More Related Content

PDF

PPTX

PDF

PPTX
forestFloorパッケージを使ったrandomForestの感度分析 
PDF

PDF

KEY

PDF
Active Learning from Imperfect Labelers @ NIPS読み会・関西 What's hot

PPTX
Interpreting Tree Ensembles with inTrees 
PDF

PPTX
Pythonとdeep learningで手書き文字認識 
PDF
LCCC2010:Learning on Cores, Clusters and Cloudsの解説 
PDF
Decision Transformer: Reinforcement Learning via Sequence Modeling 
PPTX
Imputation of Missing Values using Random Forest 
PDF

PDF

PPTX
Dimensionality reduction with t-SNE(Rtsne) and UMAP(uwot) using R packages. 
PDF
最近のRのランダムフォレストパッケージ -ranger/Rborist- 
PDF
ランダムフォレストとそのコンピュータビジョンへの応用 
PDF

PDF

PDF

PDF

PDF
![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Deep Learning 第5章 機械学習の基礎 
PDF

PDF

PDF
Viewers also liked

PPTX
Introduction of "the alternate features search" using R 
DOCX
Aspectos formales de un documento aitana gomez vallejo 
PPTX

DOCX
Ciencia tecnica y arte paula grisales 
PDF
Naskah simposium gtk 2016 sumarso 
PDF
Acil Durum Ekip ve Destek Elemanları Eğitimi 
PPTX

PDF
Westminster Communities of Florida's 2016 Volunteers and Employees of the Year 
PDF
Brochure Studio HS Milano 
PDF
Renovación del corazón y el alma de su hogar 
PPT
Bab 6-sumber-sumber-hukum-islam2 
ODT
Antónimos y palabras clave 
PPTX
The Brief History of the Film - Albert James Burleson 
PDF
Boletín IgualSí Nº 5 | Marzo 2017 Similar to Deep forest (preliminary ver.)

PPTX

PDF
Deep Forest: Towards An Alternative to Deep Neural Networks 
PDF
Lispmeetup #50 cl-random-forest: Common Lispによるランダムフォレストの実装 
PDF
(公開版)FPGAエクストリームコンピューティング2017 
PDF
「樹木モデルとランダムフォレスト-機械学習による分類・予測-」-データマイニングセミナー 
PPTX
Introduction of featuretweakR package 
PPTX
Intoroduction & R implementation of "Interpretable predictions of tree-based ... 
PPTX

PDF
シリーズML-03 ランダムフォレストによる自動識別 
PDF
Deep Learning Implementations: pylearn2 and torch7 (JNNS 2015) 
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models 
PPTX
32bit Windowsで頑張るRandom Forest 
PPTX
![[DL輪読会]Training RNNs as Fast as CNNs](https://cdn.slidesharecdn.com/ss_thumbnails/20171002dlhacks-171002105129-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Training RNNs as Fast as CNNs 
PDF
Basic deep learning_framework 
PDF

PPTX
JSAI's AI Tool Introduction - Deep Learning, Pylearn2 and Torch7 More from Satoshi Kato

PPTX
How to generate PowerPoint slides Non-manually using R 
PPTX
Exploratory data analysis using xgboost package in R 
PPTX
How to use in R model-agnostic data explanation with DALEX & iml 
PPTX
Introduction of inspectDF package 
PPTX
Genetic algorithm full scratch with R 
PPTX
Multiple optimization and Non-dominated sorting with rPref package in R 
PPTX
Oracle property and_hdm_pkg_rigorouslasso Deep forest (preliminary ver.)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
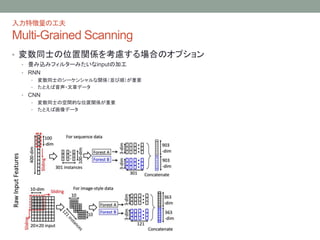
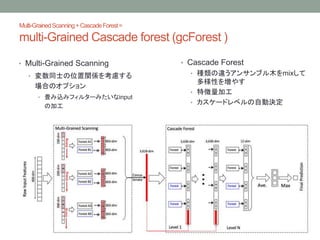
ランダムフォレストで表現学習
Cascade Forest
• 種類の違うアンサンブル木をmixして多様性を増やす
•complete-random tree forest
• 各ノードをランダムな変数で分割する決定木
• random forest
• ランダムに変数の絞り込みを行ったサブセットで、各ノードをジニ係数最大となる変数で分割していく決
定木
• 論文中ではシンプルに2×2の設定
• 特徴量加工
• レベル間で受け渡される中間インプットは、各フォレストが生成したクラス分布+元の特徴ベクトル
• たとえば、10変数3クラスのデータ、4フォレスト: 次のレベルが受けとる特徴の数は 3×4 + 10 = 22
• カスケードレベルの自動決定
• カスケード全体のパフォーマンスをcross-validationで評価
→ CVエラーが向上しなくなったレベルで訓練終了
- 7.
- 8.
- 9.
Q& A
Q. スタッキングとは違うの?
A.違うよ。全然違うよ。
• By 著者(in related works)
• 表現学習を行うだけでなく、適切なモデル複雑度を自動的に決定したい
→DeepForest
• 深層学習を使わないところもポイント(らしい)
- 10.
- 11.
- 12.
- 13.