Download as PDF, PPTX





























![06.05.2014
2
Spark: RDD Operations
• Transformations - Create new datasets from
existing ones
• map(func)
• filter(func)
• sample(withReplacement,fraction, seed)
• union(otherDataset)
• distinct([numTasks]))
• groupByKey([numTasks])
• … … …
• Actions - Return a value to the client after running a
computation on the dataset
• reduce(func)
• count()
• first()
• foreach(func)
• saveAsTextFile(path)
• … … …](https://image.slidesharecdn.com/20140506hadoop2morethanmapreduceparallel-140507021824-phpapp01/75/Hadoop-2-More-than-MapReduce-46-2048.jpg)
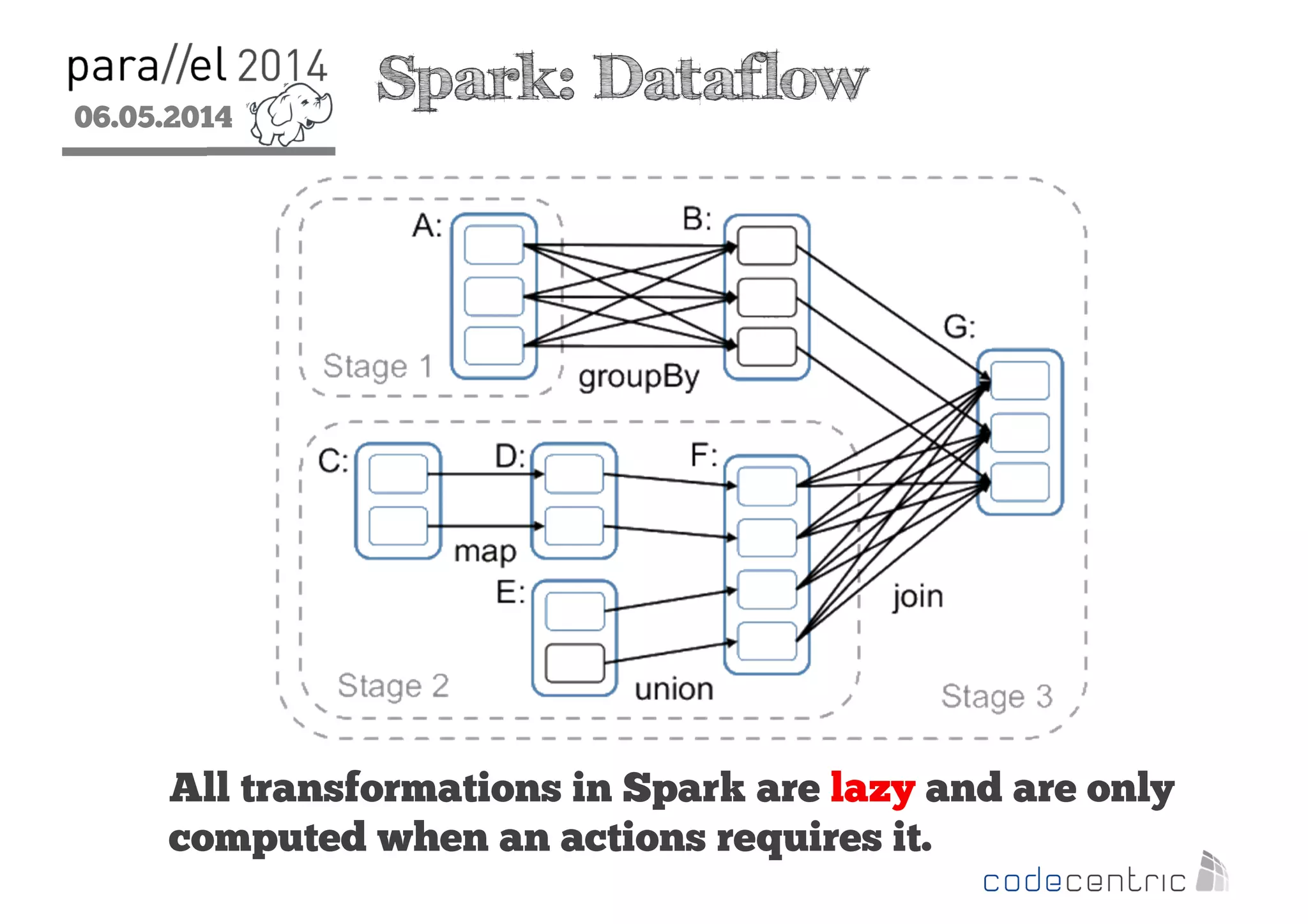



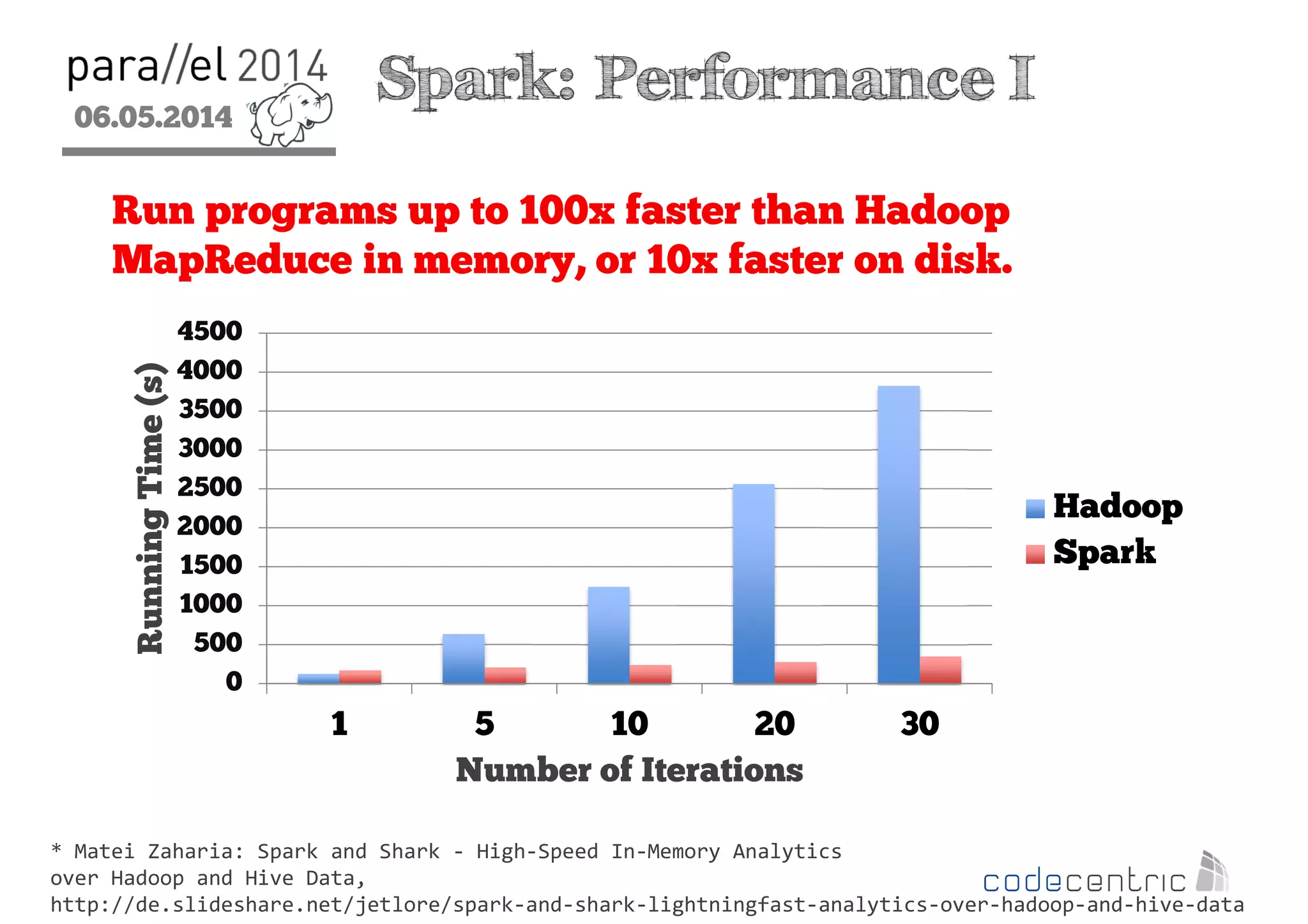
