Downloaded 83 times

















![class AggregateArtists(luigi.Task):
date_interval = luigi.DateIntervalParameter()
def run(self):
artist_count = defaultdict(int)
for input in self.input():
with input.open('r') as in_file:
for line in in_file:
timestamp, artist, track = line.strip().split()
artist_count[artist] += 1
with self.output().open('w') as out_file:
for artist, count in artist_count.iteritems():
print >> out_file, artist, count
Programmatic Example](https://image.slidesharecdn.com/buildingdatapipelines-160311163511/85/Building-data-pipelines-24-320.jpg)

![PiecePipe::Pipeline.new.
source([{region: region}]).
step(FetchPowerPlantsByRegion).
step(FindWorstReactor).
step(DetermineStatusClass).
step(BuildPlantHealthSummary).
step(SortByRadiationLevelsDescending).
collect(:plant_health_summary).
to_enum
Piecepipe (Ruby)](https://image.slidesharecdn.com/buildingdatapipelines-160311163511/85/Building-data-pipelines-27-320.jpg)
















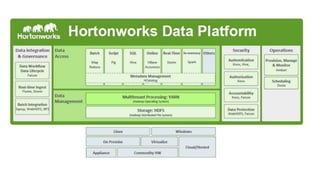
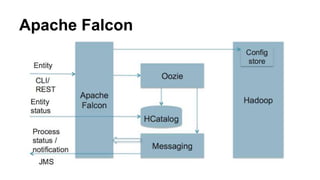





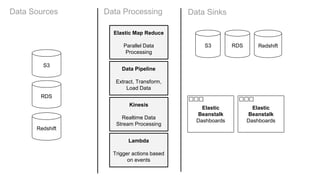










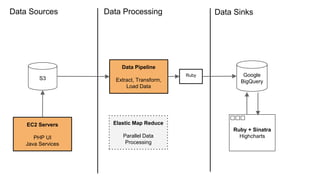









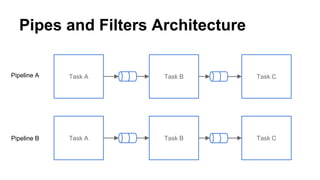
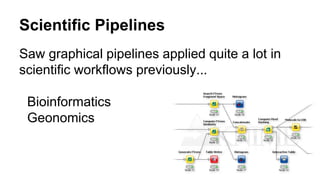
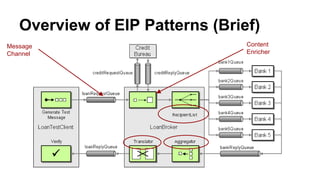
This document provides an overview of data pipelines and various technologies that can be used to build them. It begins with a brief history of pipelines and their origins in UNIX. It then discusses common pipeline concepts like decoupling of tasks, encapsulation of processing, and reuse of tasks. Several examples of graphical and programmatic pipeline solutions are presented, including Luigi, Piecepipe, Spring Batch, and workflow engines. Big data pipelines using Hadoop and technologies like Pig and Oozie are also covered. Finally, cloud-based pipeline technologies from AWS like Kinesis, Data Pipeline, Lambda, and EMR are described. Throughout the document, examples are provided to illustrate how different technologies can be used to specify and run data processing pipelines.














































































