






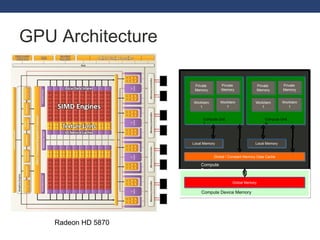

![Programming GpGpu for (i = 0; i < N; i++) a[i] = a[i] * 2; #pragma omp for for (i = 0; i < N; i++) a[i] = a[i] * 2; i = get_thread_id (); a[i] = a[i] * 2 ; int a[8]; SISD MIMD (with OpenMP) SIMT Time __kernel void helloWorld (__global int* a) { i = get_thread_id(); a[i] = a[i] * 2; } 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7](https://image.slidesharecdn.com/gpgpuworkloads-110606042131-phpapp01/85/Exploring-Gpgpu-Workloads-9-320.jpg)


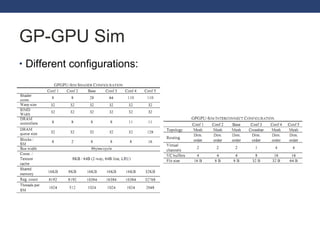
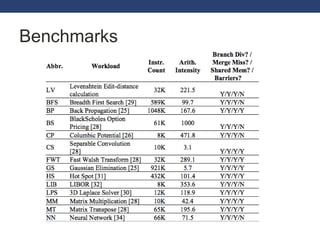
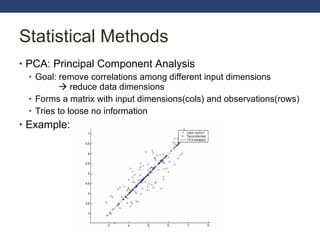
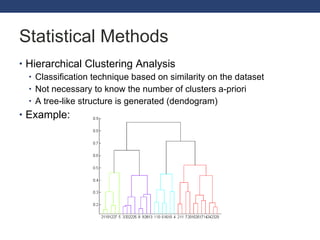

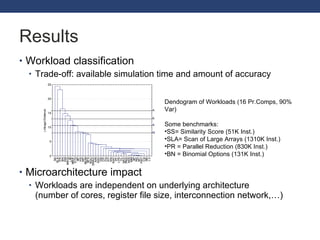





This document discusses exploring GPGPU workloads. It provides an introduction to GPGPU and GPU architecture. It analyzes workloads using statistical methods like PCA and hierarchical clustering. The results show that branch divergence, instruction count, and memory usage are key factors affecting efficiency. Workloads can be classified based on their characteristics. Future trends include GPUs being used more for computing and evolving architectures.























































































