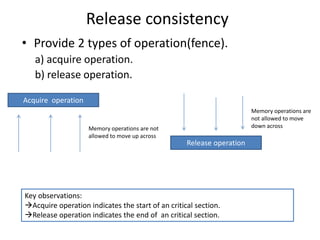
Here are the key points about the C++11 memory model and ordering:
- The C++ memory model aims to balance performance and correctness for concurrent programs. It allows optimizations but prevents data races.
- Operations on atomic types have memory ordering properties that restrict how instructions can be reordered with respect to other threads.
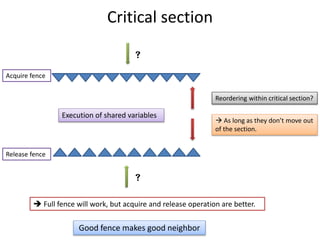
- A release fence prevents writes from moving past the fence. An acquire fence prevents reads from moving before the fence.
- For the code snippet shown, a thread reading flag needs to ensure it sees the write to data. This requires an acquire fence after loading flag to prevent the load from moving above the write to data.
So the correct answer is that it needs an acquire fence after loading flag




![Memory model(Consistency Model)
• “the memory model specifies the allowed
behavior of multithreaded programs executing
with shared memory.”[1]
• “consistency(memory model) provide rules
about loads and stores and how they act upon
memory.”[1]
A contract between software and hardware.](https://image.slidesharecdn.com/memorymodel-141214022831-conversion-gate02/85/Memory-model-4-320.jpg)



![Optimizations
Z = 3
Y = 2
X = 1
// use X , Y, Z
X = 1
Y = 2
Z = 3
// use X ,Y, Z
X = 1
Y = 2
X = 3
// use X and Y
Y = 2
X = 3
// use X and Y
for(i = 0; i < cols; ++i)
for(j = 0; j < rows; ++j)
a[j*rows + i] += 42;
for(j = 0; j < rows; ++j)
for(i = 0; i < cols; ++i)
a[j*rows + i] += 42;
Optimizations are ubiquitous: compiler, processor will do whatever they
see fit to optimize your code to improve performance.](https://image.slidesharecdn.com/memorymodel-141214022831-conversion-gate02/85/Memory-model-8-320.jpg)





![How does ordering matter?
• One more try, Peterson’s algorithm on x86/64.
int g_victim;
bool g_flag[2];
void lock1()
{
g_flag[o] = true;
g_victim = 0;
while (g_flag[1] && g_victim == 0);
// lock acquired.
}
void unlock1()
{
g_flag[0] = false;
}
void lock2()
{
g_flag[1] = true;
g_victim = 1;
while (g_flag[0] && g_victim == 1);
// lock acquired.
}
void unlock2()
{
g_flag[1] = false;
}
Thread 0
Store(g_flag[0])
Store(g_victim)
Load(g_flag[1])
Load(g_victim)
Thread 1
Store(g_flag[1])
Store(g_victim)
Load(g_flag[0])
Load(g_victim)](https://image.slidesharecdn.com/memorymodel-141214022831-conversion-gate02/85/Memory-model-20-320.jpg)




![c++11 atomic
• Operations on atomic type are performed atomically, AKA, synchronization operations.
• User can specify the memory ordering for every load & store.
template <class T> struct atomic {
bool is_lock_free() const noexcept;
void store(T, memory_order = memory_order_seq_cst) noexcept;
T load(memory_order = memory_order_seq_cst) const noexcept;
T exchange(T, memory_order = memory_order_seq_cst) noexcept;
bool compare_exchange_weak(T&, T, memory_order, memory_order) noexcept;
bool compare_exchange_strong(T&, T, memory_order, memory_order) noexcept;
bool compare_exchange_weak(T&, T, memory_order = memory_order_seq_cst) noexcept;
bool compare_exchange_strong(T&, T, memory_order = memory_order_seq_cst) noexcept;
};
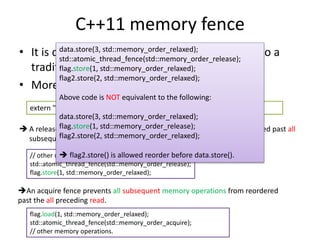
Synchronization operations specify how assignments in one thread visible to another.
[c++ standard: 1.10.5]](https://image.slidesharecdn.com/memorymodel-141214022831-conversion-gate02/85/Memory-model-26-320.jpg)

