Download as PDF, PPTX


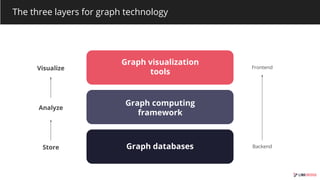
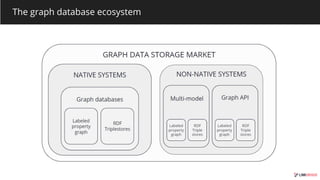

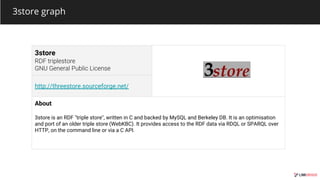
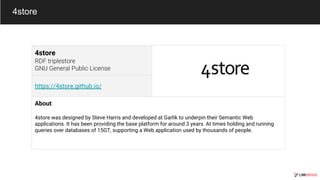
















The document outlines various graph database technologies and their features within the graphtech ecosystem of 2019. It provides brief descriptions of each database, including functionalities, supported query languages, and use cases. Notable technologies include 3store, AgensGraph, Amazon Neptune, and JanusGraph, among others, highlighting their roles in graph visualization, storage, and transaction processing.























































































