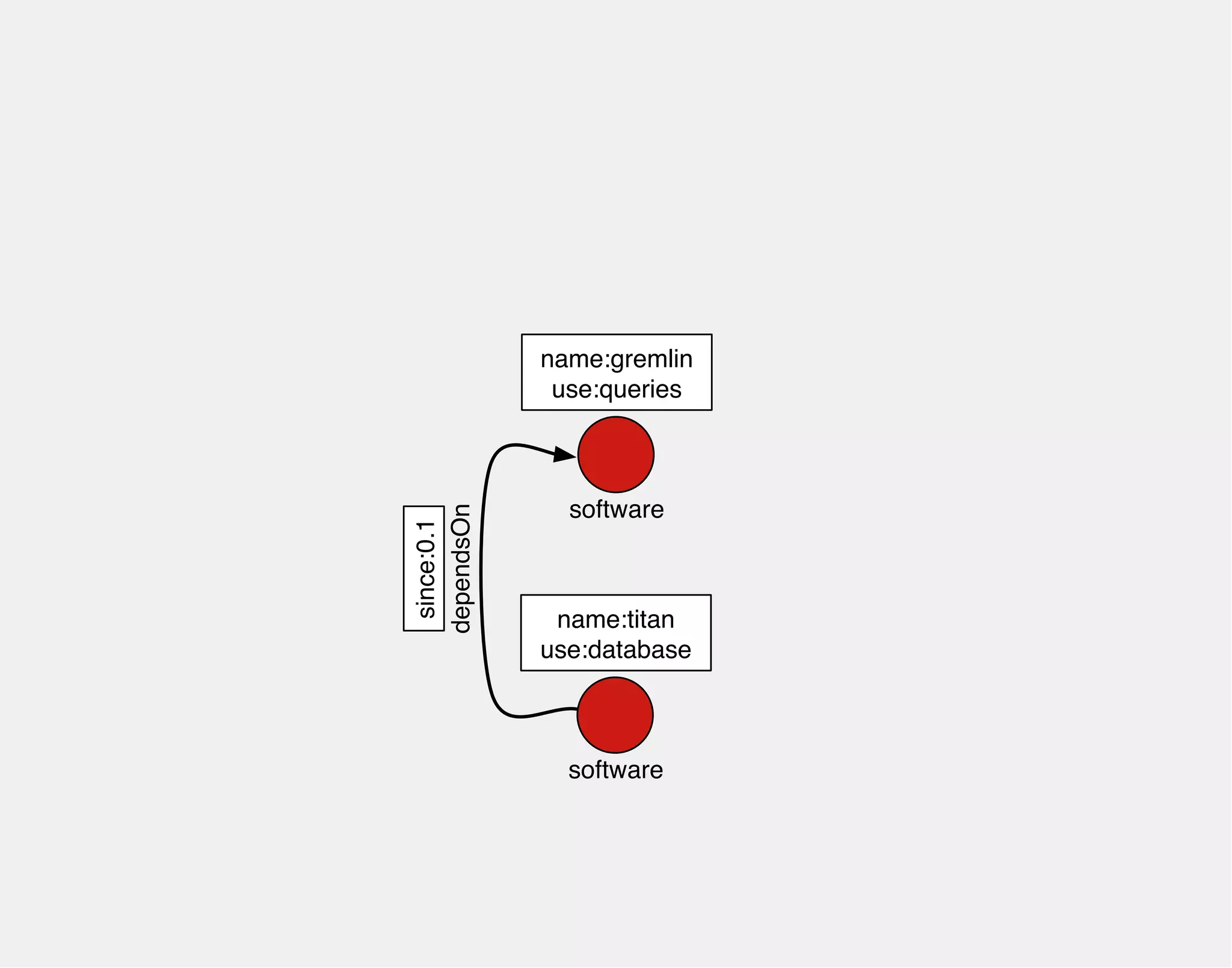
![gremlin> gremlin = g.addVertex(label,'software','name','gremlin')
==>v[0]
gremlin> titan = g.addVertex(label,'software','name','titan')
==>v[2]
gremlin> titan.addEdge('dependsOn',gremlin,'since','0.1')
==>e[4][2-dependsOn->0]
name:titan name:gremlin
0
software
2
software
dependsOn
since:0.1](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-104-2048.jpg)
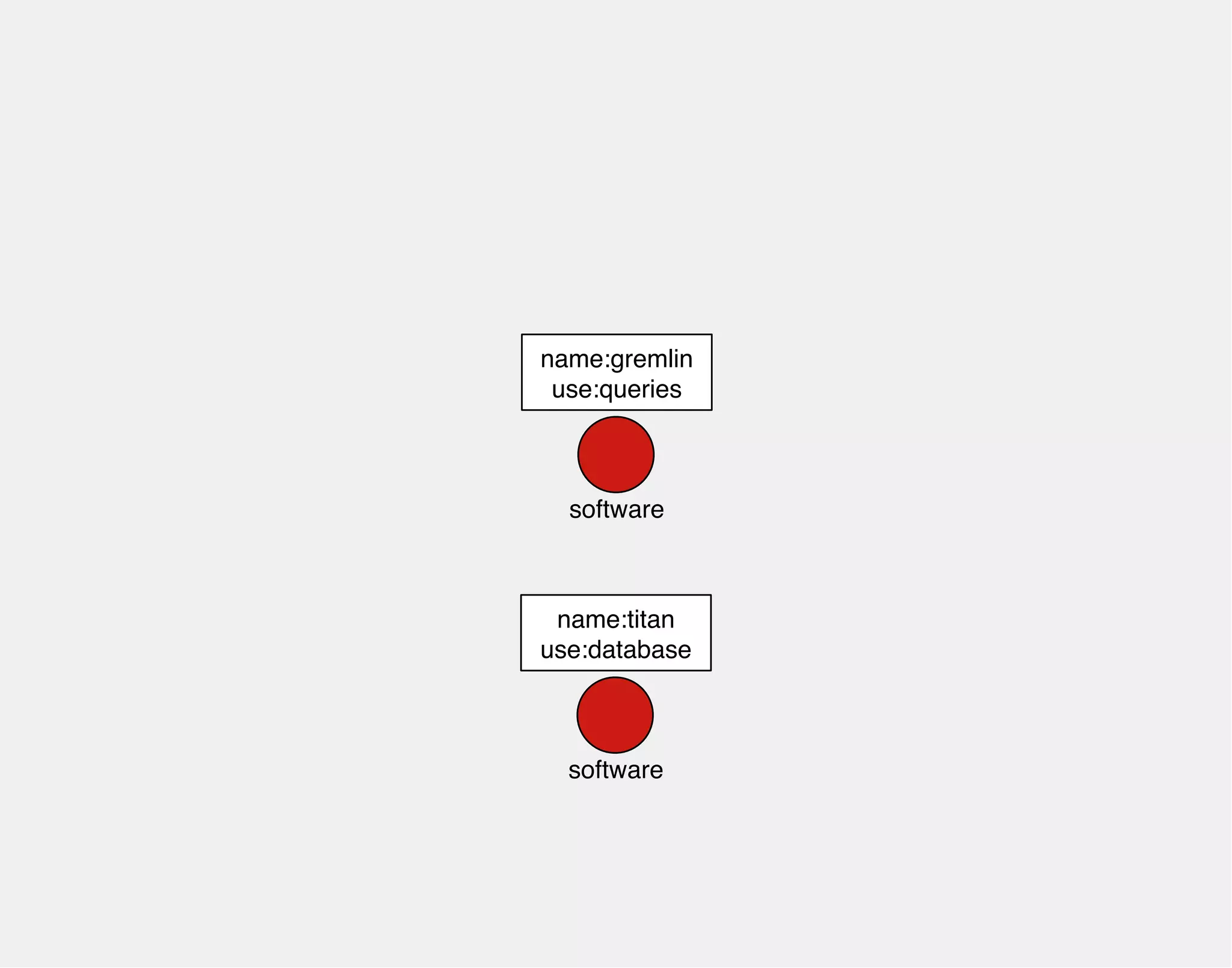
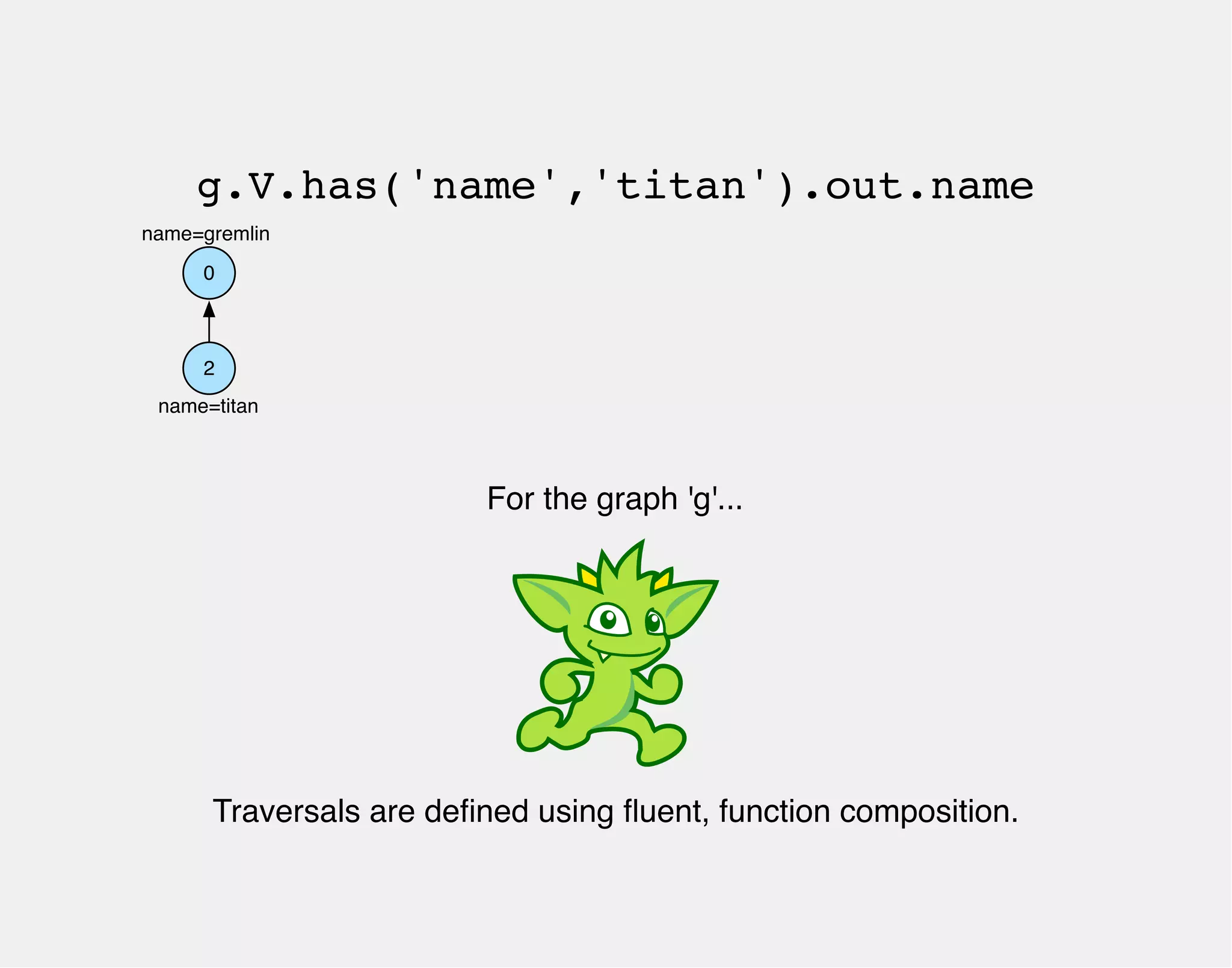
![Gremlin is a style of graph traversal that is
heavily influenced by functional programming.
