Downloaded 74 times




















![36
Cypher
Cypher Representation :
(c)-[:KNOWS]->(b)-[:KNOWS]->(a), (c)-[:KNOWS]-
>(a)
(c)-[:KNOWS]->(b)-[:KNOWS]->(a)<-[:KNOWS]-(c)](https://image.slidesharecdn.com/graphdb-130831071924-phpapp02/85/Graph-db-36-320.jpg)
![37
Cypher
START c=node:user(name='Michael')
MATCH (c)-[:KNOWS]->(b)-[:KNOWS]->(a), (c)-
[:KNOWS]->(a)
RETURN a, b](https://image.slidesharecdn.com/graphdb-130831071924-phpapp02/85/Graph-db-37-320.jpg)



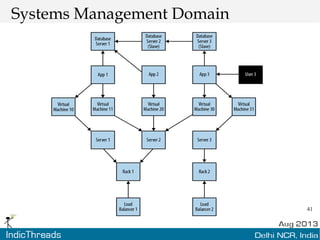
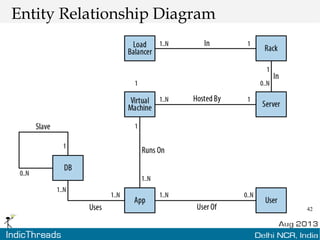
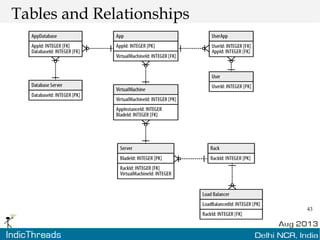
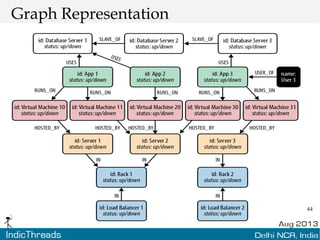



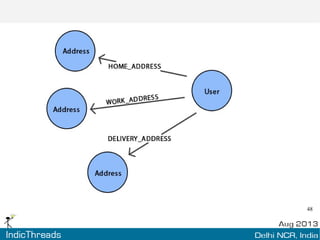
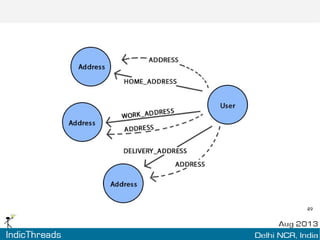







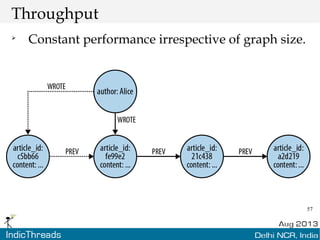



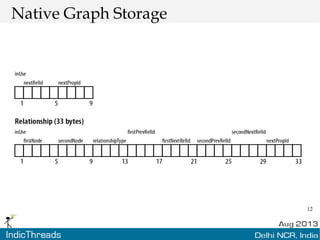
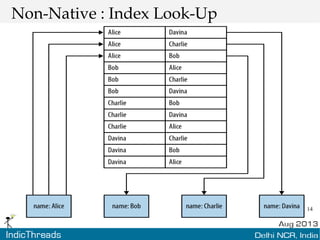
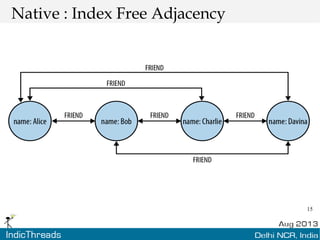
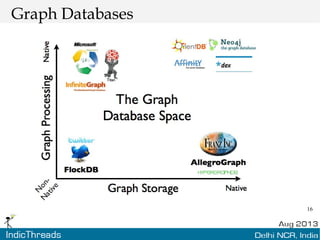
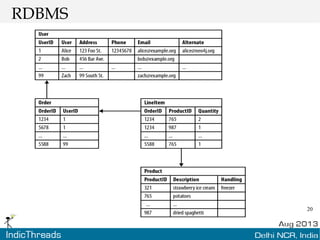
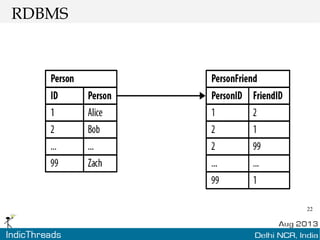
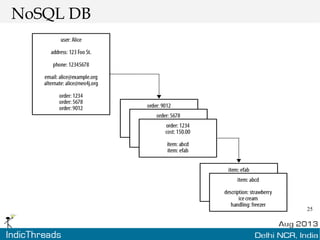
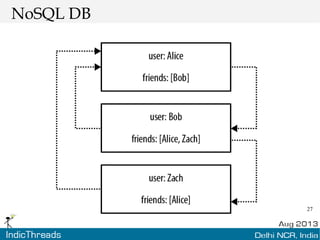
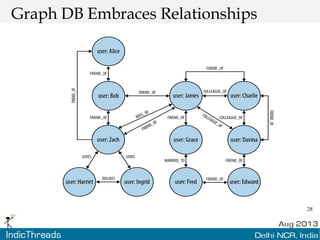
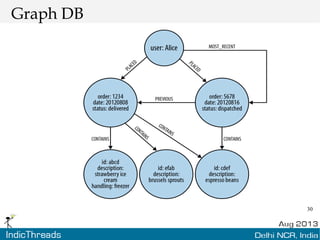
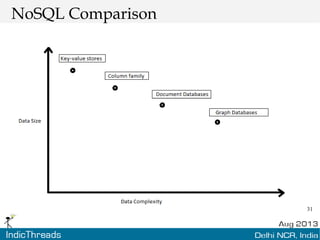
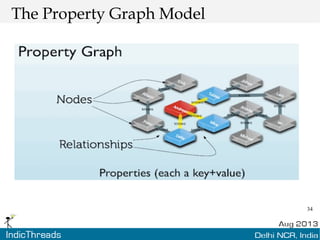
The document discusses using graph databases for insights into connected data. It provides an overview of graph databases, comparing them to relational databases and NoSQL stores. It discusses how graph databases are better suited than other models for richly connected data due to their native support of relationships. The document also covers graph data modeling, the Cypher query language, examples of graph databases in real world domains, and aspects of graph database internals like scalability.

































































