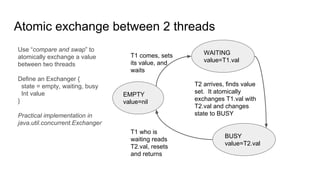
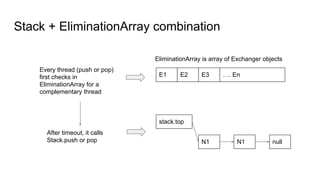
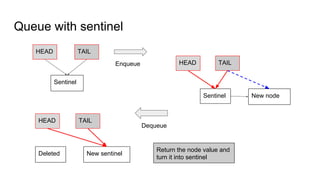
The document discusses lockless data structures, emphasizing the differences between lockfree and waitfree concurrency levels and how they can be implemented using various programming languages and techniques. It covers concepts like critical sections, atomic operations, and practical implementations for data structures such as stacks and queues. The document also highlights the challenges of cache line contention and strategies like using sentinels and padding to optimize performance.











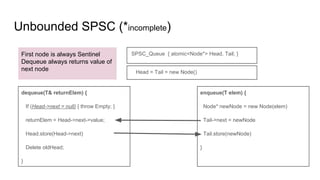
![Bounded SPSC
ProducerConsumerQueue
● atomic<int> readIndex
● Item records[size]
● atomic<int> writeIndex
enqueue(Item newElem) {
Int freeSlot = writeIndex.load()
If freeSlot + 1 != readIndex.load() {
records[freeSlot] = newElem
writeIndex.store(freeSlot)
}
dequeue(Item& returnElem) {
Int curSlot = readindex.load()
If curSlot != writeIndex.load() {
returnElem = record[curSlot]
readIndex.store(curSlot + 1)
}
Based on Facebook folly library
Avoid cache
line sharing](https://image.slidesharecdn.com/lockless-170617083936/85/Lockless-16-320.jpg)







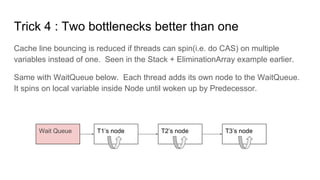
![Trick 5 : Padding to avoid false cache line sharing
Class Queue {
Atomic<int> head;
Char cache_line_pad[CACHE_LINE_SIZE (e.g.64 byte)];
Atomic<int> tail; // Keeps head and tail on separate cache
lines
}
https://software.intel.com/en-us/articles/avoiding-and-identifying-false-sharing-among-threads](https://image.slidesharecdn.com/lockless-170617083936/85/Lockless-27-320.jpg)


![Who uses lockless ?
1. Early adopters were desktop audio drivers [1]
2. MemSQL : pervasive use of lockfree data structures
3. Couchbase : Nitro storage engine
4. DataDomain (EMC) : lockfree doubly linked list
5. Facebook Folly library
6. Java.util.concurrent (Doug Lea)
7. Linux kernel (other mechanisms besides RCU)
[1] http://www.rossbencina.com/code/lockfree](https://image.slidesharecdn.com/lockless-170617083936/85/Lockless-30-320.jpg)
















































