gremlin> gremlin = g.addVertex(label,'software','name','gremlin')
==>v[0]
gremlin> titan = g.addVertex(label,'software','name','titan')
==>v[2]
gremlin> titan.addEdge('dependsOn',gremlin,'since','0.1')
==>e[4][2-dependsOn->0]
//////////////////////////////////////////////////////////////////
gremlin> g.V
==>v[0]
==>v[2]
gremlin> g.V.has('name','titan')
==>v[2]
gremlin> g.V.has('name','titan').outE
==>e[4][2-dependsOn->0]
gremlin> g.V.has('name','titan').outE.since
==>0.1
gremlin> g.V.has('name','titan').out.name
==>gremlin](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-105-2048.jpg)





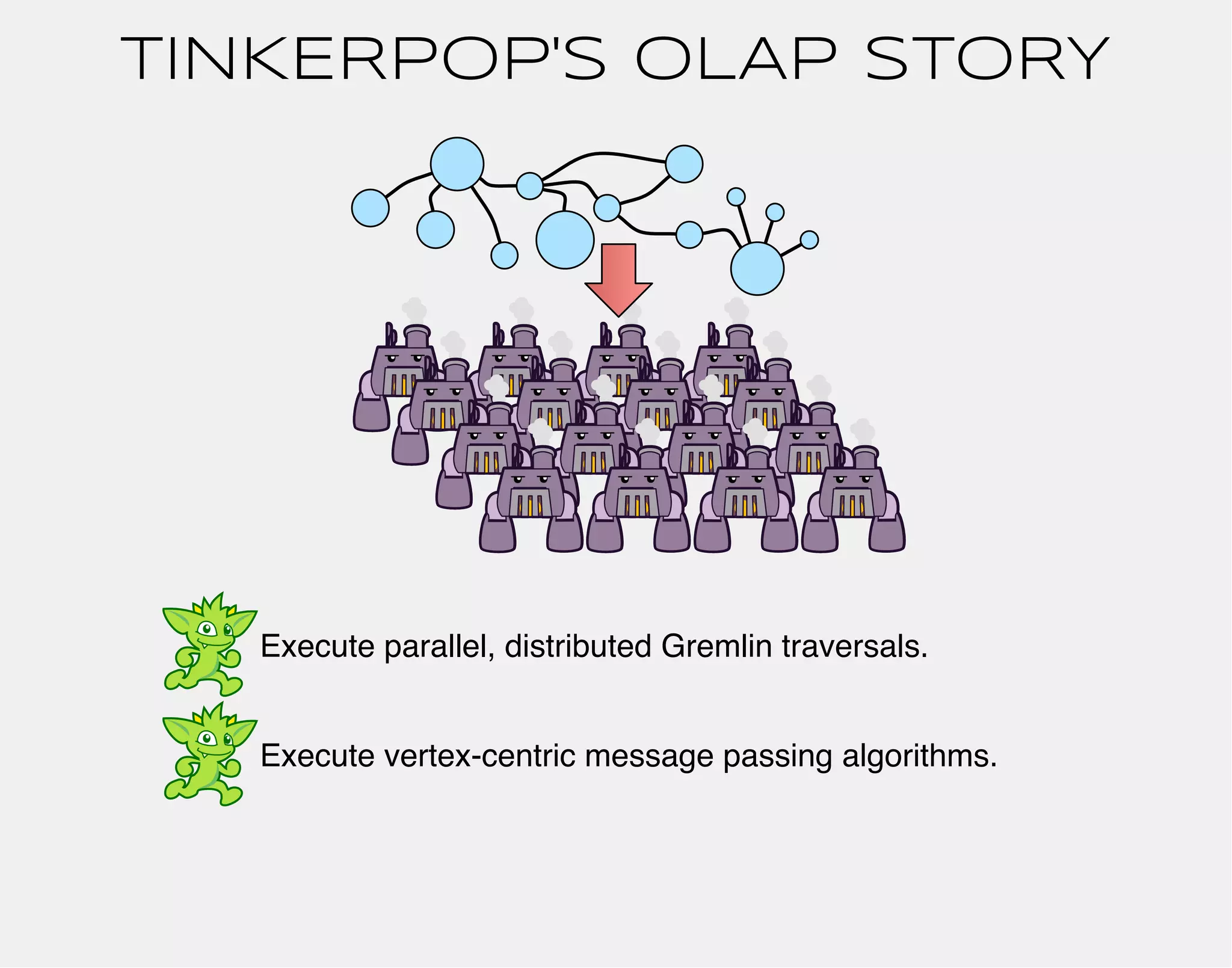

![gremlin> result = g.compute().program(PageRankVertexProgram).submit()
==>result[tinkergraph[vertices:6 edges:6],memory[size:0]]
gremlin> result.memory.iteration
==>30
gremlin> result.graph
==>tinkergraph[vertices:6 edges:6]
gremlin> result.graph.V.map{ [it.id,it.pageRank]}
==>[1, 0.15000000000000002]
==>[2, 0.19250000000000003]
==>[3, 0.4018125]
==>[4, 0.19250000000000003]
==>[5, 0.23181250000000003]
==>[6, 0.15000000000000002]
* Minor tweaks to example to make it fit nicely on a single line.](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-117-2048.jpg)
