Download as PDF, PPTX





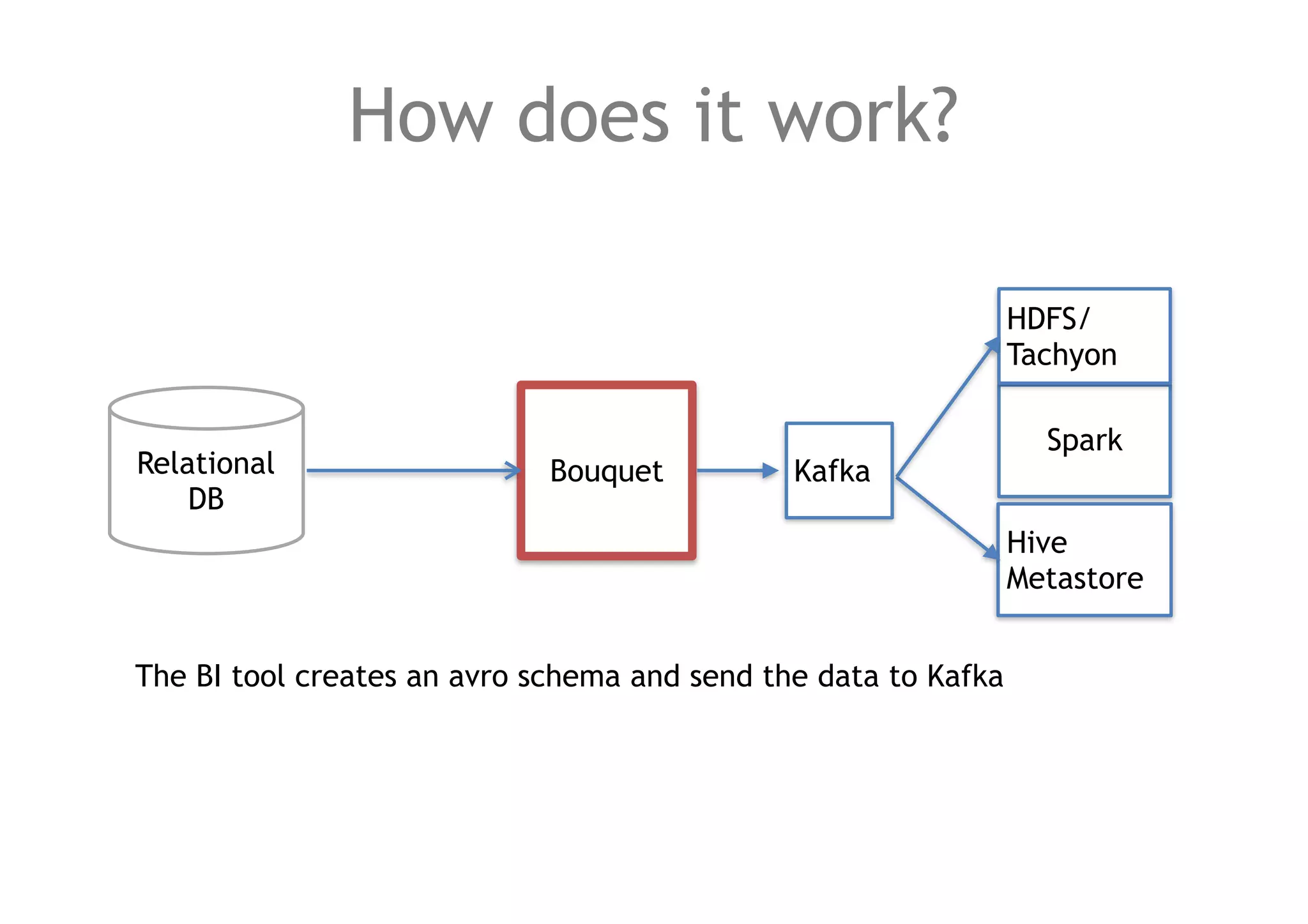
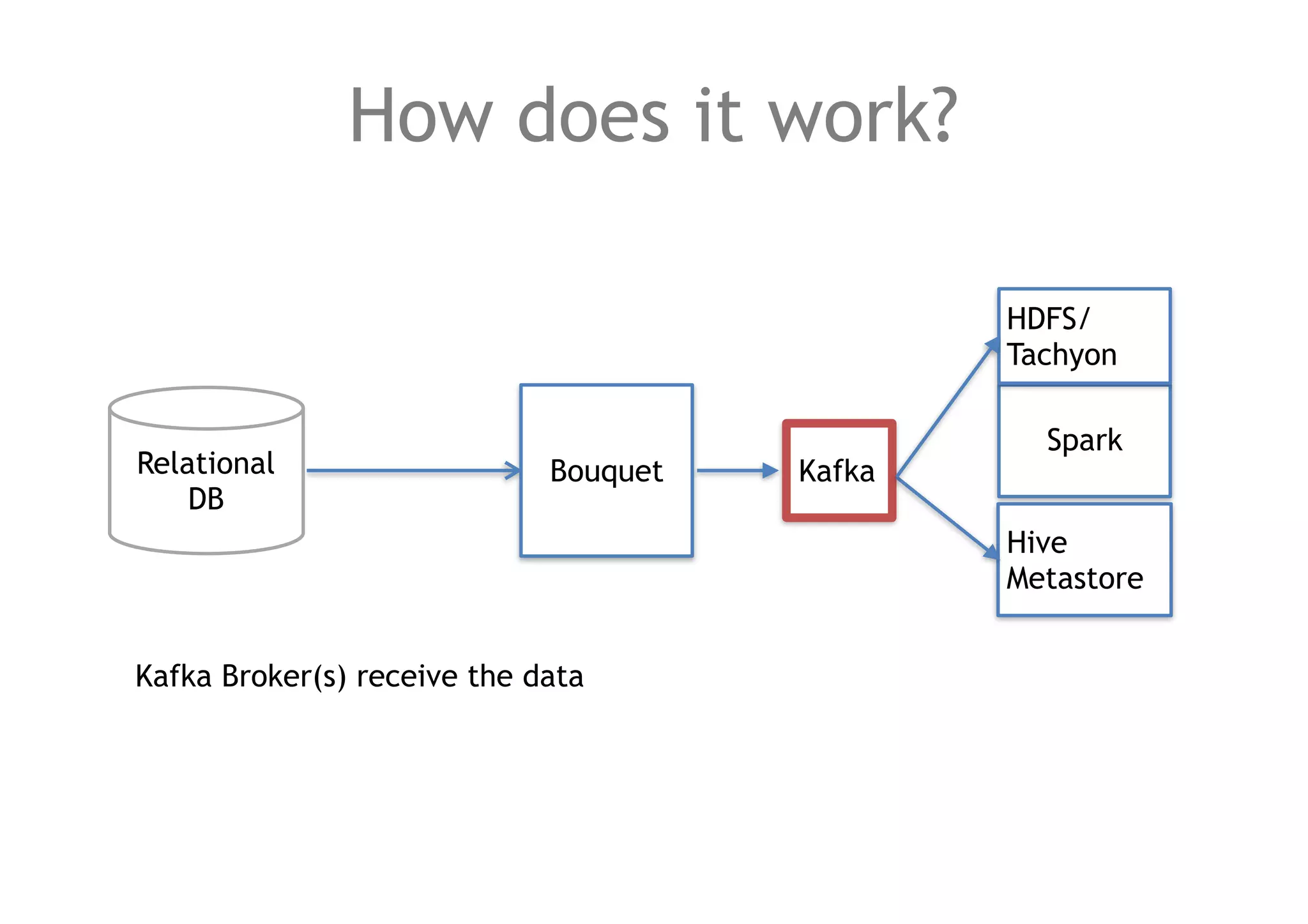