![Acquire/release and Consume/release
atomic<int> guard(0);
int pay_load = 0;
// thread 0
pay_load = 1;
guard.store(1, memory_order_release);
// thread 1
int pay;
int g = guard.load(memory_order_acquire);
If (g) pay = pay_load;
atomic<int*> guard(0);
int pay_load = 0;
// thread 0
pay_load = 1;
guard.store(&pay_load, memory_order_release);
// thread 1
int pay;
Int* g = guard.load(memory_order_consume);
If (g) pay = *g;
g mush carry a dependency to pay = *g
data dependency
On most weak-order architectures, memory ordering between data dependent
instructions is preserved, in such case explicit memory fence is not necessary.[7]](https://image.slidesharecdn.com/memorymodel-141214022831-conversion-gate02/85/Memory-model-28-320.jpg)
![memory_order_seq_cst
• Order memory operation the same way as release and
acquire.
• Establish a single total order on all memory_order_seq_cst
operations.
Suppose x,y are atomic variables and are initialized to 0.[6]
Thread 1
x = 1
Thread 2
y = 1
Thread 3
if (y = 1 && x == 0)
cout << “y first”;
Thread 4
if (y = 0 && x == 1)
cout << “x first”;
Must not allow to print both messages.](https://image.slidesharecdn.com/memorymodel-141214022831-conversion-gate02/85/Memory-model-29-320.jpg)
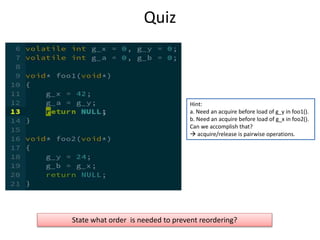
![Quiz: Peterson’s algo again.
atomic<int> g_victim;
atomic<bool> g_flag[2];
void lock1()
{
g_flag[o].store(true, ?);
g_victim.store(0, ?);
while (g_flag[1].load(?) && g_victim.load(?) == 0);
// lock acquired.
}
void unlock1()
{
g_flag[0].store(false, ?);
}
Thread 0
Store(g_flag[0])
Store(g_victim)
Load(g_flag[1])
Load(g_victim)
Thread 1
Store(g_flag[1])
Store(g_victim)
Load(g_flag[0])
Load(g_victim)
atomic<int> g_victim;
atomic<bool> g_flag[2];
void lock1()
{
g_flag[o].store(true, memory_order_relaxed);
g_victim.exchange(0, memory_order_acq_rel);
while (g_flag[1].load(memory_order_acquire)
&& g_victim.load(memory_order_relaxed) == 0);
// lock acquired.
}
void unlock1()
{
g_flag[0].store(false, memory_order_release);
}
Atomic read-modify-write operations shall always read the last value (in the modification order) written
before the write associated with the read-modify-write operation.[standard §29.3.12]](https://image.slidesharecdn.com/memorymodel-141214022831-conversion-gate02/85/Memory-model-32-320.jpg)
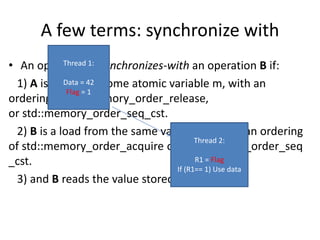
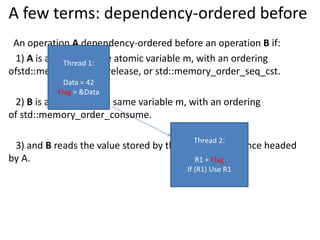
![A few terms: happen before
Sequence before: the order of evaluations within a single thread
Or synchronize with.
Or dependency-ordered before.
Or concatenations of the above 3 relationships
with 2 exceptions.[standard 1.10.11]
happen-before indicates visibility.](https://image.slidesharecdn.com/memorymodel-141214022831-conversion-gate02/85/Memory-model-35-320.jpg)

![Further reading
• [1]https://class.stanford.edu/c4x/Engineering/CS316/asset/A_Primer_on_M
emory_Consistency_and_Coherence.pdf
• [2]http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=F2BAAAED623
D54B73C5FF41DF14D5864?doi=10.1.1.17.8112&rep=rep1&type=pdf
• [3]http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2006/n2075.pdf
• [4]http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2006/n1942.html
• [5]http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2008/n2664.htm
• [5]http://open-std.org/jtc1/sc22/wg21/docs/papers/2007/n2427.html
• [6]http://channel9.msdn.com/Shows/Going+Deep/Cpp-and-Beyond-2012-
Herb-Sutter-atomic-Weapons-1-of-2
• [7]https://www.kernel.org/doc/Documentation/memory-barriers.txt
• [8]www.preshing.com](https://image.slidesharecdn.com/memorymodel-141214022831-conversion-gate02/85/Memory-model-37-320.jpg)





























































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)



![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)