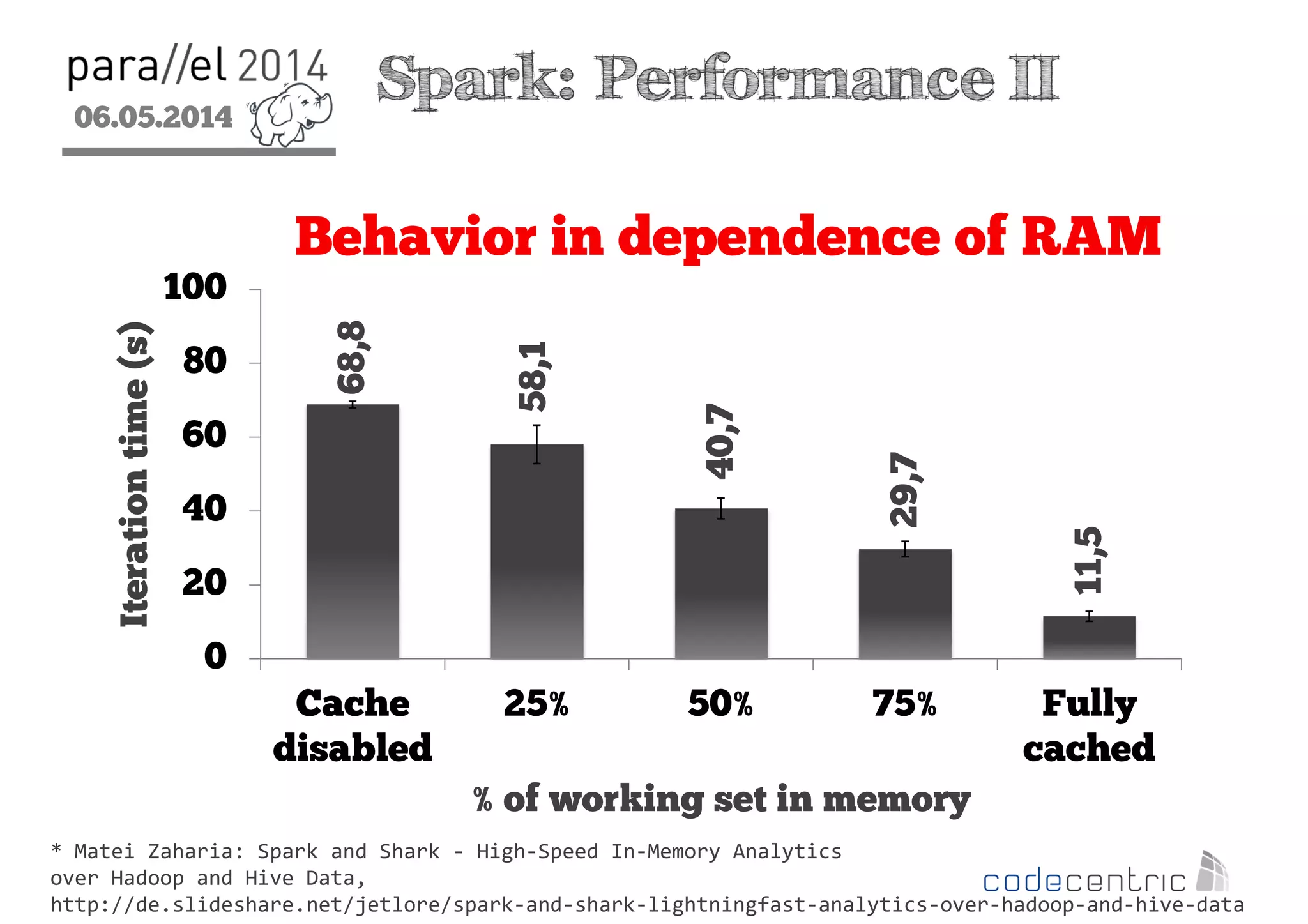







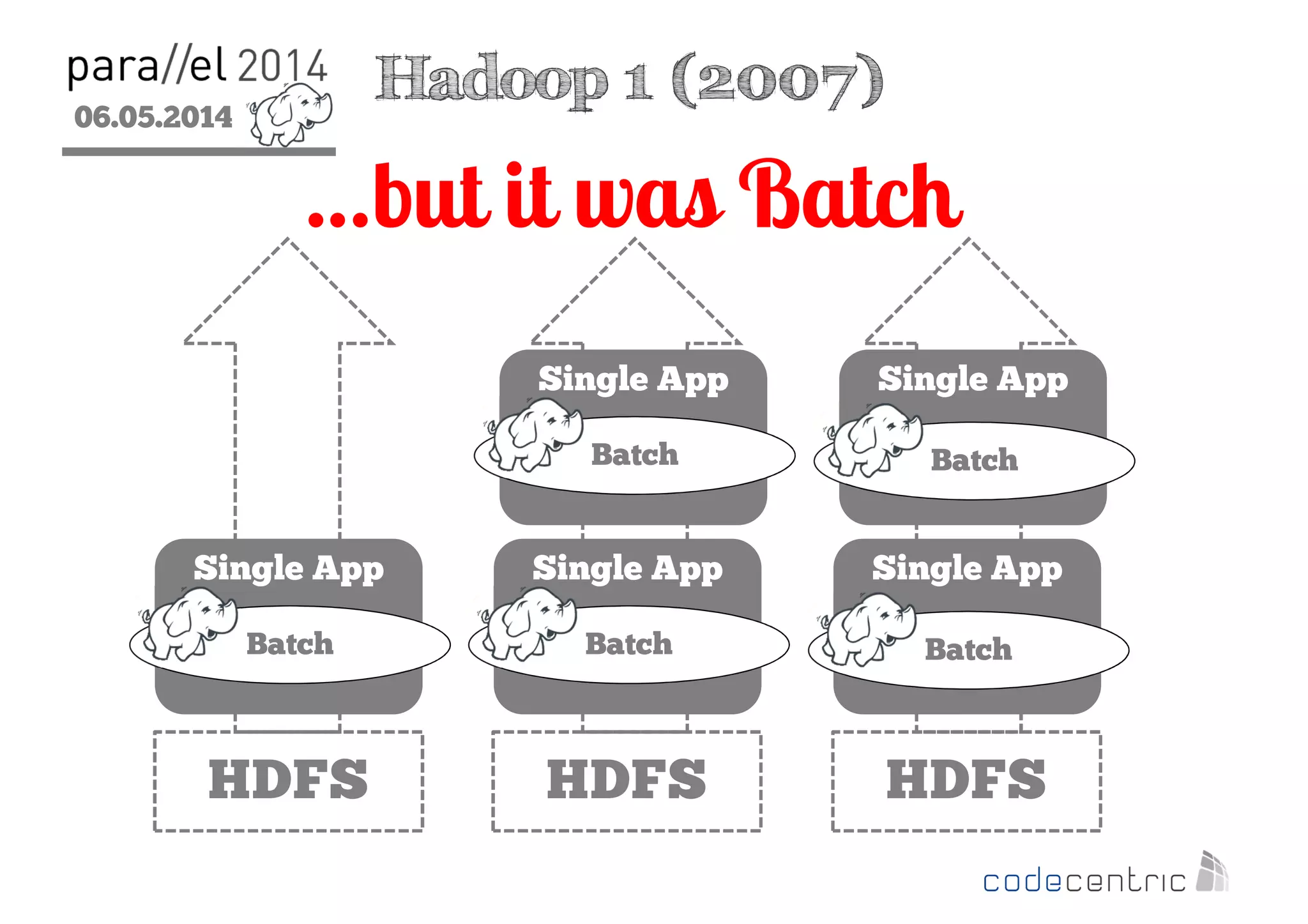
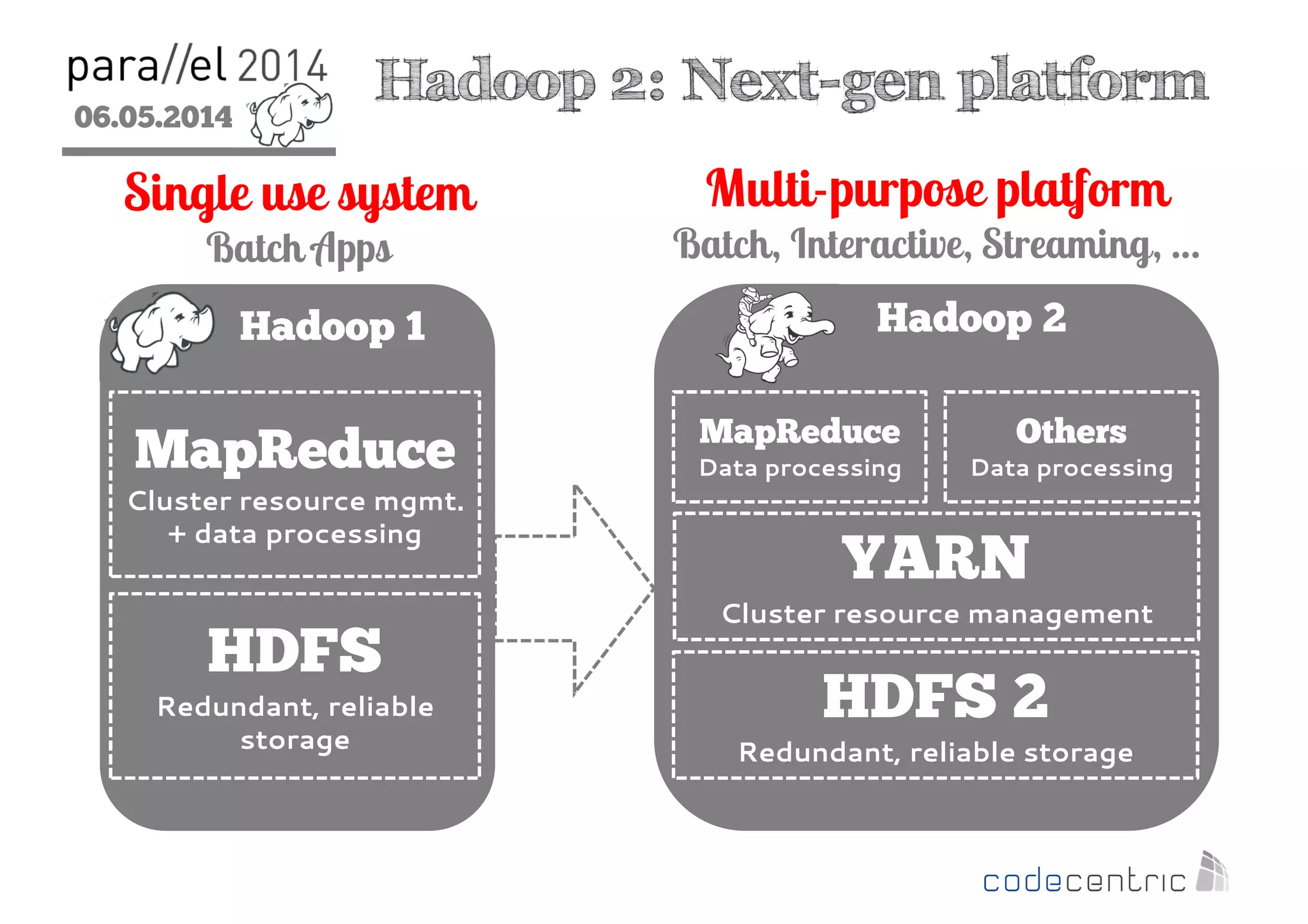
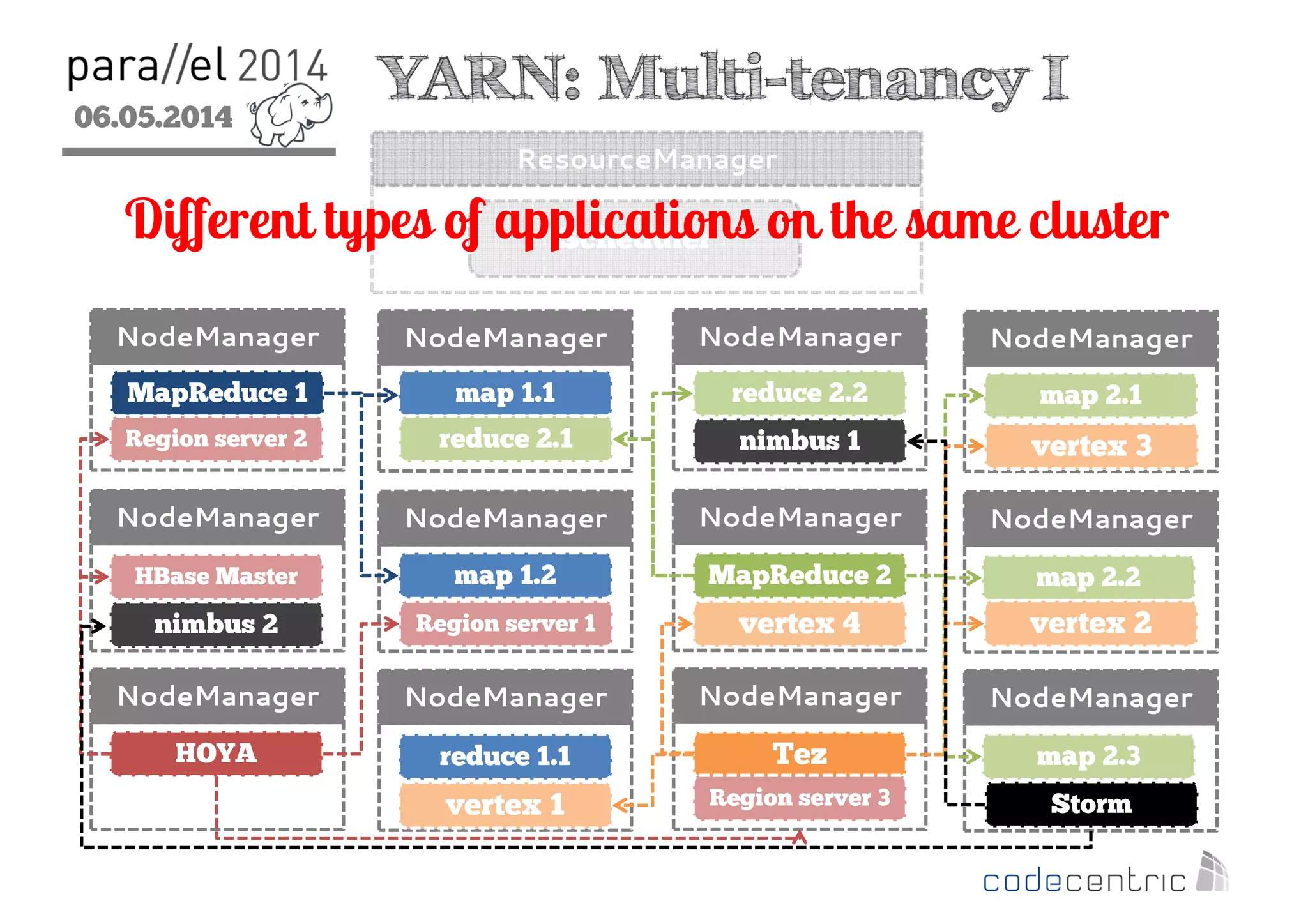
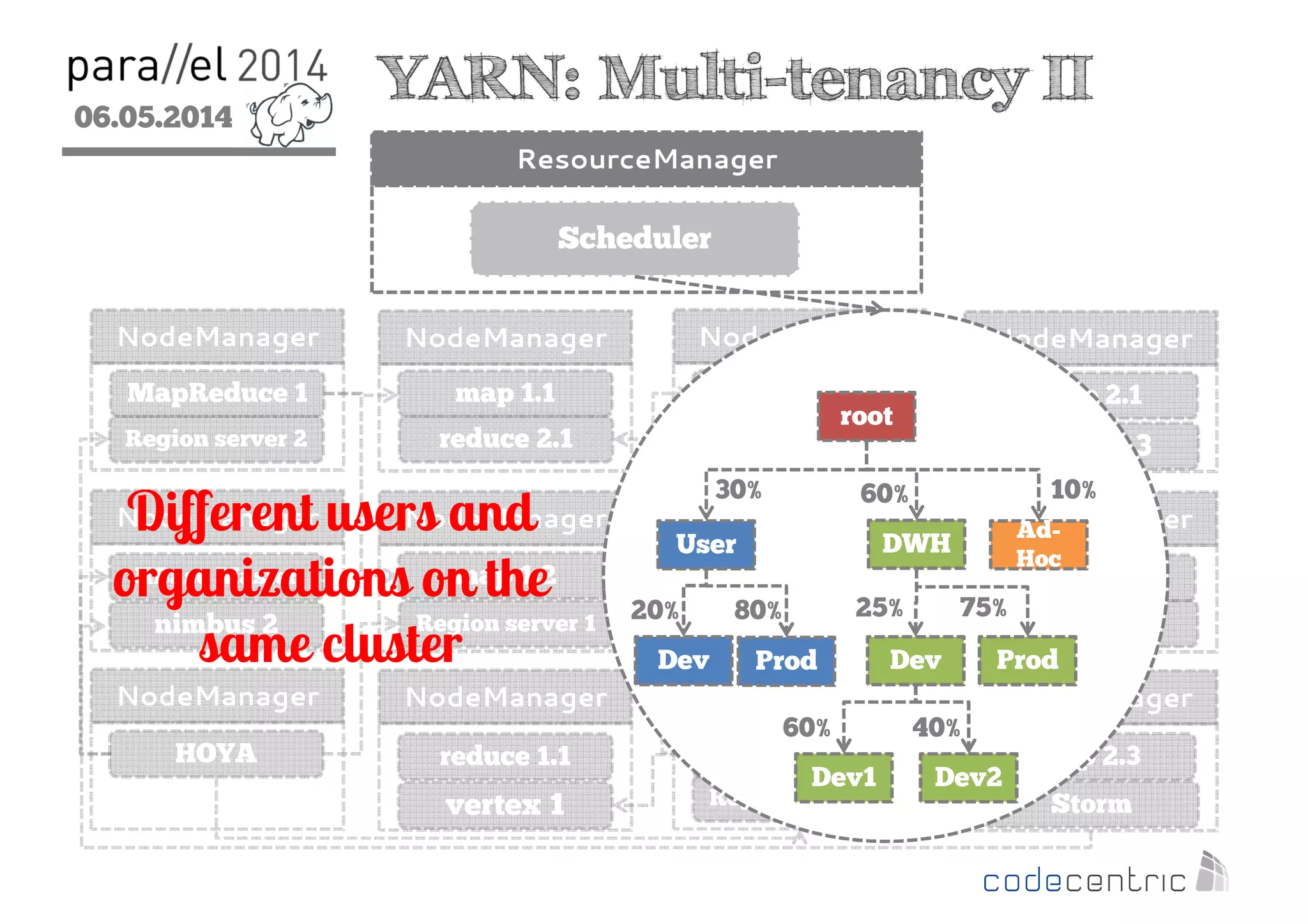
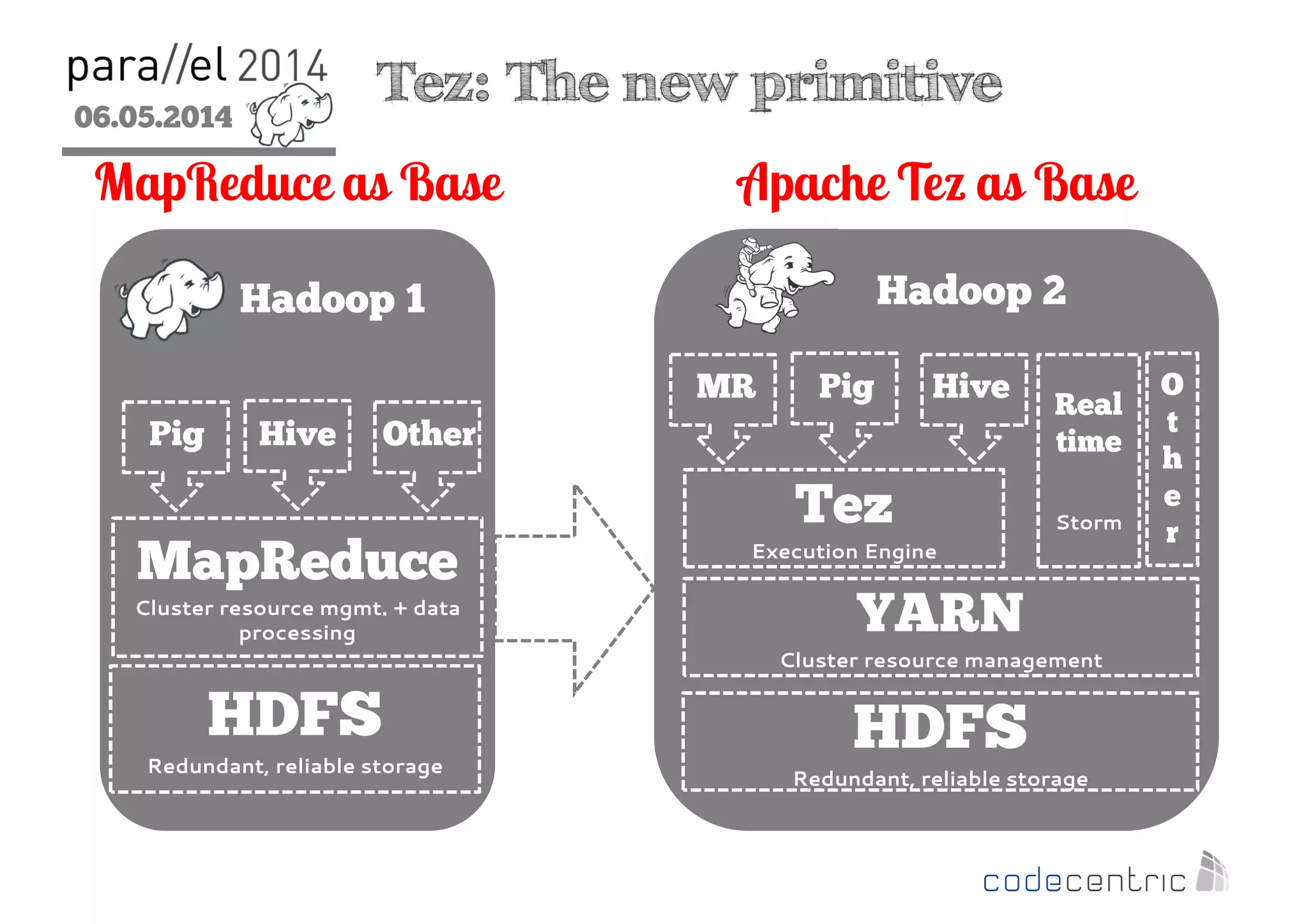