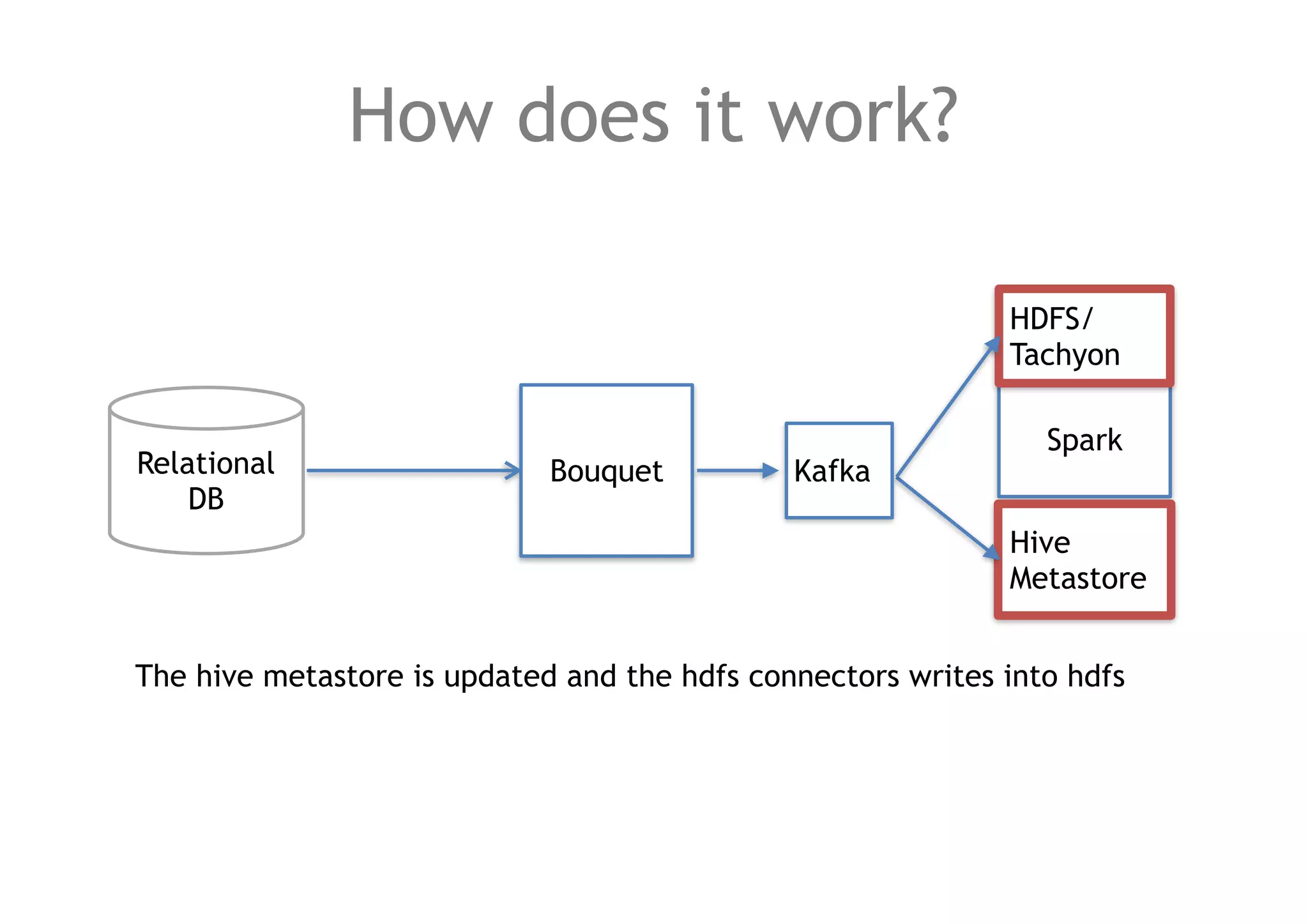
![How to keep the data structured?
Use a schema registry (Avro in Kafka).
each schema has a corresponding kafka topic and a distinct hive table.
