Downloaded 433 times













![Conventional C Code
// Invoke DAXPY
dapxy(n,2.0,x,y);
// DAXPY in C
void daxpy(int n,double a,double *x, double *y)
{
for (int i=0;i<n;++i)
y[i] = a*x[i] + y[i];
}](https://image.slidesharecdn.com/gpu1-131213003636-phpapp01/75/GPU-An-Introduction-16-2048.jpg)
![Corresponding CUDA Code
// Invoke DAXPY with 256 threads per Thread Block
_host_
int nblocks = (n+255)/256;
daxpy<<<nblocks,256>>>(n,2.0,x,y);
//DAXPY in CUDA
_device_
Void daxpy(int n,double a,double *x, double *y)
{
int i = blockIdX.x*blockDim.x+threadIdx.x;
if(i<n) y[i]=a*x[i]+y[i];
}
●](https://image.slidesharecdn.com/gpu1-131213003636-phpapp01/75/GPU-An-Introduction-17-2048.jpg)





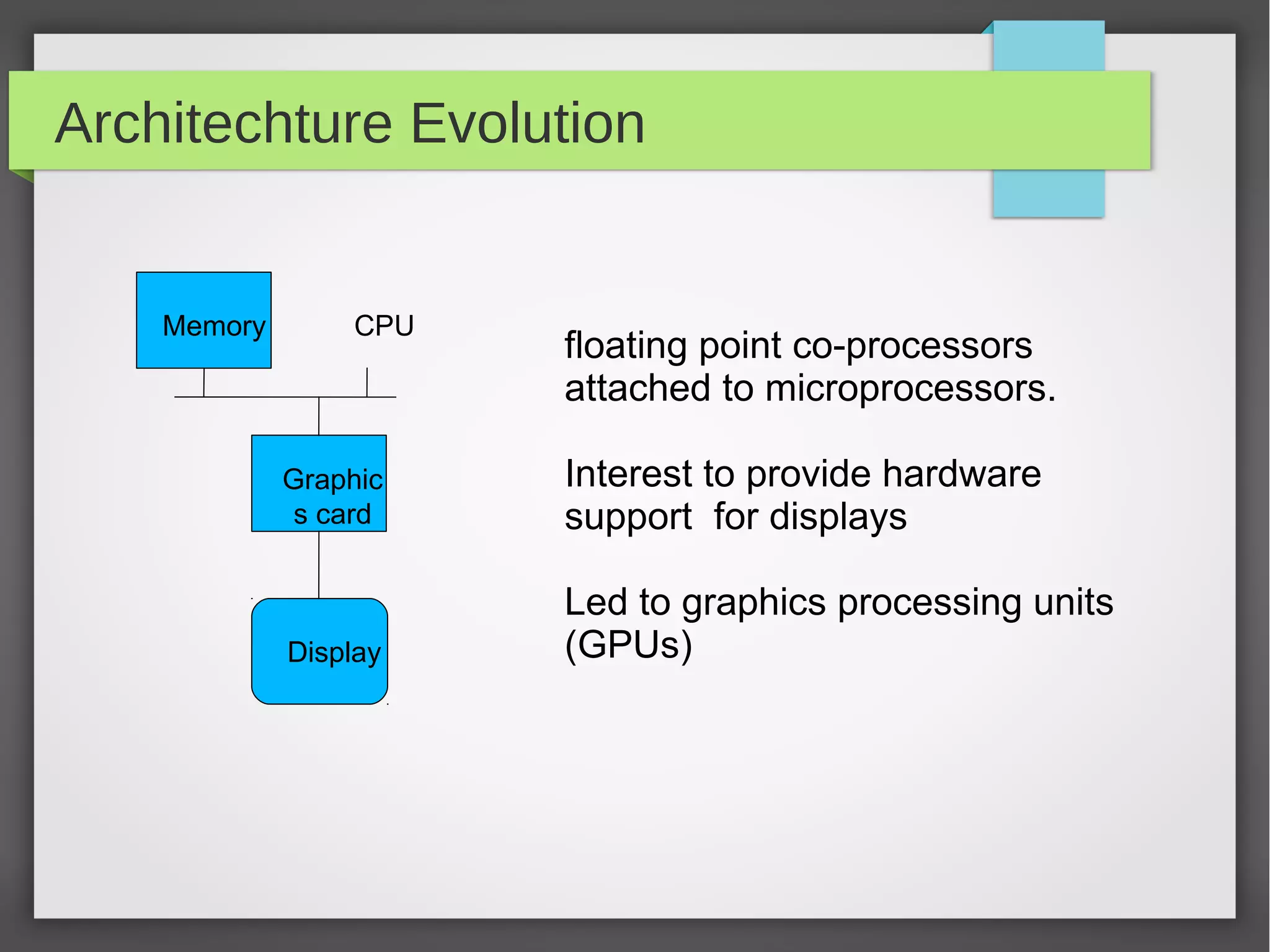
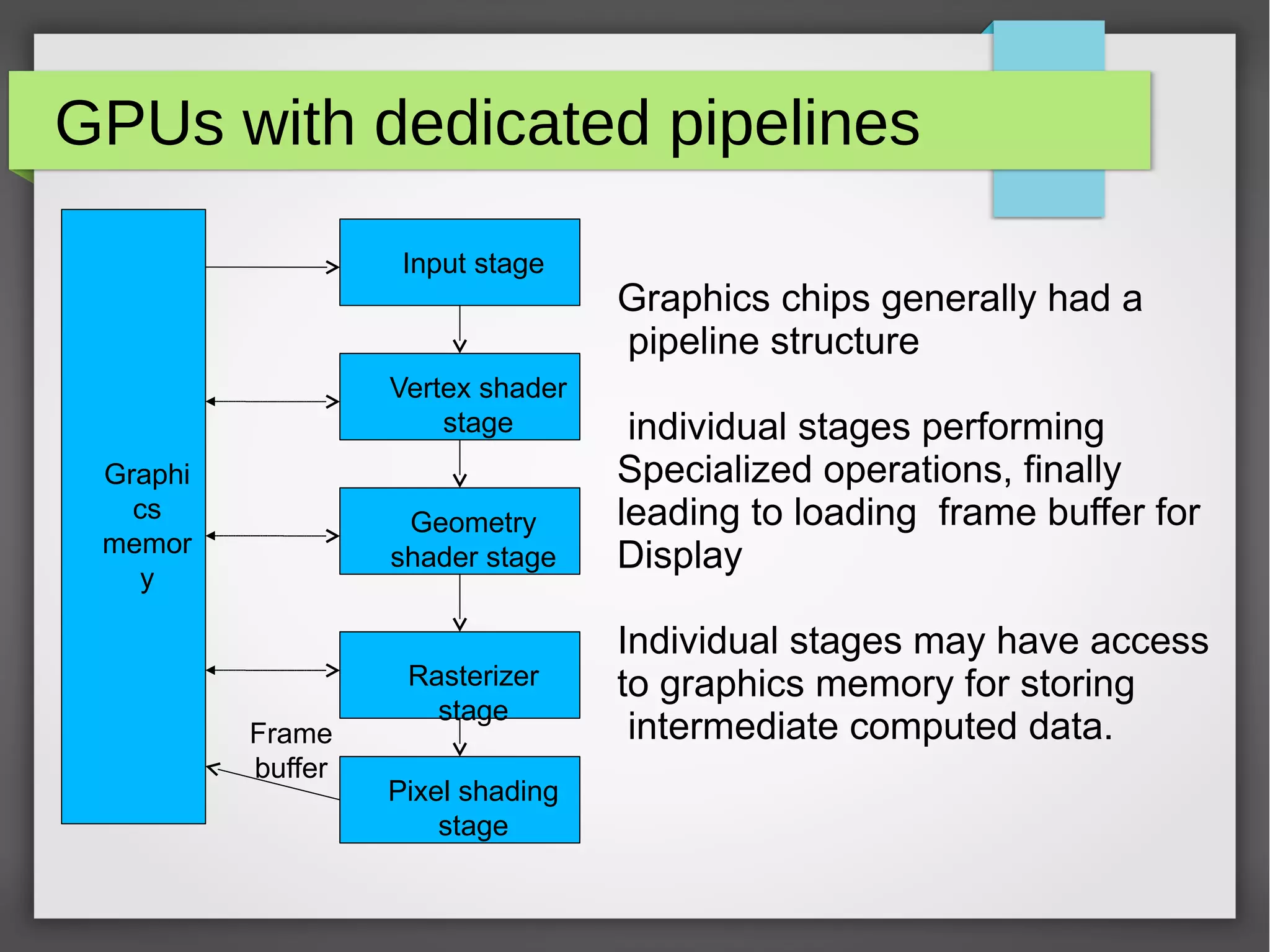
Graphics Processing Units (GPUs) are specialized electronic circuits designed to rapidly manipulate and alter memory to accelerate the creation of images in a frame buffer intended for output to a display. GPUs have evolved from simple video controllers to massively parallel multi-core processors capable of general purpose computing. Modern GPUs use a single-instruction, multiple-thread (SIMT) architecture and have a parallel programming model that maps computations to thousands of threads to maximize throughput. Programming frameworks like CUDA and OpenCL allow general purpose programming on GPUs by mapping algorithms to their highly parallel structure.





















































![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)


