Downloaded 69 times







![CUDA
Programming
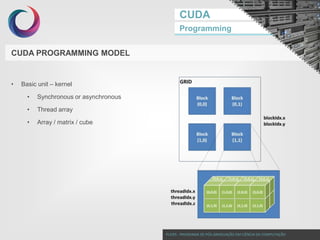
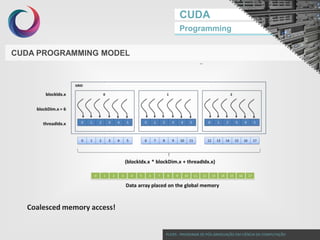
CUDA PROGRAMMING MODEL
thread ID
•
Basic unit – kernel
•
2
3
4
…
Thread array
•
1
Synchronous or asynchronous
•
0
Array / matrix / cube
[1] Keutzer, K.,Malik, S. Newton, A.R., Rabaye, J.M. and Sangiovanni Vincentelli, A.: System-level design: orthogonolization of concerns and platform-based
design. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst.,2000,19, (12), pp. 1523-1543
PUCRS - PROGRAMA DE PÓS-GRADUAÇÃO EM CIÊNCIA DA COMPUTAÇÃO](https://image.slidesharecdn.com/ppcudav1-131225175958-phpapp01/85/GPU-Programming-with-CUDA-12-320.jpg)

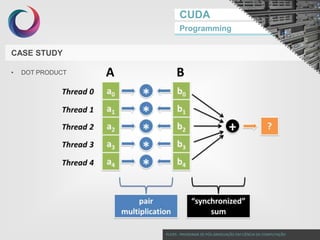
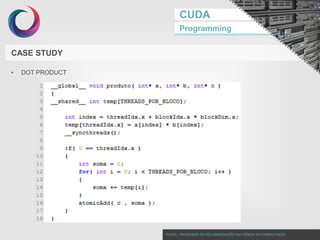

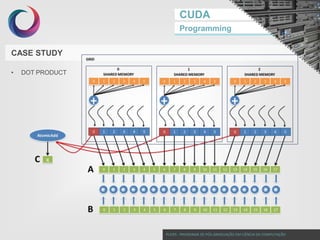

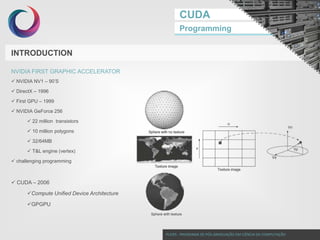
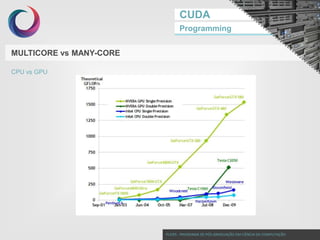
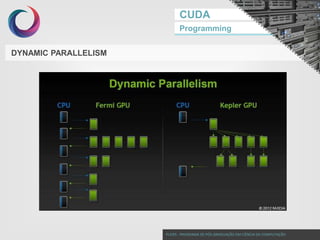
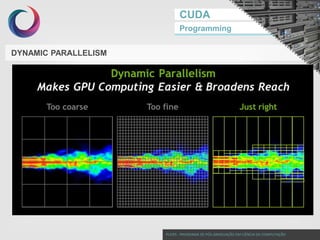
This document discusses GPU programming with CUDA. It begins with an introduction to Nvidia graphics cards and the CUDA programming model. It then covers Nvidia GPU architecture such as the evolution of GPU generations from Tesla to Volta. The CUDA programming model is also summarized, including its use of kernels, threads, and memory access. Finally, a case study on implementing dot product parallelization on a GPU is presented to demonstrate CUDA programming.























































