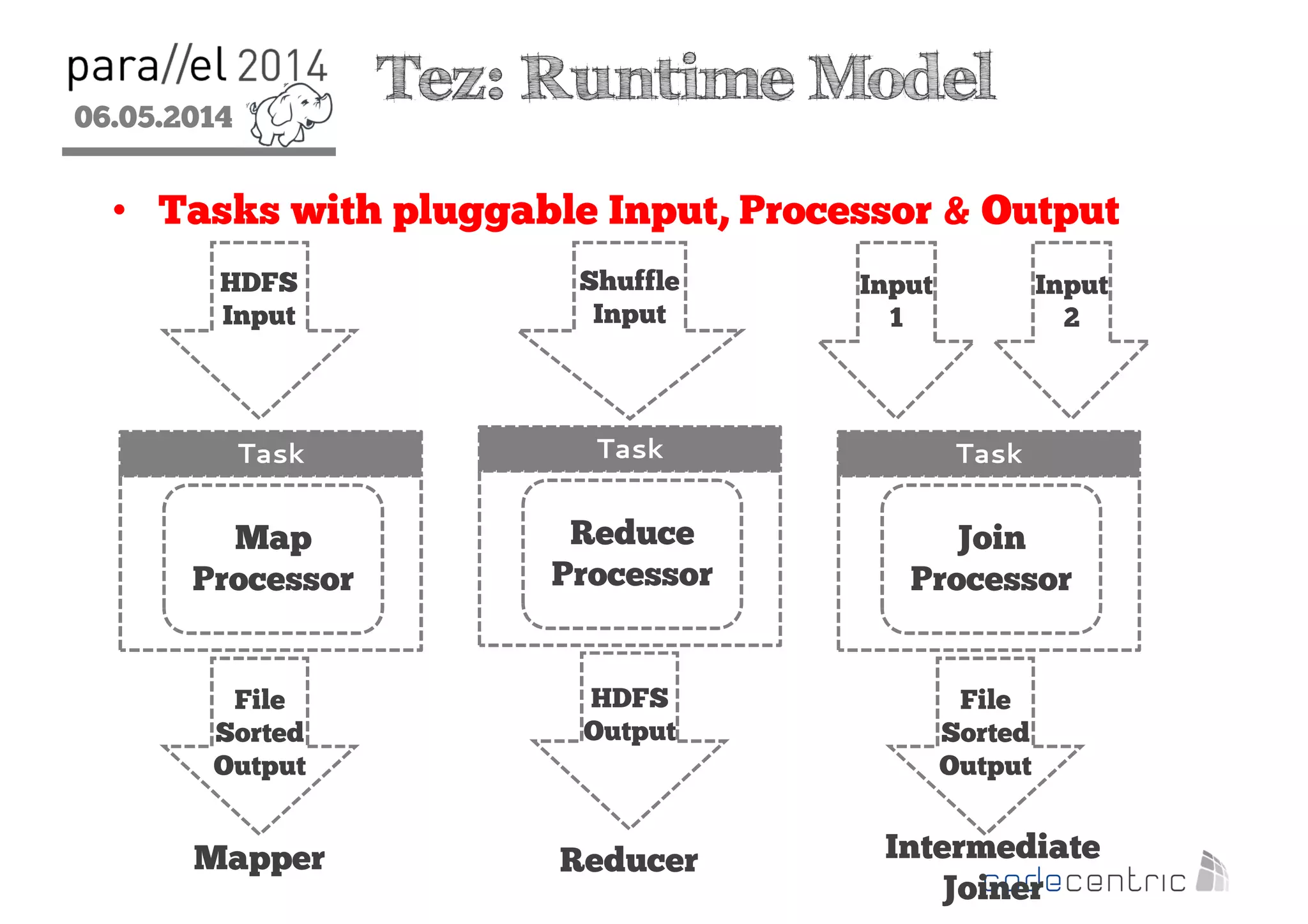
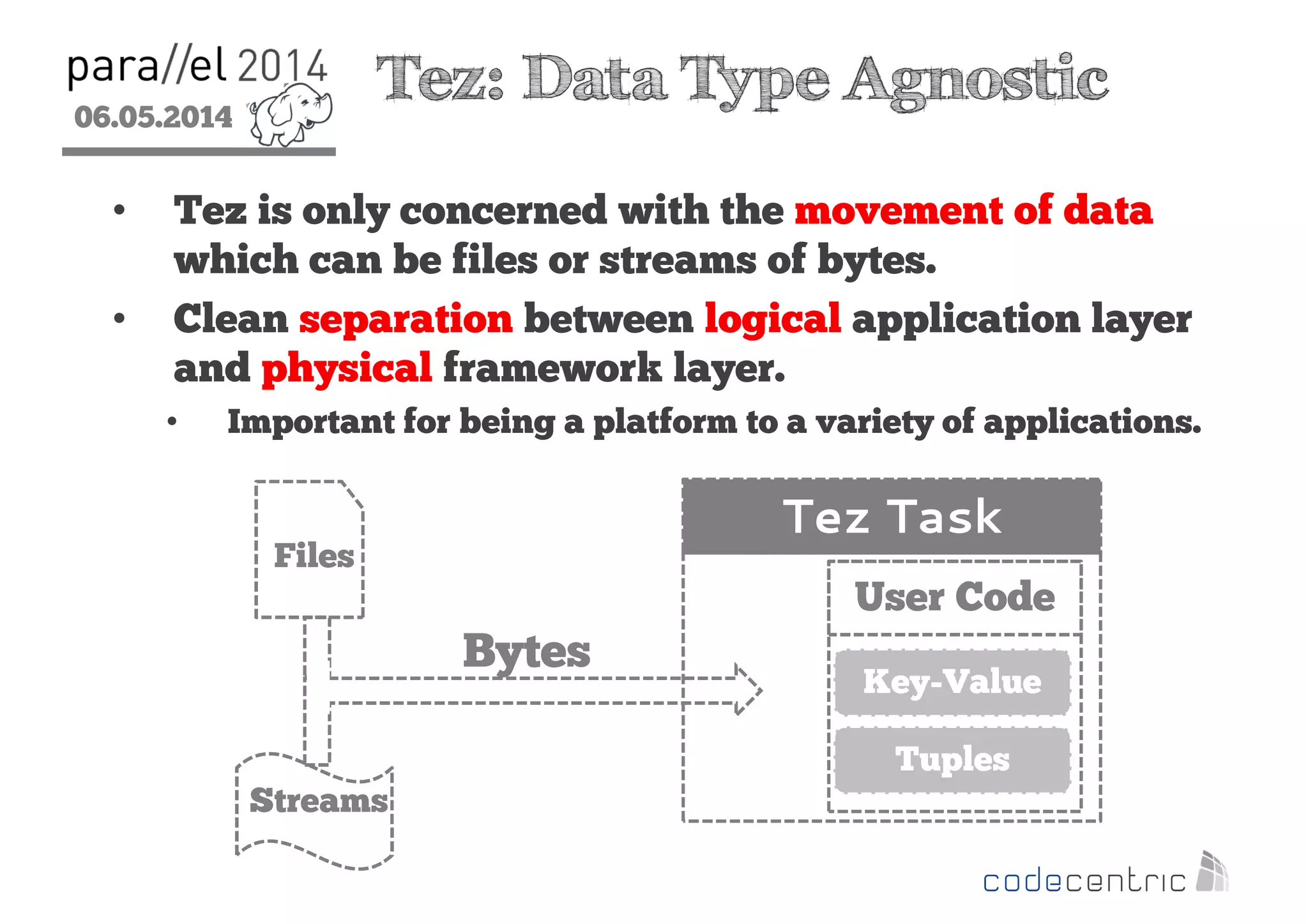
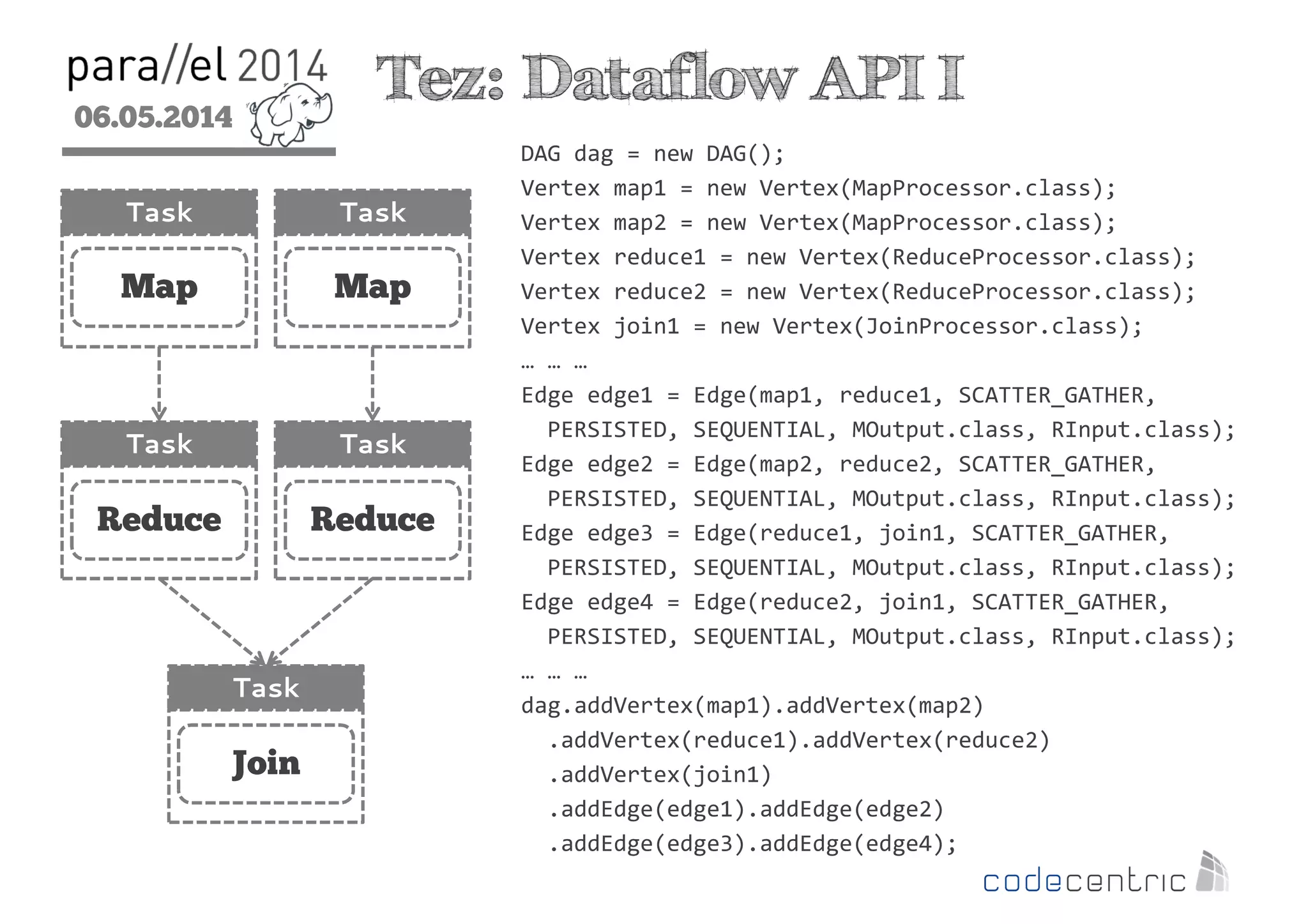
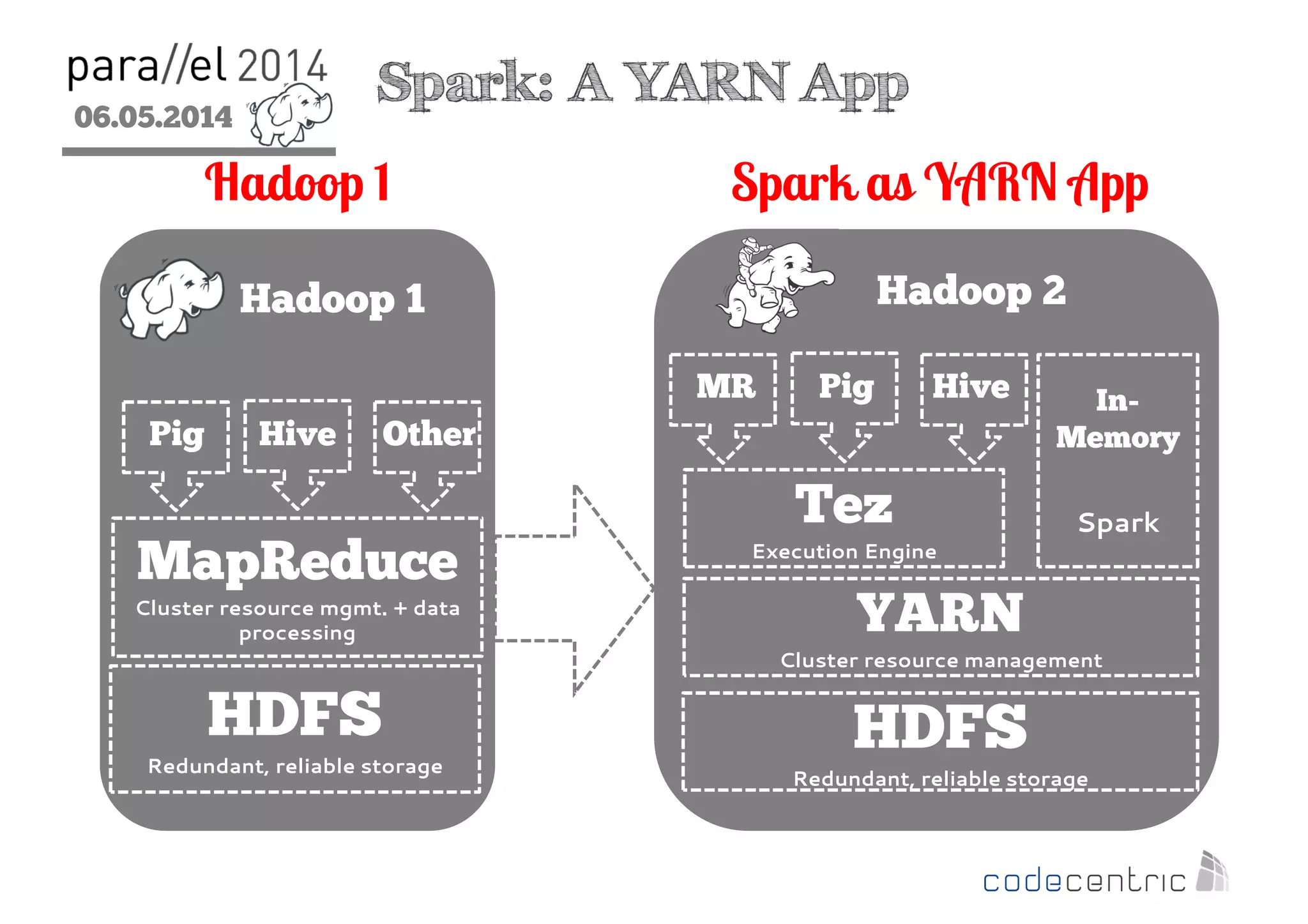
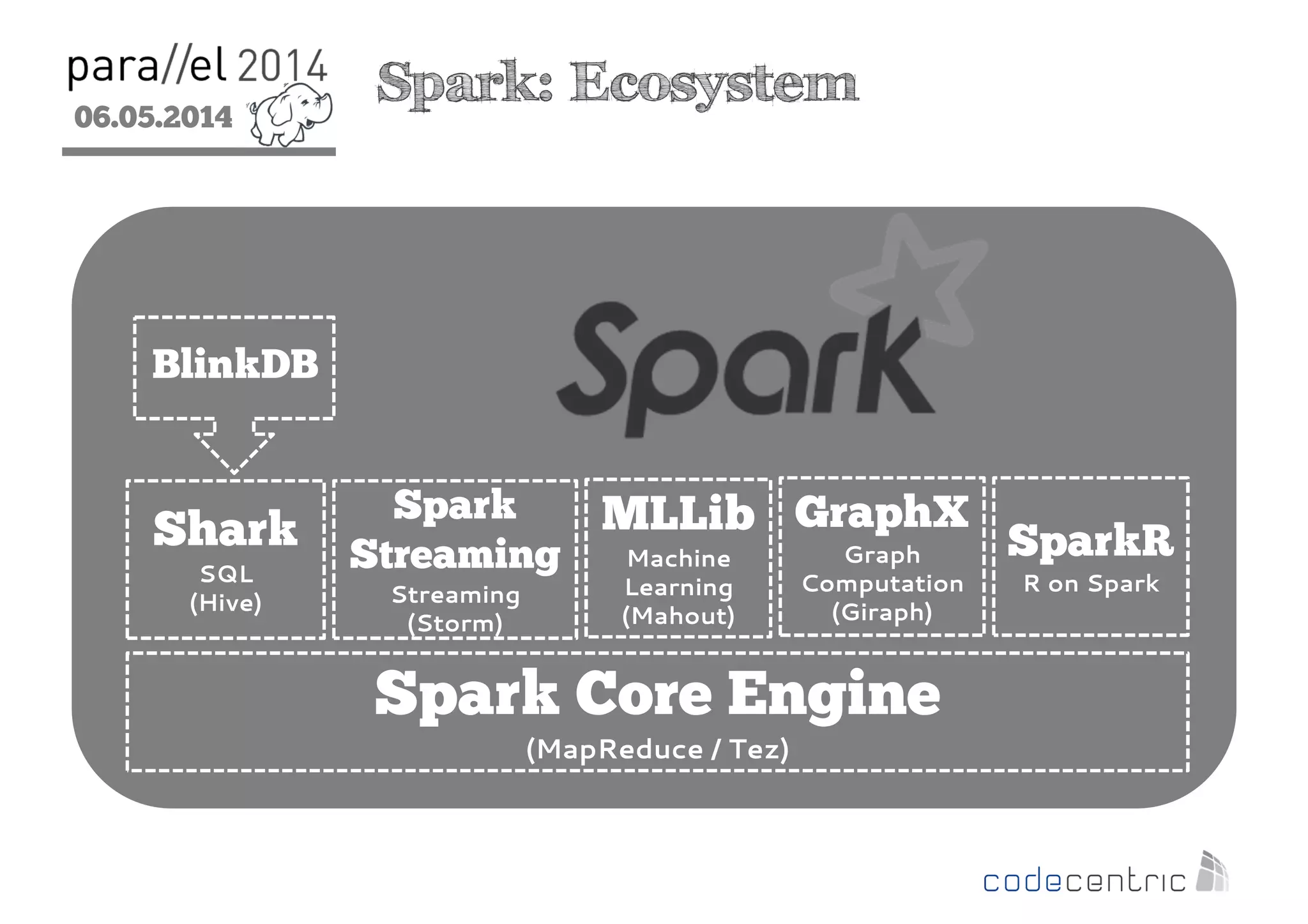
The document outlines the evolution and features of Hadoop 2, emphasizing its advancements over Hadoop 1, particularly with the introduction of YARN for resource management and support for various processing paradigms like MapReduce 2, Tez, and Spark. It details the limitations of the original Hadoop architecture, the architectural improvements with YARN, and the performance benefits of the new data processing engines, including dynamic task allocation and reduced latency. The document also discusses the capabilities of Apache Tez and Spark as applications within the Hadoop ecosystem, highlighting their contributions to efficient data handling and analytics.


















































































