Download as PDF, PPTX




![Data(Movement(Issue(
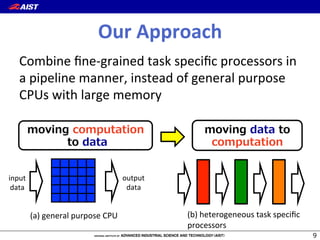
• Data(movement(is(the(boXleneck(to(
performance(
– Memory(wall,(Interconnect(wall,(and(Power(wall(
– E.g.,(K(computer([Byte/FLOP]:(
• Memory:(0.5(
• Interconnect:(0.15625(
• Current(solu@on:(Data(affinity(processing((DAP)(](https://image.slidesharecdn.com/20150728-150729164733-lva1-app6892/85/Flow-centric-Computing-A-Datacenter-Architecture-in-the-Post-Moore-Era-6-320.jpg)


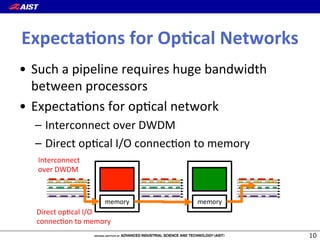
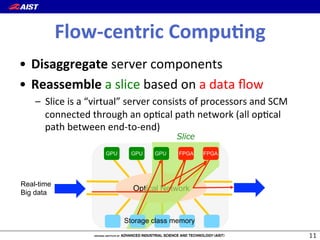
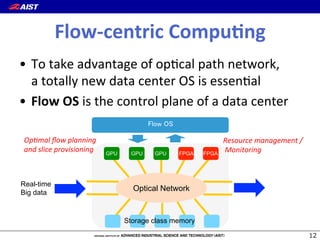
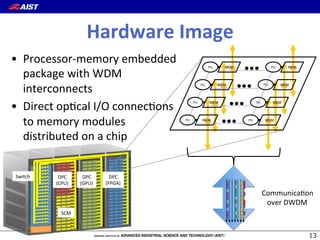



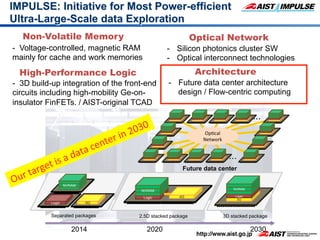
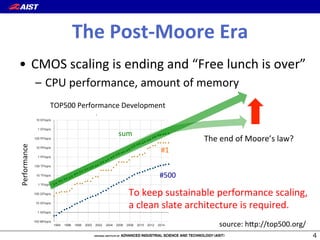
1) The document proposes a new "flow-centric computing" data center architecture for the post-Moore era that focuses on data flows. 2) It involves disaggregating server components and reassembling them as "slices" consisting of task-specific processors and storage connected by an optical network to efficiently process data. 3) The authors expect optical networks to enable high-speed communication between processors, replacing general CPUs, and to potentially revolutionize how data is processed in future data centers.






















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















