Download to read offline













![Lockless Job Queue #2
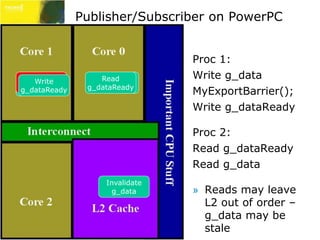
» Assigning work – one writer only:
if( RoomAvail( readPt, writePt ) ) {
CircWorkList[ writePt ] = workItem;
writePt = WRAP( writePt + 1 );
Correct On
Broken As
Executed
» Worker thread – one reader only:
Paper
if( DataAvail( writePt, readPt ) ) {
WorkItem workItem =
CircWorkList[ readPt ];
readPt = WRAP( readPt + 1 );
DoWork( workItem );](https://image.slidesharecdn.com/gdc09dawsonlocklessprogramming-141127183140-conversion-gate02/85/Lockless-Programming-GDC-09-13-320.jpg)






![Fixed Job Queue #2
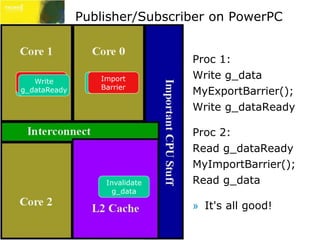
» Assigning work – one writer only:
if( RoomAvail( readPt, writePt ) ) {
MyImportBarrier();
CircWorkList[ writePt ] = workItem;
MyExportBarrier();
writePt = WRAP( writePtr + 1 );
» Worker thread – one reader only:
Correct!!!
if( DataAvail( writePt, readPt ) ) {
MyImportBarrier();
WorkItem workItem =
CircWorkList[ readPt ];
MyExportBarrier();
readPt = WRAP( readPt + 1 );
DoWork( workItem );](https://image.slidesharecdn.com/gdc09dawsonlocklessprogramming-141127183140-conversion-gate02/85/Lockless-Programming-GDC-09-30-320.jpg)









![Possible Compiler Rewrite
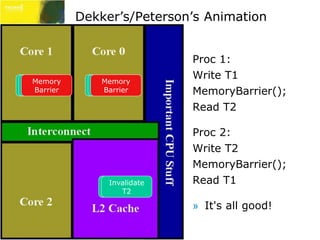
Foo* GetFoo() {
static Foo* volatile s_pFoo;
Foo* tmp = s_pFoo;
if( !tmp ) {
EnterCriticalSection( &initLock );
tmp = s_pFoo; // Reload inside lock
if( !tmp ) {
s_pFoo = (Foo*)new char[sizeof(Foo)];
new(s_pFoo) Foo; tmp = s_pFoo;
}
LeaveCriticalSection( &initLock );
}
return tmp; }](https://image.slidesharecdn.com/gdc09dawsonlocklessprogramming-141127183140-conversion-gate02/85/Lockless-Programming-GDC-09-41-320.jpg)









The document discusses lockless programming in games, highlighting its advantages such as lower overhead and avoidance of deadlocks, while also noting its complexities and limited portability. It emphasizes the importance of understanding memory models and barriers when developing multi-threaded applications, particularly for platforms like Xbox 360 and Windows. The conclusion recommends using locks unless their overhead is prohibitively high and suggests utilizing pre-built lockless algorithms for safety.





























































