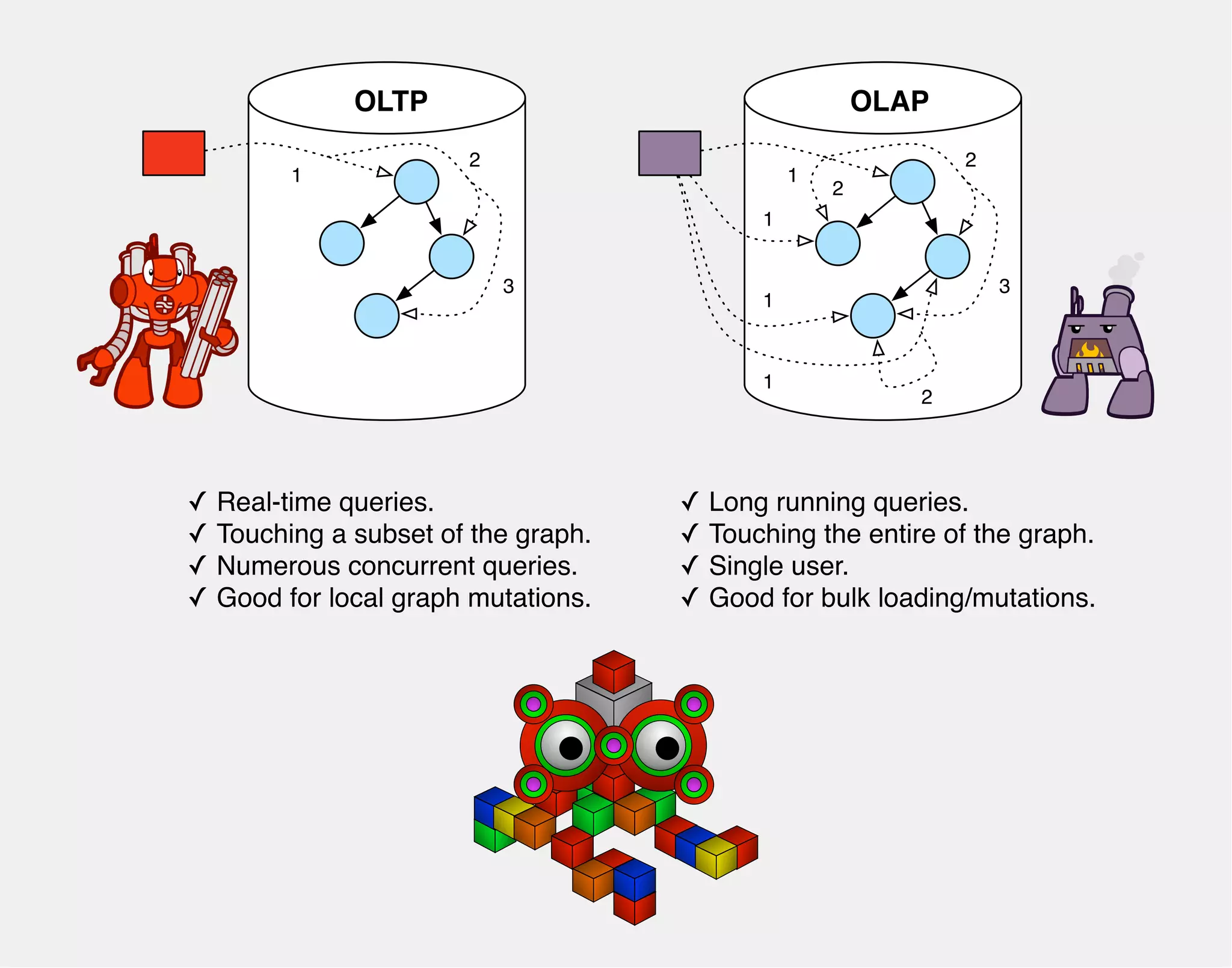
![gremlin> g.V.both.both.name.groupCount()
==>[ripple:3, peter:3, vadas:3, josh:7, lop:7, marko:7]
gremlin> g.V.both.both.name.groupCount().submit(g.compute())
==>[ripple:3, peter:3, vadas:3, josh:7, lop:7, marko:7]
OLTP
OLAP](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-118-2048.jpg)
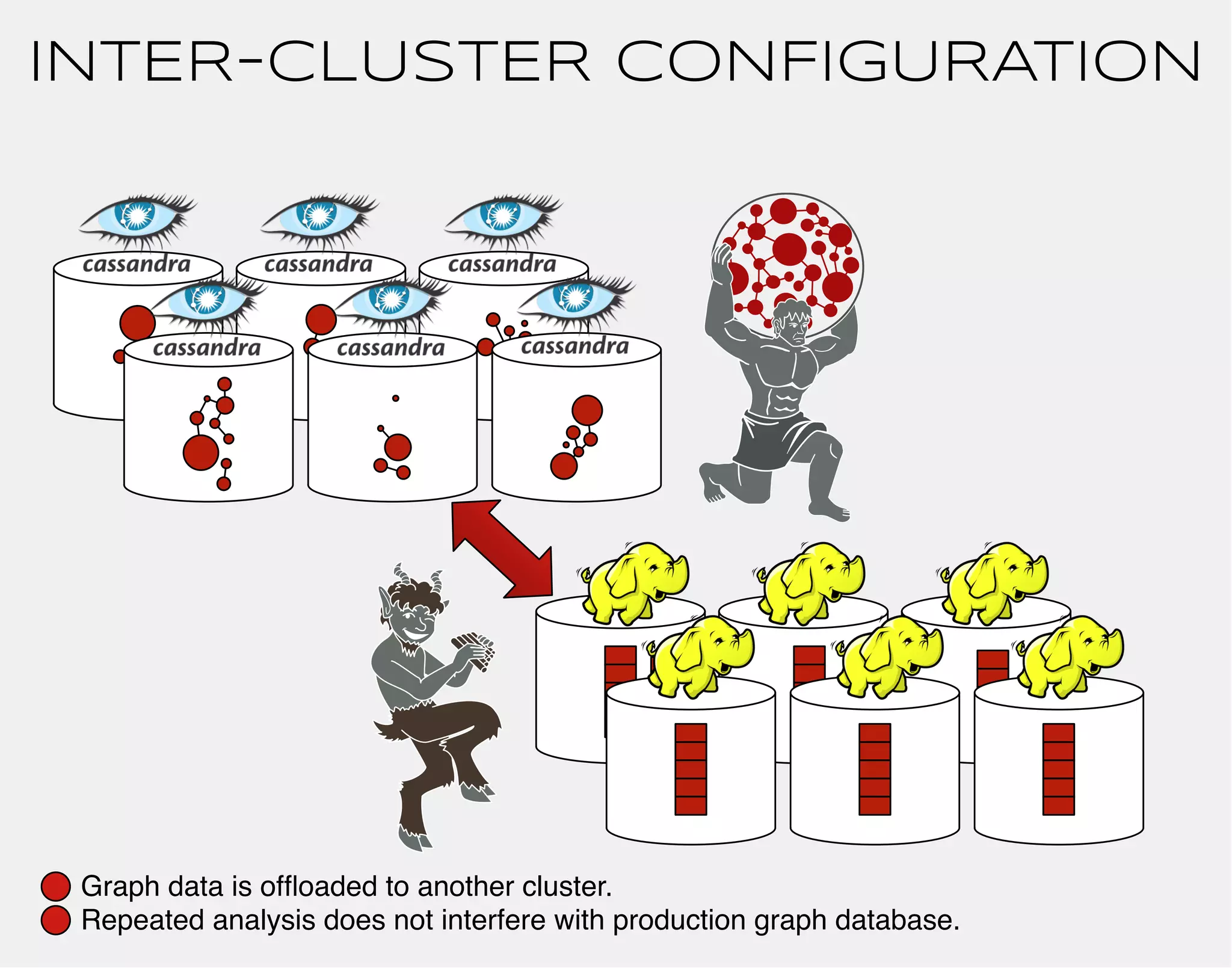
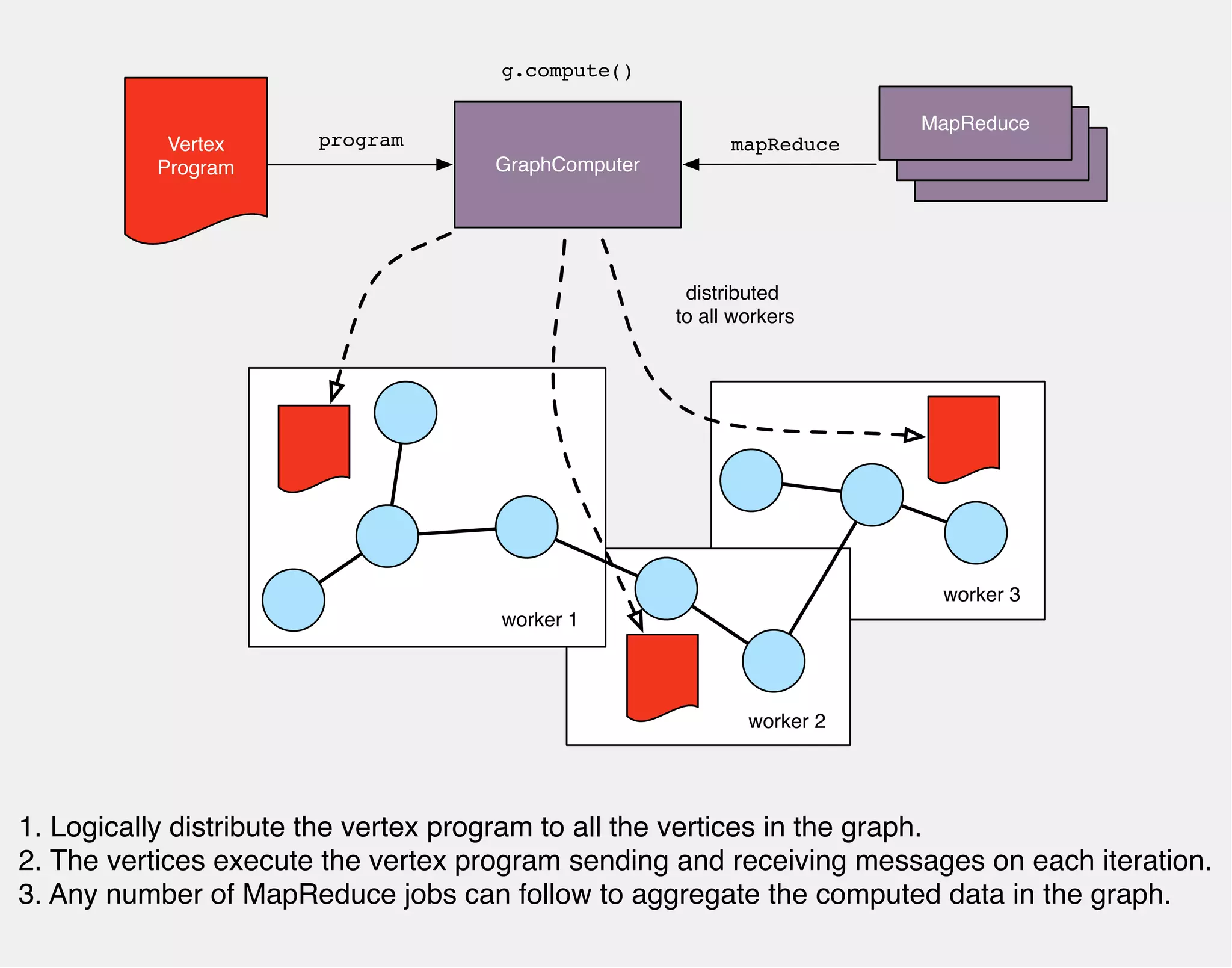
![MULTIPLE GRAPH COMPUTERS
FOR THE SAME GRAPH
gremlin> g = TitanFactory.open(conf)
==>titangraph[66.77.88.99]
