Downloaded 13 times





























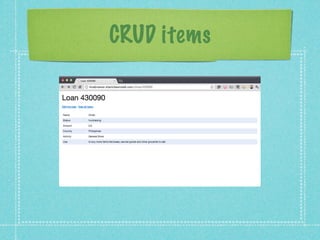





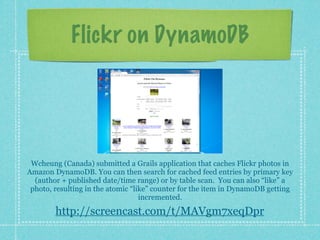
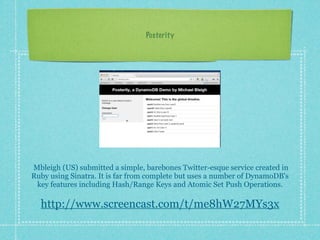





This document provides an overview of NoSQL databases and then discusses Amazon DynamoDB in more depth. It explains that NoSQL databases are an alternative to relational databases for certain data-intensive applications. It then discusses DynamoDB specifically, highlighting that it is a fully managed NoSQL database that provides fast and predictable performance, flexible data model, automatic scaling, and pay per request pricing. The document also provides examples of applications that were built on DynamoDB as part of a challenge.







































































