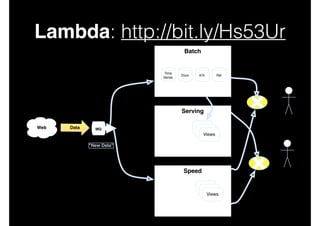
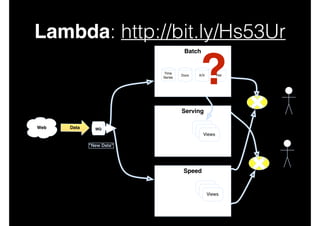
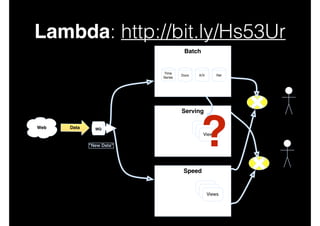
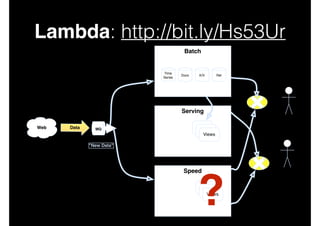
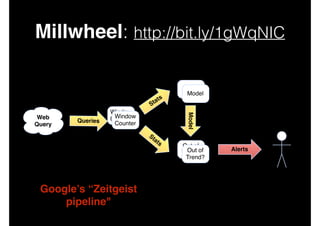
This document discusses big data and data-intensive science. It introduces the Lambda architecture, which processes streaming data in both batch and speed layers to generate real-time and batch views. The batch layer precomputes queries from all available data. The serving layer indexes batch views. The speed layer uses incremental algorithms to generate real-time views from new data. Queries are resolved by merging results from the batch and real-time views. Recommendations are made to leverage complex event processing and stream processing techniques to more efficiently construct views and handle merging and querying across layers.


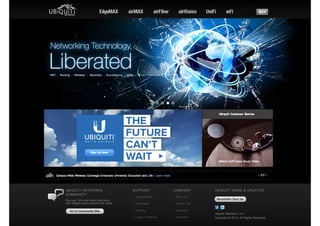






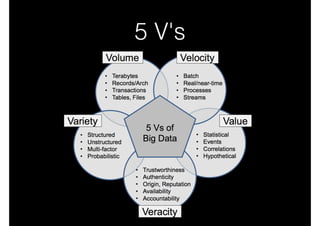
![5 V’s via [V-PEC-T]
•
Business Factors
•
•
•
‘Veracity’ - The What
‘Value’ - The Why
Technical Domain (Policies, Events, Content)
•
Volume, Velocity, Variety](https://image.slidesharecdn.com/bigdatamobscale-131030122629-phpapp01/85/Big-Data-Mob-Scale-16-320.jpg)










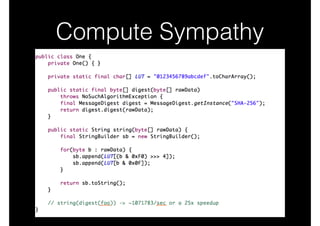
![Use a DSP + CEP/ESP or
‘Scalable CEP'
•
Storm/S4 + Esper/…
•
Embed a CEP/ESP within a Distributed
Stream processing Engine
•
Use Drill for large scale ad hoc query
[leverage nested records]
•
Already have middleware? Have well
defined queries? Roll your own minimal
EEP (or use mine!)](https://image.slidesharecdn.com/bigdatamobscale-131030122629-phpapp01/85/Big-Data-Mob-Scale-36-320.jpg)


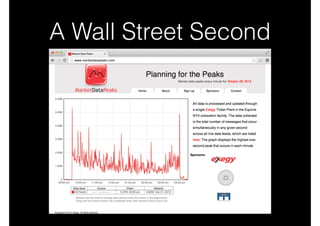
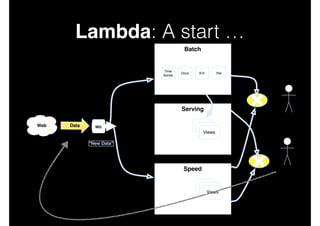
![Lambda: Merging …
•
Possibly one of the most difficult aspects of near
real-time and historical data integration is
combining flows sensibly.
•
For example, is the order of interleaving across
merge sources applied in a known
deterministically recomputable order? If not, how
can results be recomputed subsequently? Will
data converge?
[cf: http://cs.brown.edu/research/aurora/hwang.icde05.ha.pdf]](https://image.slidesharecdn.com/bigdatamobscale-131030122629-phpapp01/85/Big-Data-Mob-Scale-40-320.jpg)




























































![Complex Er[jl]ang Processing with StreamBase](https://cdn.slidesharecdn.com/ss_thumbnails/complexerjlangprocessing-pptx-110611095407-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




