gremlin> g.compute(FaunusGraphComputer)
.program(PageRankVertexProgram)
.submit()
==>result[faunusgraph,memory[size:0]]
gremlin> g = TitanFactory.open(conf)
==>titangraph[66.77.88.99]
gremlin> g.compute(FulgoraGraphComputer)
.program(PageRankVertexProgram)
.submit()
==>result[fulgoragraph,memory[size:0]]](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-119-2048.jpg)

![GREMLIN SERVER
gremlin> g = TitanFactory.open(conf)
==>titangraph[66.77.88.99]
localhost](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-121-2048.jpg)
![GREMLIN SERVER
gremlin> g = TitanFactory.open(conf)
==>titangraph[66.77.88.99]
gremlin> g.V.has('name','titan')
==>v[2]
localhost](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-122-2048.jpg)
![GREMLIN SERVER
gremlin> g = TitanFactory.open(conf)
==>titangraph[66.77.88.99]
gremlin> g.V.has('name','titan')
==>v[2]
gremlin> g.V.has('name','titan').out
localhost
1. get the titan vertex
2. get titan's adjacents](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-123-2048.jpg)
![GREMLIN SERVER
gremlin> g = TitanFactory.open(conf)
==>titangraph[66.77.88.99]
gremlin> g.V.has('name','titan')
==>v[2]
gremlin> g.V.has('name','titan').out
localhost
1. get the titan vertex
2. get titan's adjacents
CHATTY
Each step in the traversal is a round trip](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-124-2048.jpg)



![GREMLIN SERVER
gremlin> :remote connect tinkerpop.server titan.yaml
==>connected - 66.77.88.99:8182,11.22.33.44:8182,...
gremlin> :> g.V.has('name','titan')
==>v[2]
localhost
g.V.has('name','titan')](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-128-2048.jpg)
![GREMLIN SERVER
gremlin> :remote connect tinkerpop.server titan.yaml
==>connected - 66.77.88.99:8182,11.22.33.44:8182,...