{
"type": "record",
"name": "ArtistGender",
"fields" : [
{"name": "count", "type": "long"},
{"name": "gender", "type": "String"]}
]
}](https://image.slidesharecdn.com/squidhugfebrary2016key-160219111806/75/HUG-France-Feb-2016-Migration-de-donnees-structurees-entre-Hadoop-et-RDBMS-par-Louis-Rabiet-Squid-Solution-13-2048.jpg)







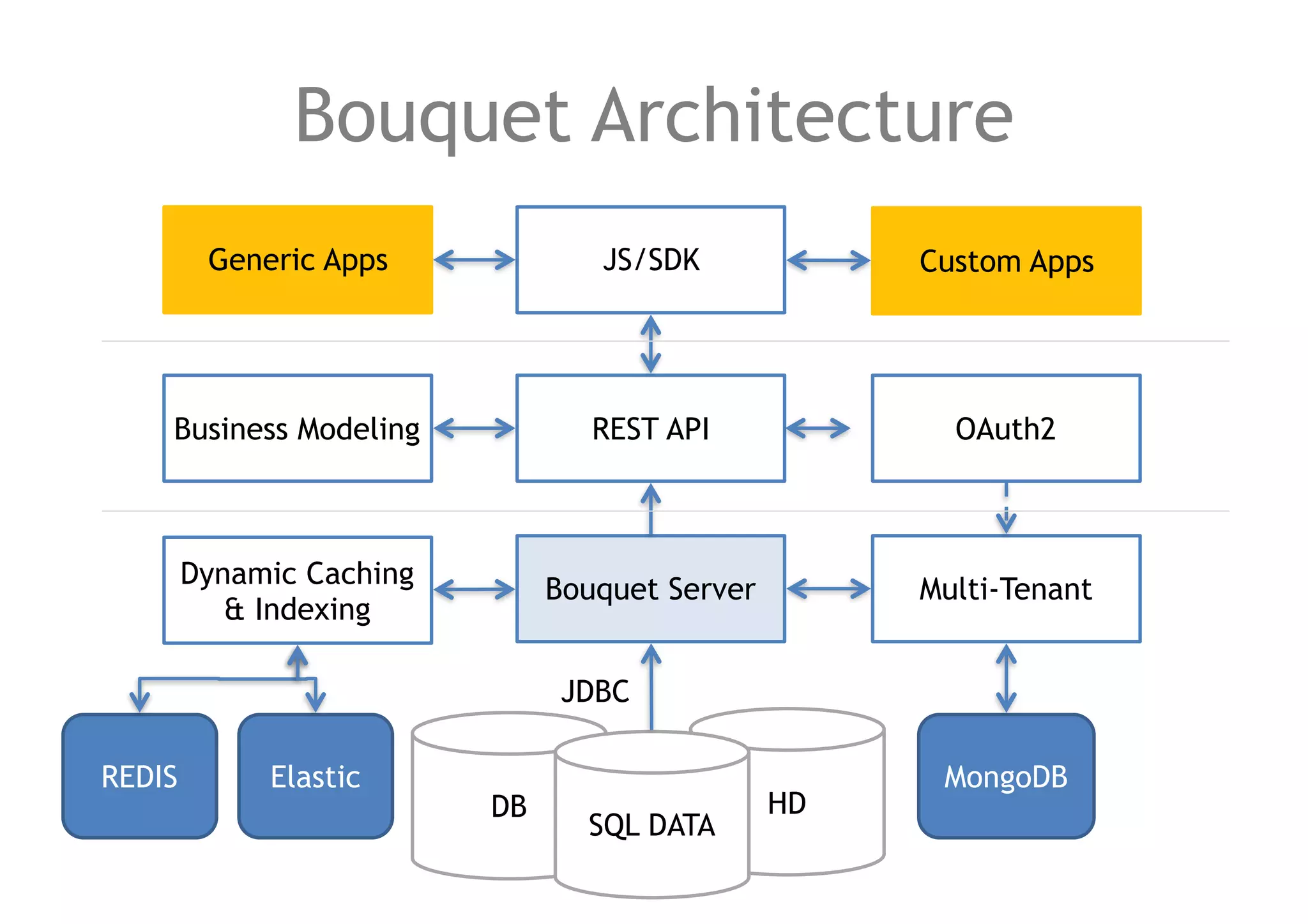

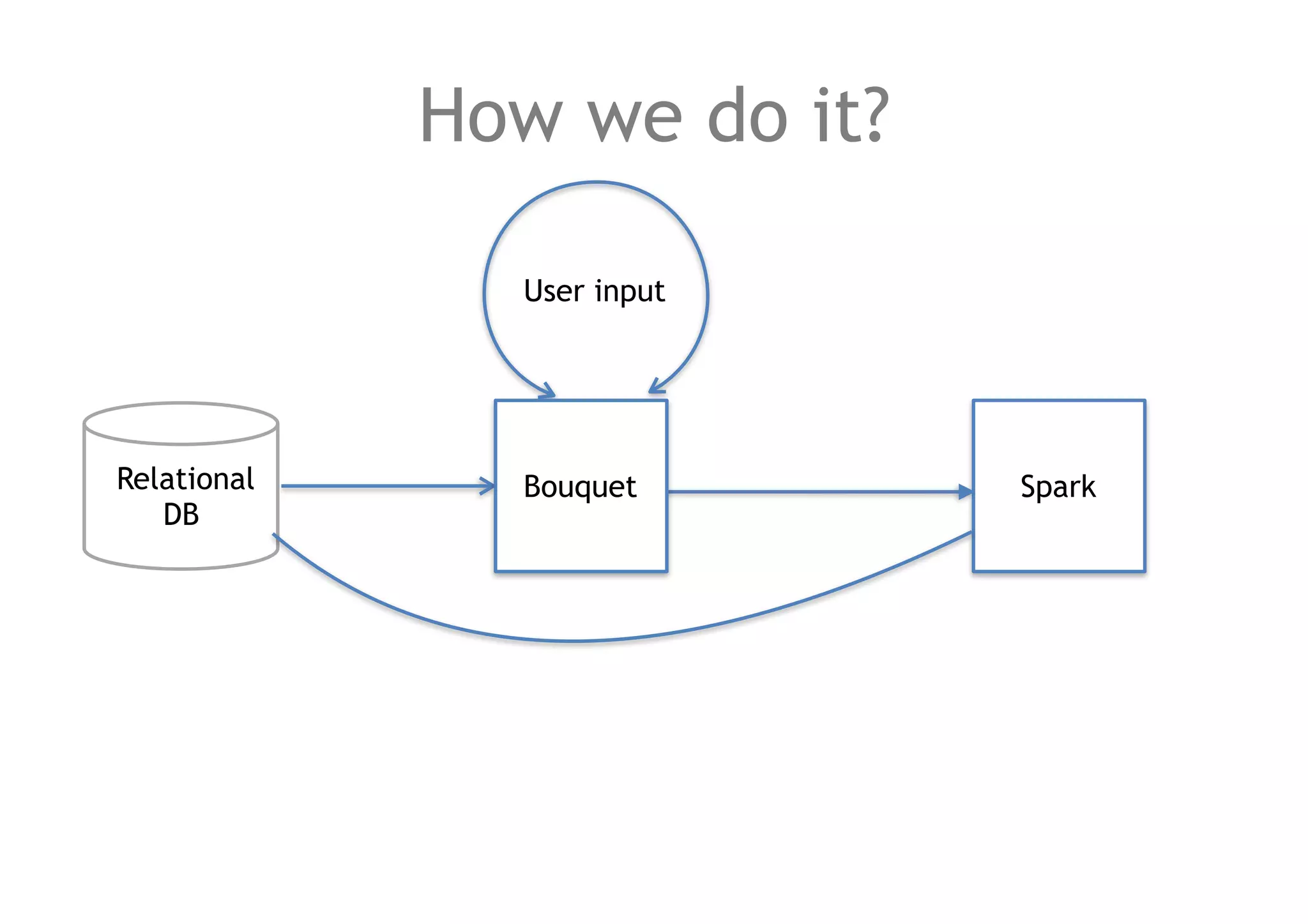
