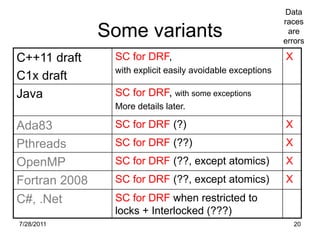
The document discusses the challenges of defining memory models for shared memory parallel programs. It argues that there is emerging consensus around an interleaving semantics called Sequential Consistency, but only for programs that are free of data races. This allows for important compiler and hardware optimizations while restricting reordering around synchronization. However, languages like Java cannot outlaw all data races, so the meaning of programs with races remains unclear. The document explores some speculative solutions to address this major open problem.














































![Much nicer than prior attempts, but:
• Aspinall, Sevcik, “Java Memory Model Examples: Good,
Bad, and Ugly”, VAMP 2007 (also ECOOP 2008 paper)
Quotation from above paper omitted, to avoid possible
copyright questions. This ends in the statement:
“This falsifies Theorem 1 of [paper from previous slide].”
Note: The underlying observation is due to Pietro Cenciarelli.
7/28/2011 47](https://image.slidesharecdn.com/boehm-ecoop-no-quotes-110801132112-phpapp02/85/Programming-Language-Memory-Models-What-do-Shared-Variables-Mean-47-320.jpg)







![Introducing Races:
Register Promotion 2
r = g;
for(...) {
[g is global] if(mt) {
for(...) { g = r; lock(); r = g;
}
if(mt) lock();
use/update r instead of g;
use/update g; if(mt) {
if(mt) unlock(); g = r; unlock(); r = g;
}
}
}
g = r;
7/28/2011 55](https://image.slidesharecdn.com/boehm-ecoop-no-quotes-110801132112-phpapp02/85/Programming-Language-Memory-Models-What-do-Shared-Variables-Mean-55-320.jpg)

![Some open source pthread lock
implementations (2006):
lock() lock() lock() lock()
unlock() unlock() unlock() unlock()
[technically incorrect] [Correct, slow] [Correct] [Incorrect]
NPTL NPTL NPTL FreeBSD
{Alpha, PowerPC} Itanium (&X86) { Itanium, X86 } Itanium
{mutex, spin} mutex spin spin
7/28/2011 57](https://image.slidesharecdn.com/boehm-ecoop-no-quotes-110801132112-phpapp02/85/Programming-Language-Memory-Models-What-do-Shared-Variables-Mean-57-320.jpg)










































































