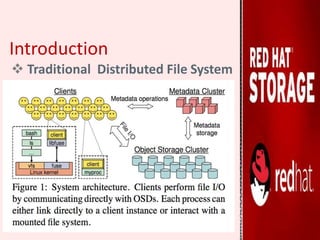
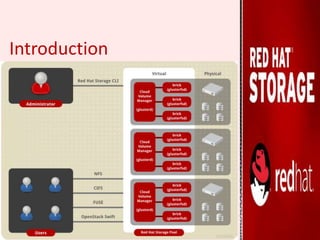
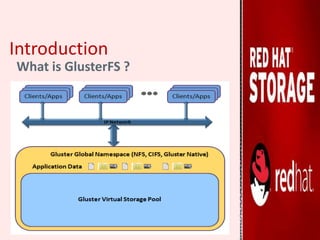
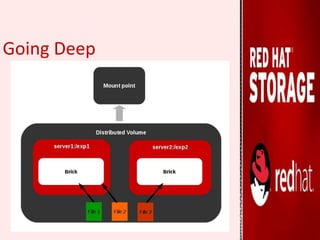
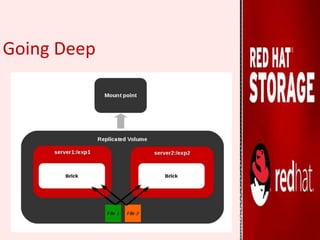
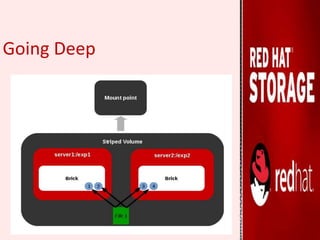
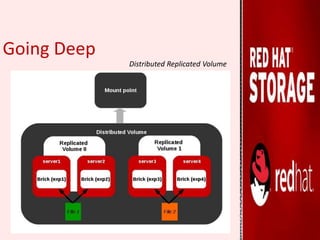
GlusterFS is an open-source distributed file system that aggregates various storage servers over a network into one large parallel file system. It does not require a metadata server, ensuring better performance, linear scalability, and reliability compared to traditional distributed file systems. Red Hat Gluster Storage provides a scalable, reliable data management platform using GlusterFS to streamline file access across physical, virtual, and cloud environments. It supports various volume types including distributed replicated volumes which replicate data across multiple servers for high availability.