


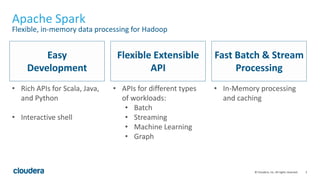


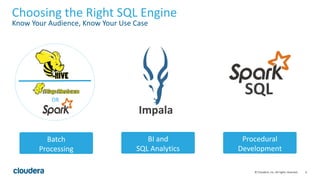






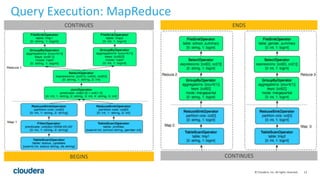
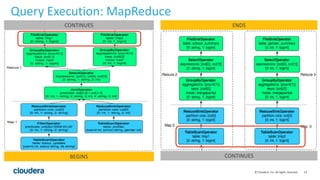
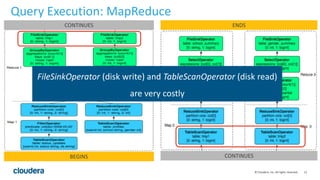
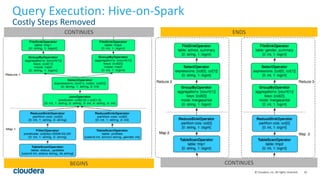
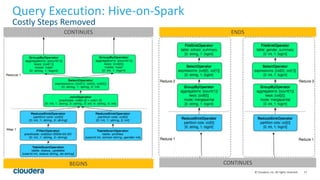

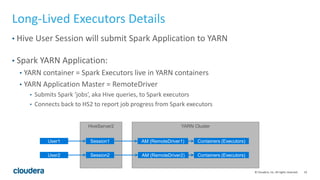














The document discusses Hive-on-Spark, an integration that enables Apache Hive to utilize Apache Spark as its execution engine, providing significant performance improvements—averaging 3x faster than the traditional Hive-on-MapReduce. It outlines key features, benefits, configuration requirements, and optimization techniques for using Hive-on-Spark effectively, such as executor management and resource allocation. Future enhancements and support developments are also highlighted, indicating ongoing collaboration and improvements in the ecosystem.























































































