Download to read offline









![LOAD ELIMINATION IN ATOMIC BLOCKS. 1
for (int j = 0; j < nfeatures; j++) {
new_centers[index][j] = new_centers[index][j]
+ feature[i][j];
5 instrumented
}
memory reads per
loop iteration
(using Lazy Code Motion)
if (0 < nfeatures) {
nci = new_centers[index];
fi = feature[i];
for (j = 0; j < nfeatures; j++) {
nci[j] = nci[j] + fi[j];
}
}
2 instrumented
memory reads per
loop iteration](https://image.slidesharecdn.com/better2-140211042048-phpapp02/75/Lowering-STM-Overhead-with-Static-Analysis-10-2048.jpg)
![LOAD ELIMINATION IN ATOMIC BLOCKS. 1
for (int j = 0; j < nfeatures; j++) {
new_centers[index][j] = new_centers[index][j]
+ feature[i][j];
}
Key
insight:
No
need to check if new_centers[index]
can change in other threads.
Still
need to check that it cannot
change locally or through method
calls.](https://image.slidesharecdn.com/better2-140211042048-phpapp02/75/Lowering-STM-Overhead-with-Static-Analysis-11-2048.jpg)
![SCALAR PROMOTION IN ATOMIC BLOCKS. 2
for (int i = 0; i < num_elts; i++) {
moments[0] += data[i];
}
num_elts
instrumented
memory writes
(using Scalar Promotion)
if (0 < num_elts) {
double temp = moments[0];
try {
for (int i = 0; i < num_elts; i++) {
temp += data[i];
}
} finally {
moments[0] = temp;
}
instrumented
}
1
memory write](https://image.slidesharecdn.com/better2-140211042048-phpapp02/75/Lowering-STM-Overhead-with-Static-Analysis-12-2048.jpg)
![SCALAR PROMOTION IN ATOMIC BLOCKS. 2
for (int i = 0; i < num_elts; i++) {
moments[0] += data[i];
}
(same)
Key insight:
No
need to check if moments[0] can change
in other threads.
Still
need to check that it cannot
change locally or through method
calls.](https://image.slidesharecdn.com/better2-140211042048-phpapp02/75/Lowering-STM-Overhead-with-Static-Analysis-13-2048.jpg)




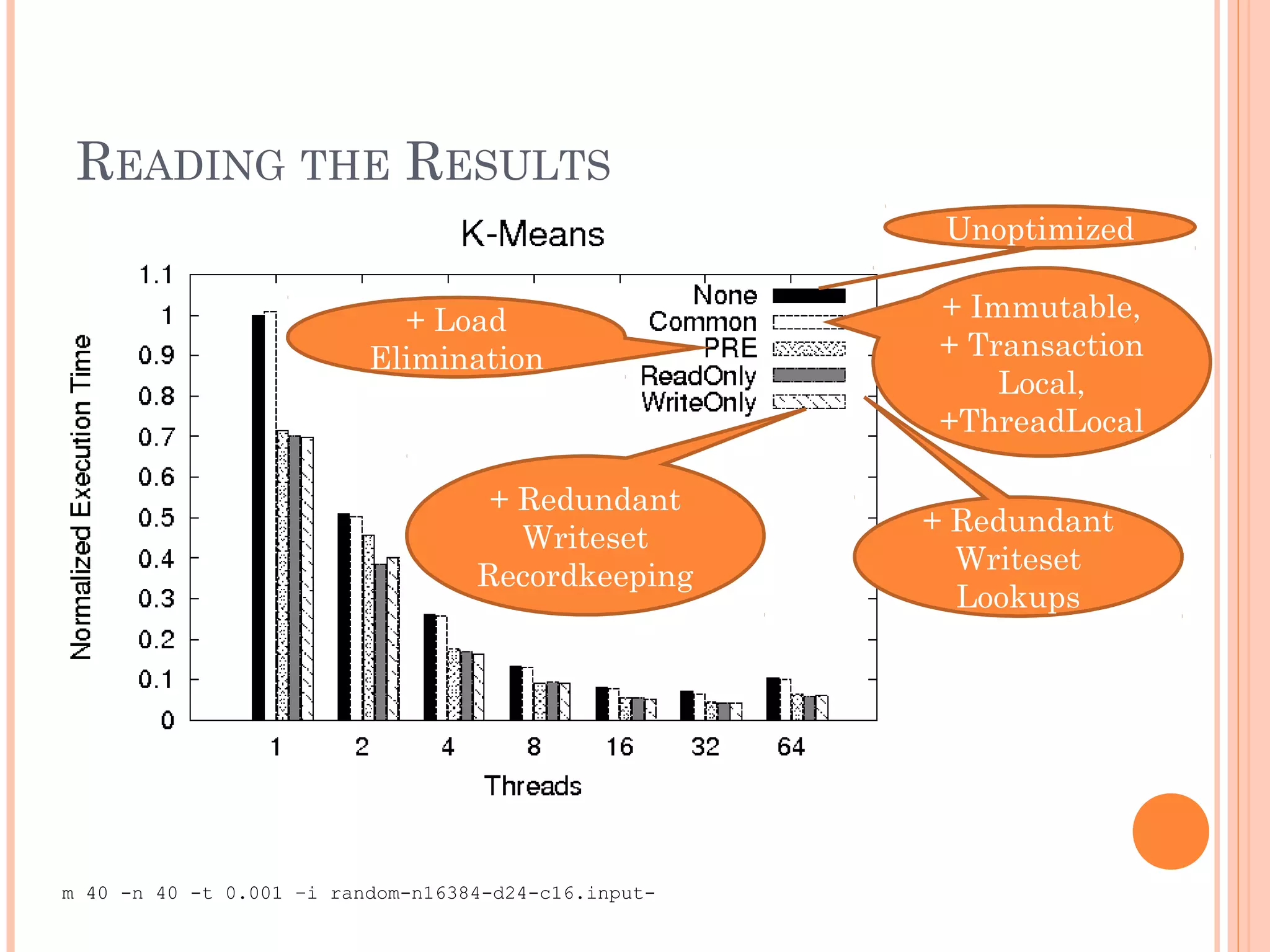
![RESULTS: K-MEANS
Load
Elimination
inside tight
loops
(e.g.,
new_centers
[index]
from the
example).
