Downloaded 69 times









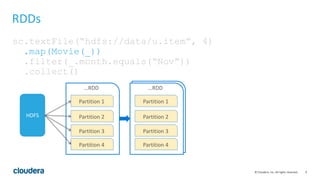
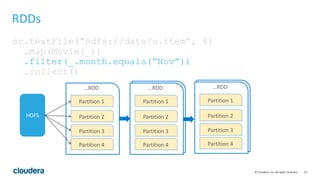
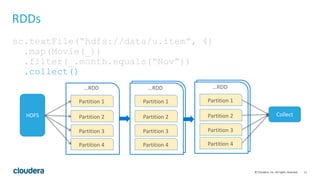
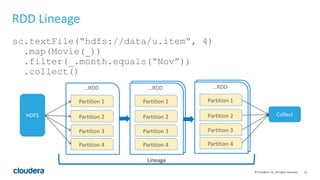
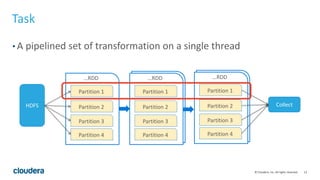
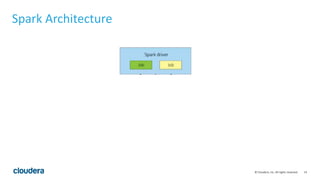
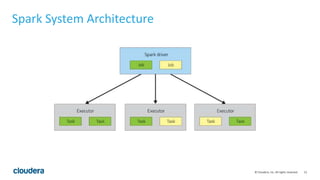

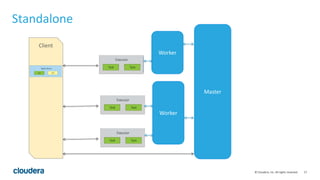

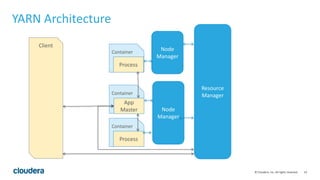
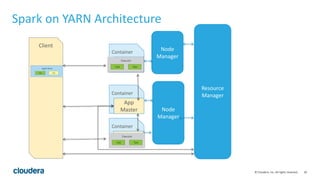
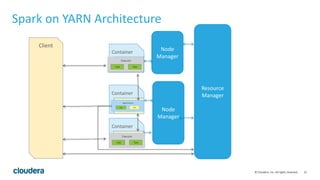













This document discusses Spark operations and architecture. It provides examples of Spark code and describes how Spark is deployed on different cluster managers like standalone, YARN, and Mesos. It discusses features like dynamic resource allocation, multi-tenancy, security, and authorization capabilities in Spark.










































































