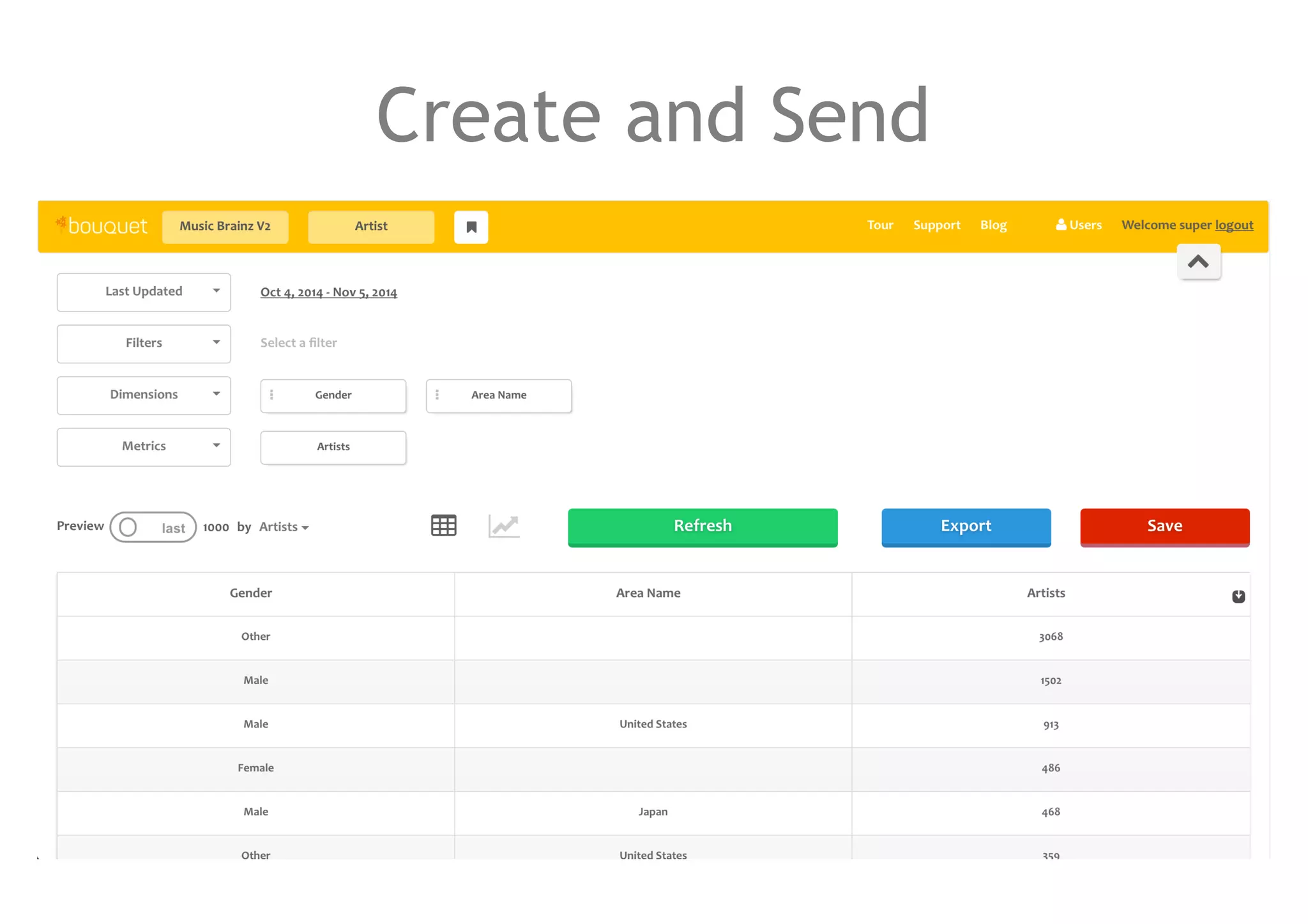
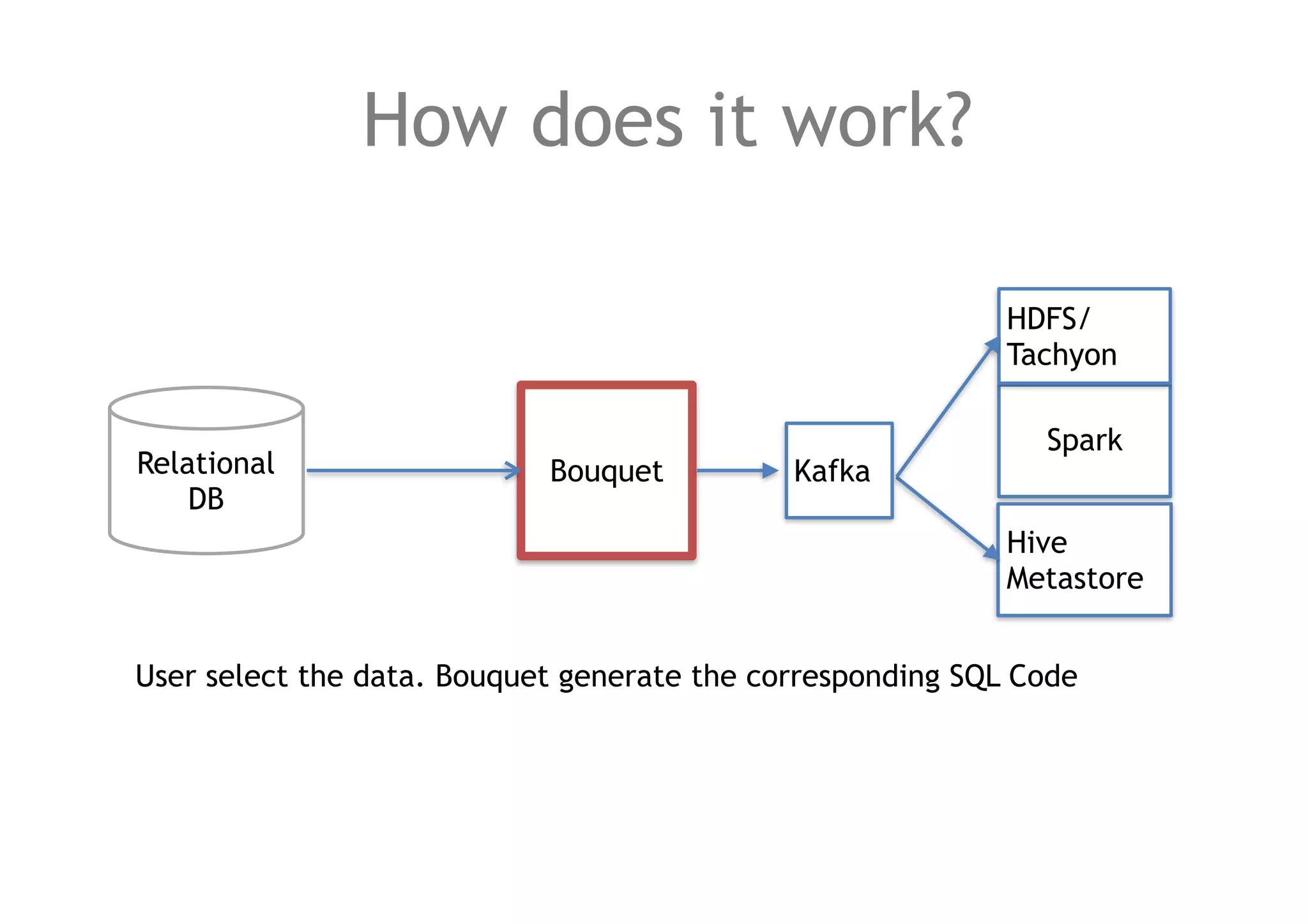
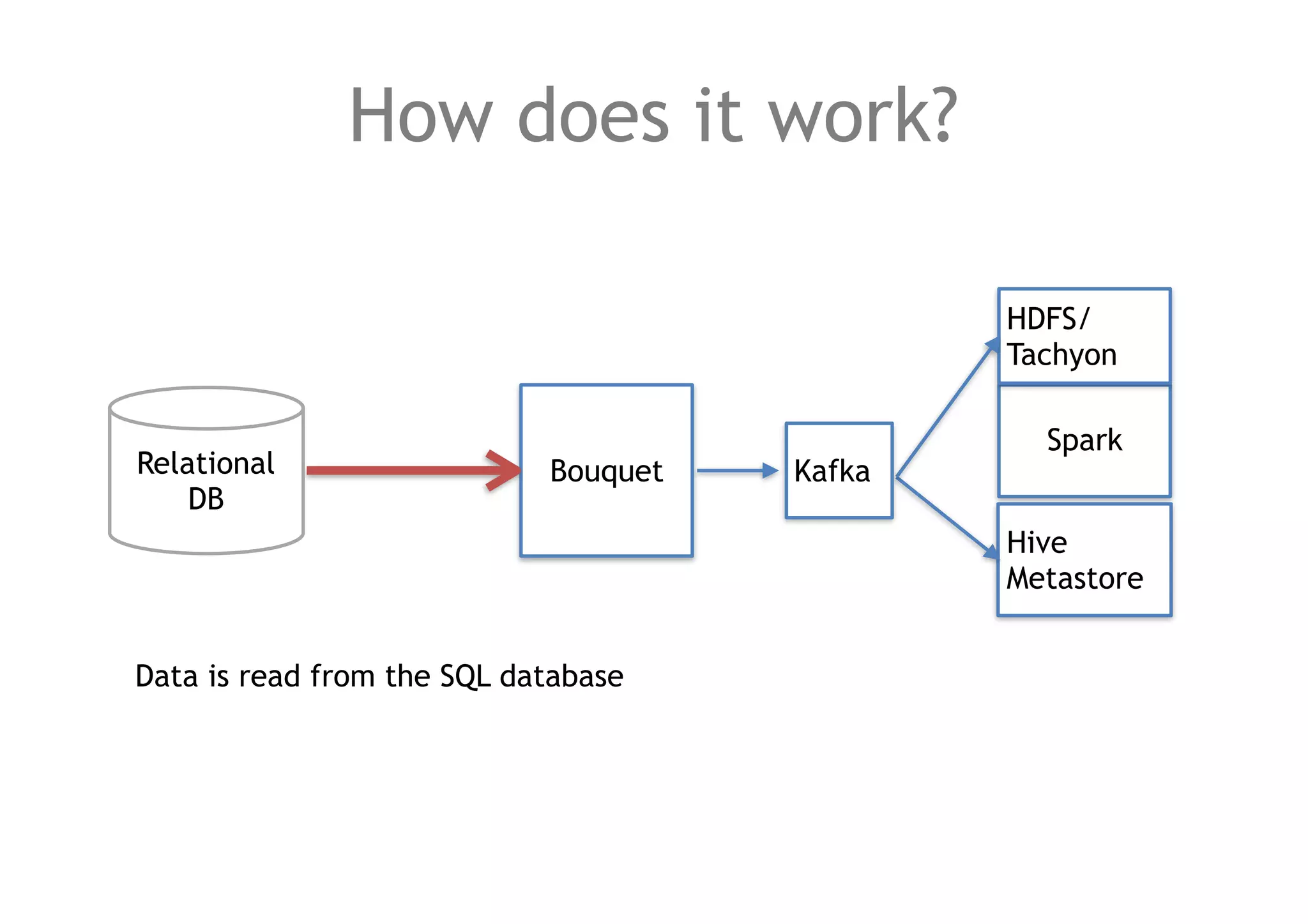
The document discusses a method for migrating structured data between Hadoop and RDBMS using an analytics toolbox called Bouquet, which generates SQL via a REST API. It highlights the integration of various technologies including Spark, Kafka, and Avro schema for efficient data management and enrichment. Challenges in implementation, as well as future improvements for scalability and functionality, are also outlined.






















































































