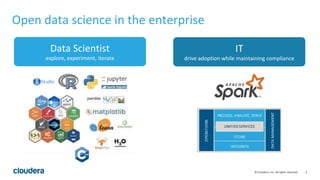
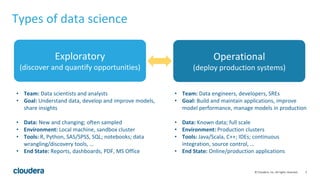
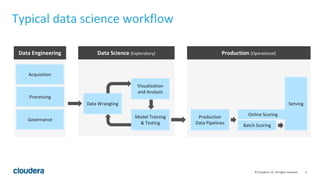
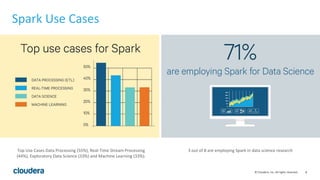
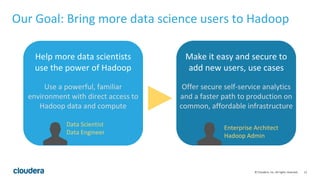
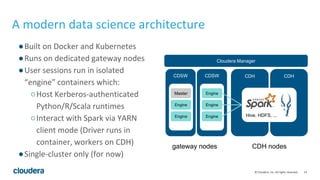
The document discusses Cloudera's approach to data engineering and data science, highlighting the challenges faced in deploying machine learning models and the need for effective collaboration among data scientists, engineers, and analysts. It emphasizes the importance of Apache Spark in facilitating data science workflows, including real-time stream processing and deep learning capabilities. The Cloudera Data Science Workbench is presented as a solution for self-service analytics, providing secure access, toolset integration, and support for multiple programming languages while ensuring data governance.