Downloaded 94 times












![Show Timeline: Provide Raw Data (Tweets)
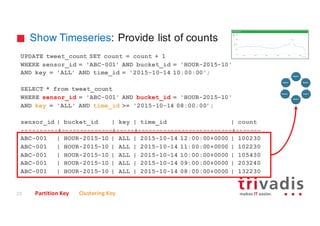
18
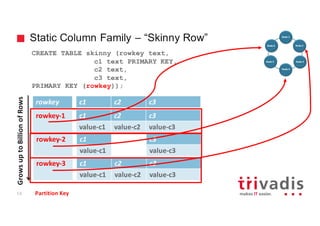
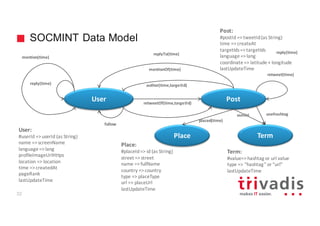
CREATE TABLE tweet (tweet_id bigint,
username text,
message text,
hashtags list<text>,
latitude double,
longitude double,
…
PRIMARY KEY(tweet_id));
• Skinny Row Table
• Holds the sensor raw data =>
Tweets
• Similar to a relational table
• Primary Key is the partition key
10000121 username message hashtags latitude longitude
gschmutz Getting ready for.. [cassandra, nosql] 0 0
20121223 username message hashtags latitude longitude
DataStax The Speed Factor .. [BigData 0 0
tweet_id
Partition Key Clustering Key](https://image.slidesharecdn.com/cassandra-timeseries-and-graph-v1-151016202012-lva1-app6891/85/Apache-Cassandra-for-Timeseries-and-Graph-Data-17-320.jpg)
![Show Timeline: Provide Raw Data (Tweets)
19
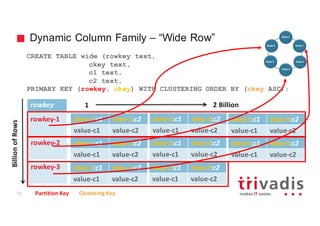
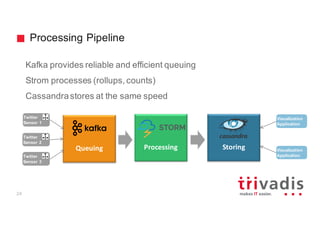
INSERT INTO tweet (tweet_id, username, message, hashtags, latitude,
longitude) VALUES (10000121, 'gschmutz', 'Getting ready for my talk about
using Cassandra for Timeseries and Graph Data', ['cassandra', 'nosql'],
0,0);
SELECT tweet_id, username, hashtags, message FROM tweet
WHERE tweet_id = 10000121 ;
tweet_id | username | hashtag | message
---------+----------+------------------------+----------------------------
10000121 | gschmutz | ['cassandra', 'nosql'] | Getting ready for ...
20121223 | DataStax | [’BigData’] | The Speed Factor ...
Partition Key Clustering Key](https://image.slidesharecdn.com/cassandra-timeseries-and-graph-v1-151016202012-lva1-app6891/85/Apache-Cassandra-for-Timeseries-and-Graph-Data-18-320.jpg)



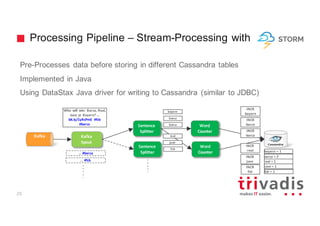




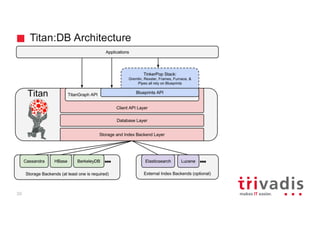






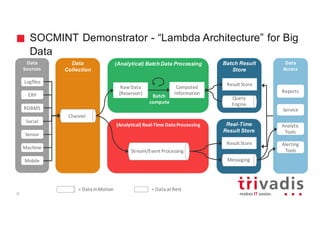
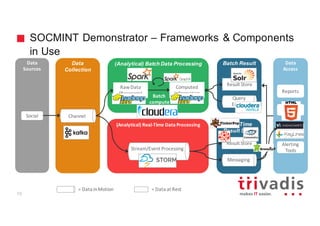
The document discusses the use of Apache Cassandra for handling time series and graph data, focusing on a research project that utilized a lambda architecture for big data analysis, using features like social media intelligence and real-time processing. It emphasizes the importance of proper data modeling in Cassandra, particularly for time series data and graph structures, promoting a denormalized approach and careful design of partition keys and clustering keys. The document also highlights various applications of Cassandra, including handling user behavior data on social networks and provides examples of data schemas and processing pipelines.





















































