m 40 -n 40 -t 0.001 –i random-n16384-d24-c16.input-](https://image.slidesharecdn.com/better2-140211042048-phpapp02/75/Lowering-STM-Overhead-with-Static-Analysis-19-2048.jpg)
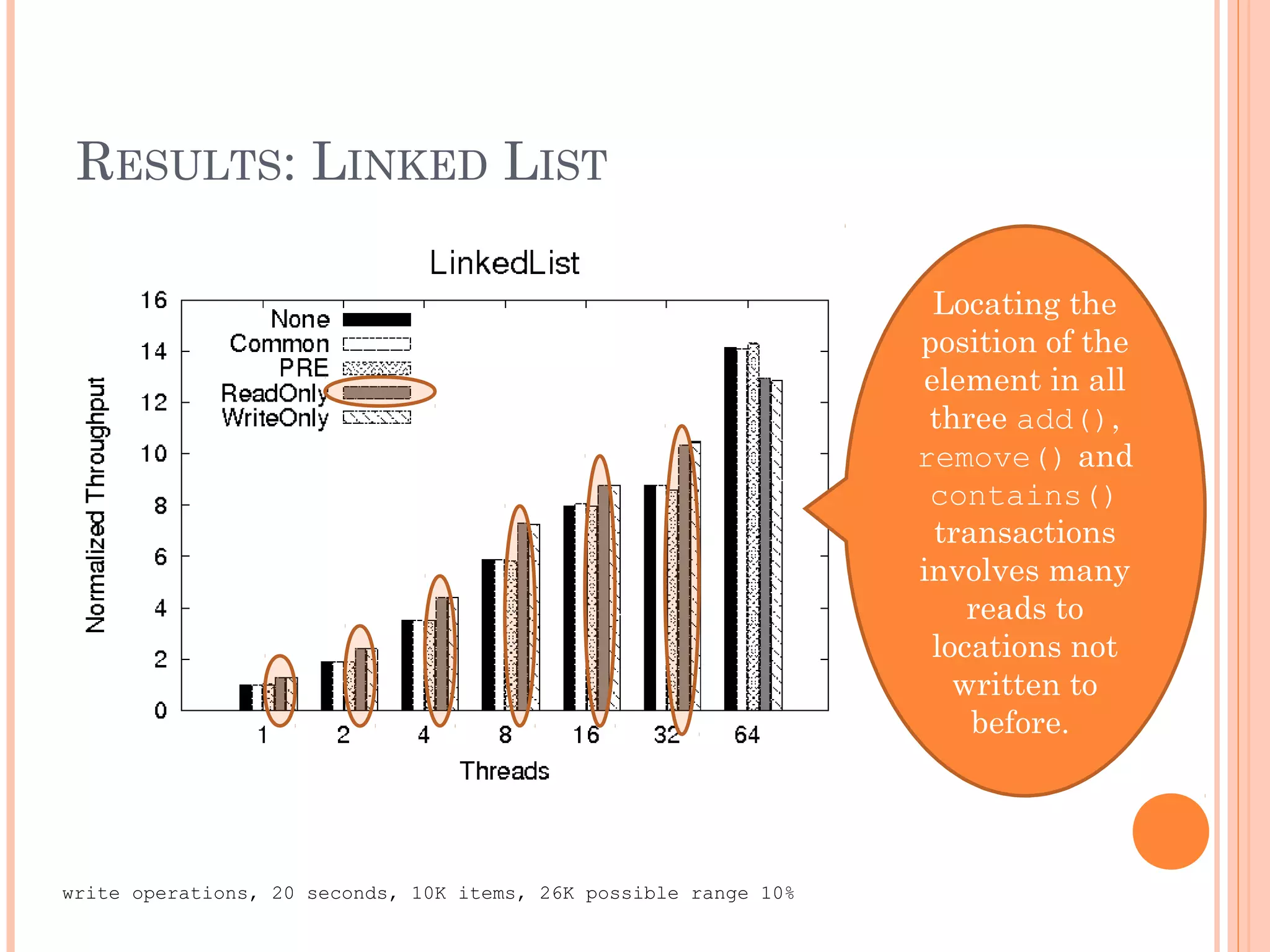
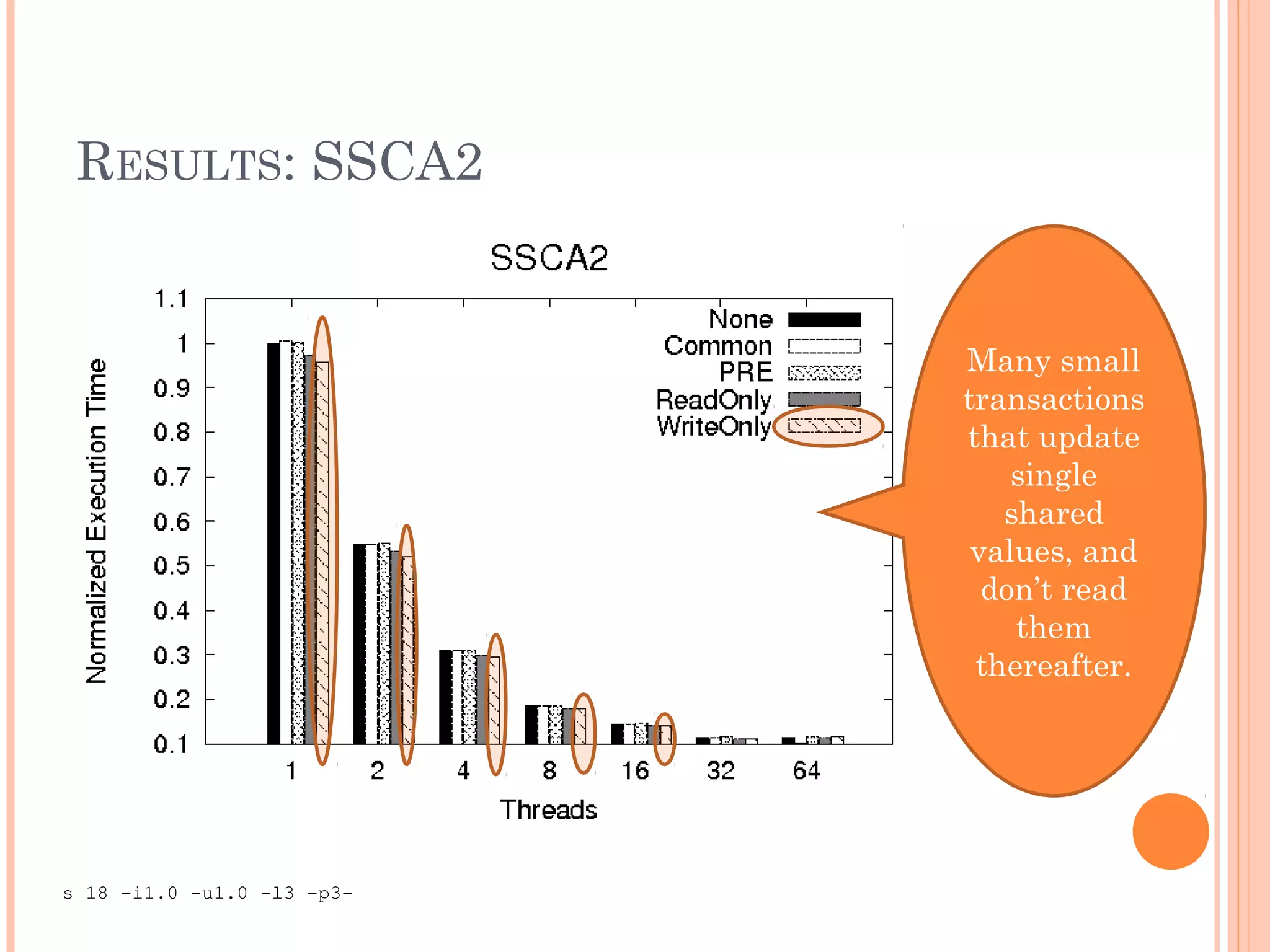





The document discusses methods to reduce the overhead associated with software transactional memory (STM) through static analysis and compiler optimizations. It presents four new optimizations aimed at minimizing instrumented memory accesses, reducing writeset lookups, and enhancing transaction performance, particularly within lazy-update STM protocols like TL2. Experimental results indicate significant performance improvements, with load elimination resulting in up to 29% speedup in specific transaction scenarios.





















![[Sitcon2018] Analysis and Improvement of IOTA PoW Implementation](https://cdn.slidesharecdn.com/ss_thumbnails/sitcon2018analysisandimprovementofiotapowimplementation-180306085230-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)
