gremlin> :> g.V.has('name','titan')
==>v[2]
gremlin> :> g.V.has('name','titan').out
localhost
g.V.has('name','titan').out
LESS CHATTY
1. Gremlin Server client knows the hash function
to query the machine with the Titan vertex
2. Push the traversal to the server and
get a WebSockets iterator back](https://image.slidesharecdn.com/the-path-forward-2014-141208115804-conversion-gate02/75/The-Path-Forward-129-2048.jpg)


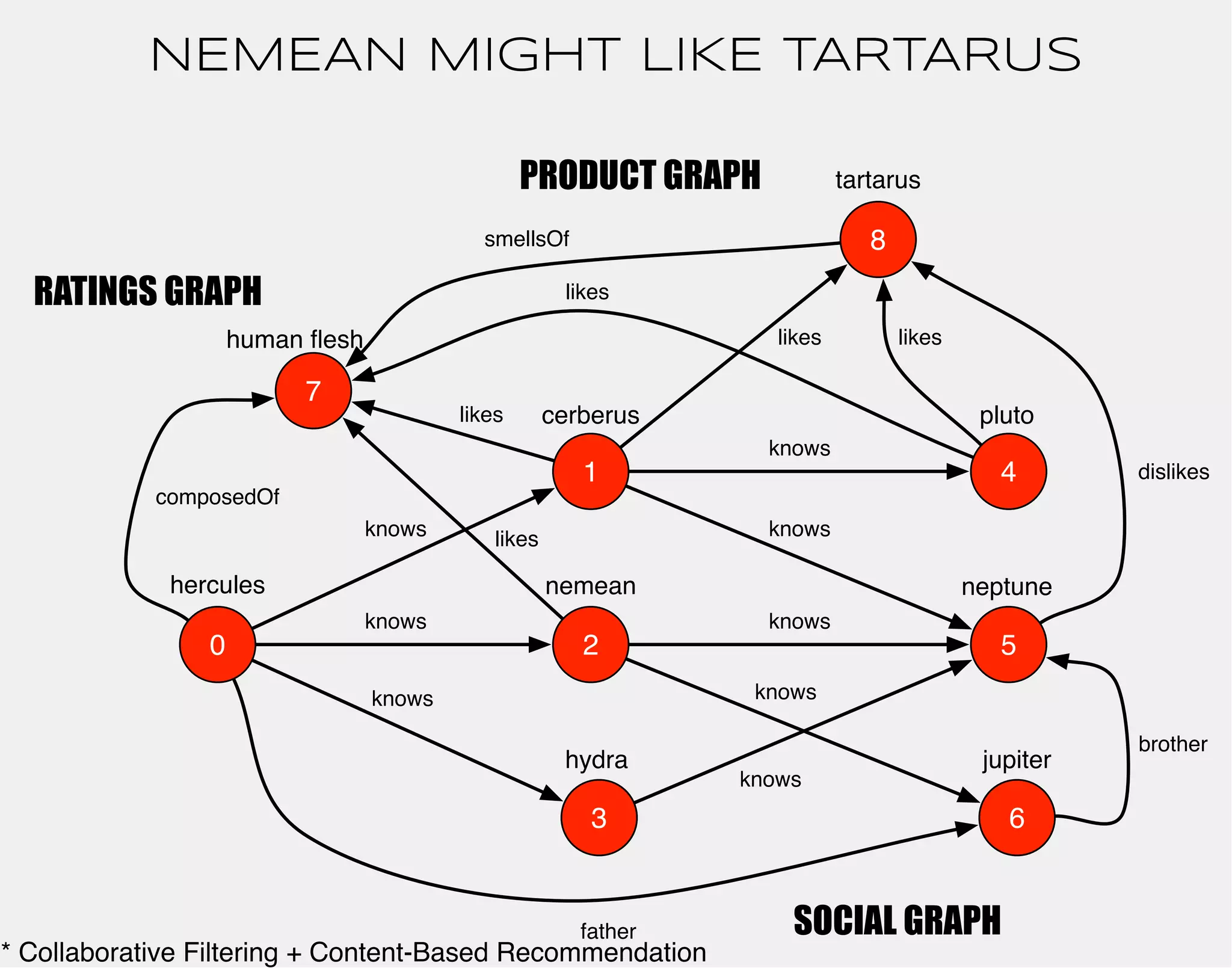
This document discusses graph-based computing and traversal using Gremlin and Titan. It provides examples of querying a graph about relationships between characters in Greek mythology like Hercules. Traversal operations are demonstrated to find other characters Hercules may know or which actor played him in a movie. The value of graph analysis for insights and recommendations is also discussed.







































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)





![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
