





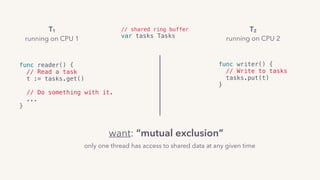
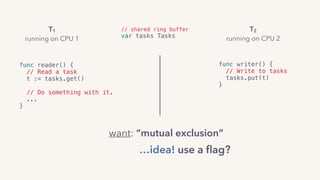





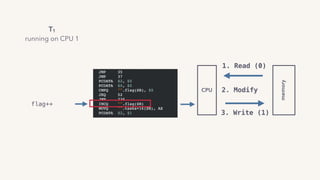
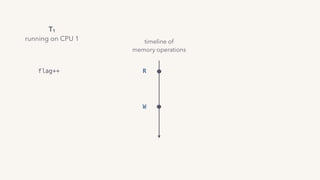
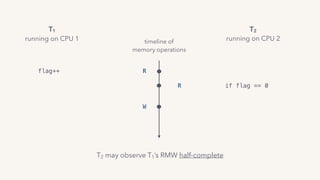


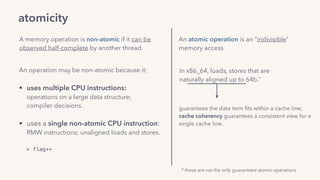























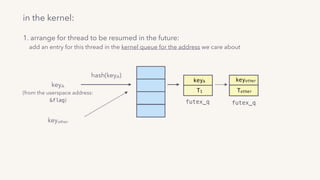
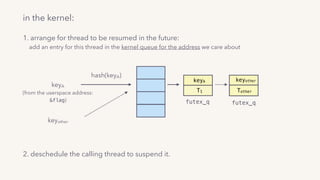











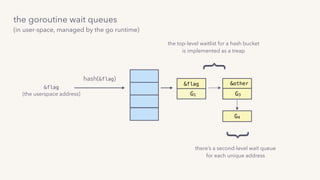

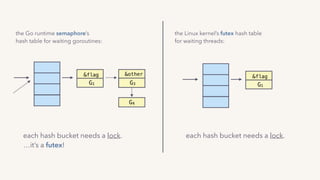
![G2’s done
(accessing the shared data)
G2
func writer() {
for {
if atomic.CompareAndSwap(&flag, 0, 1) {
...
// Set flag to unlocked.
atomic.Xadd(&flag, ...)
// If there’s a waiter, reschedule it.
waiter := root.dequeue(&flag)
goready(waiter)
return
}
root.queue()
gopark()
}
}
find the first waiter goroutine and reschedule it
]](https://image.slidesharecdn.com/untitled-190920083942/85/Let-s-Talk-Locks-71-320.jpg)







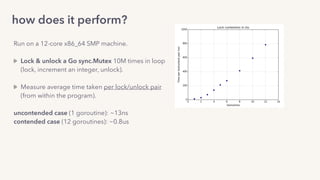
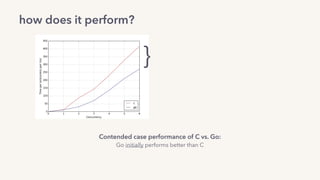
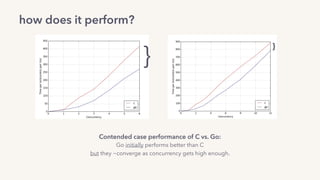

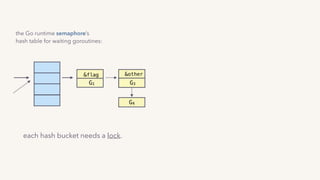
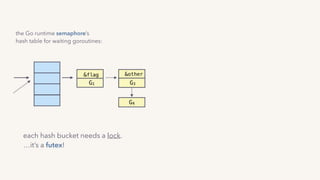








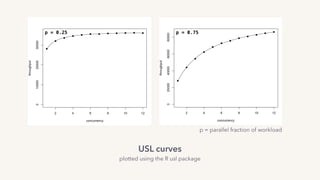




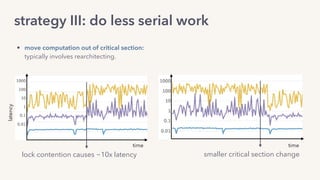




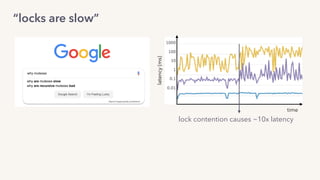
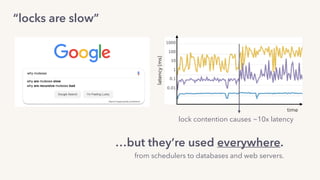
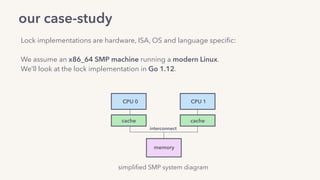
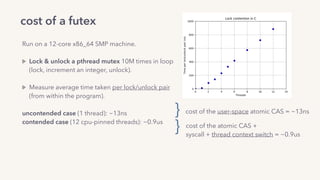
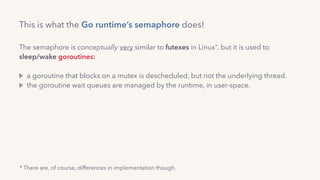
The document discusses the challenges of lock contention in computing, emphasizing its impact on system latency and the implementation of locks in programming languages like Go. It introduces atomic operations, memory reordering, and futexes as solutions to provide efficient mutual exclusion and synchronization among threads. The document also highlights the balance between CPU resource utilization and context switching to optimize performance in concurrent programming.