Download as PDF, PPTX







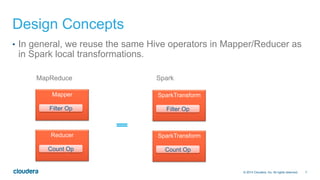

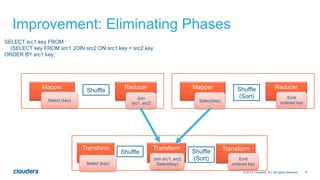
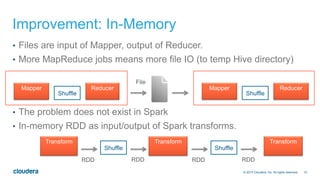



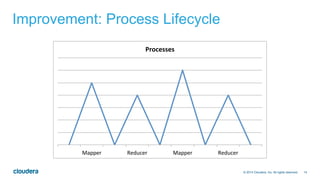
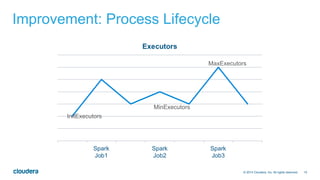








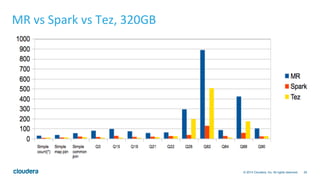
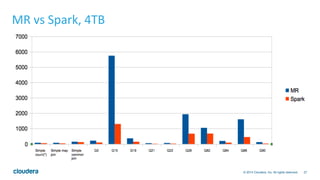
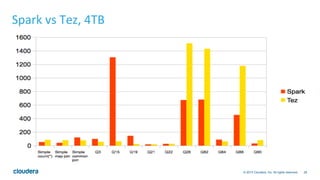






The document discusses the integration of Apache Hive with Spark, highlighting Hive's transition from using MapReduce to adopting Spark as an execution engine for improved performance. It emphasizes the benefits of Spark's in-memory data processing and efficient shuffling compared to MapReduce, as well as the seamless execution of Hive queries on Spark. Additionally, performance benchmarks demonstrate Spark's advantages in execution speed, while noting some scenarios where Tez outperforms Spark.



























































![[Deck] What's New in Spark-Iceberg Integration via DSV2.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deckwhatsnewinspark-icebergintegrationviadsv2-260210005337-25955b12-thumbnail.jpg?width=640&height=640&fit=bounds)



























