



![RichRelevance DataMesh
Data Ingestion
3rd
Party
Realtime
Customer
Data Store
Analytics &
Optimization
Clickstream
Catalog
Online sales
In-store sales
Ad impressions
Social profiles
Redemptions…
125+ models
Customer models
Product models
A/B, MVT testing
King-of-the-hill
optimization
Offline
Data Feeds
Real-time
Decisioning
(65 msec)
[Client]
Innovation
Cloud
Event
Triggered
(minutes)
Batch
Updates
(hours)
Reporting
(ad
hoc, OLAP, E
xcel)
Underlying Technologies:
Hadoop, HBase, Hive, Kafka, Avro, Voldemort, Postgres, Pentaho OLAP, R
Custom apps and APIs
Self-Serve
Analytics
Personalized
Category Sort
Real-time
Segmentation
Network Ad
Tracking
© 2013 RichRelevance, Inc. All Rights Reserved. Confidential.
{rr} SaaS & APIs](https://image.slidesharecdn.com/stampededraft-v4-140123003458-phpapp01/85/Advanced-Analytics-using-Apache-Hive-4-320.jpg)







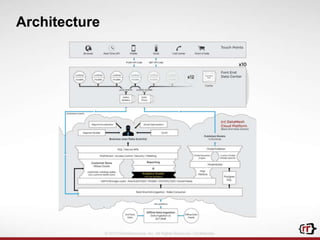


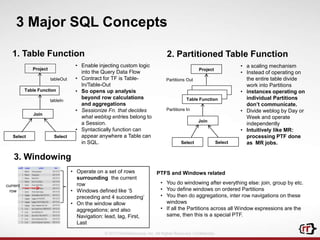
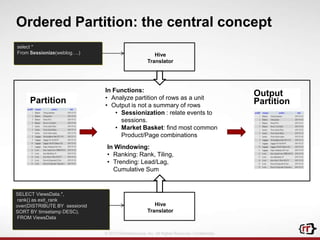


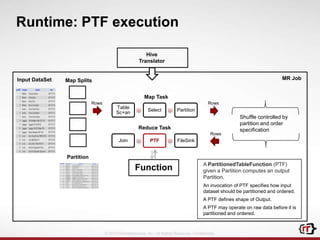



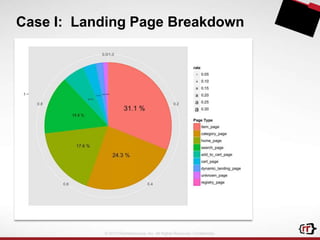
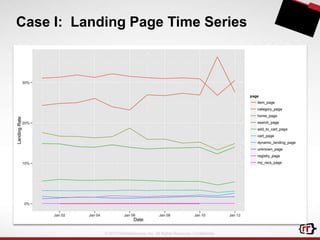
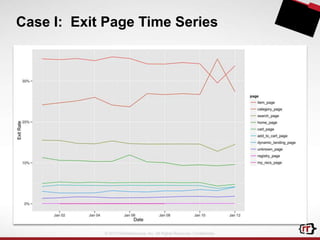


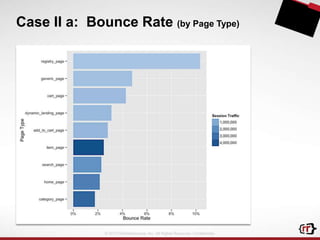
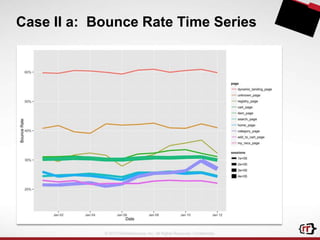






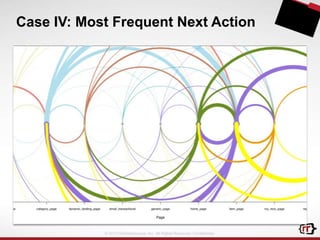





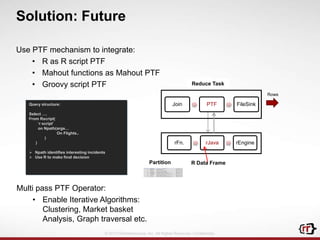


The document discusses clickstream analytics using Apache Hive, focusing on windowing and partitioned table functions (PTFs) for various analytical use cases. It highlights the architectures and technologies used in processing large datasets in real-time, including examples of specific analytics like bounce rates, path to purchase, and user behavior tracking. Additionally, it outlines the evolution and future of integrating these capabilities into Hive, enhancing its SQL functionalities to support more complex data analysis operations.






















































































