Downloaded 69 times


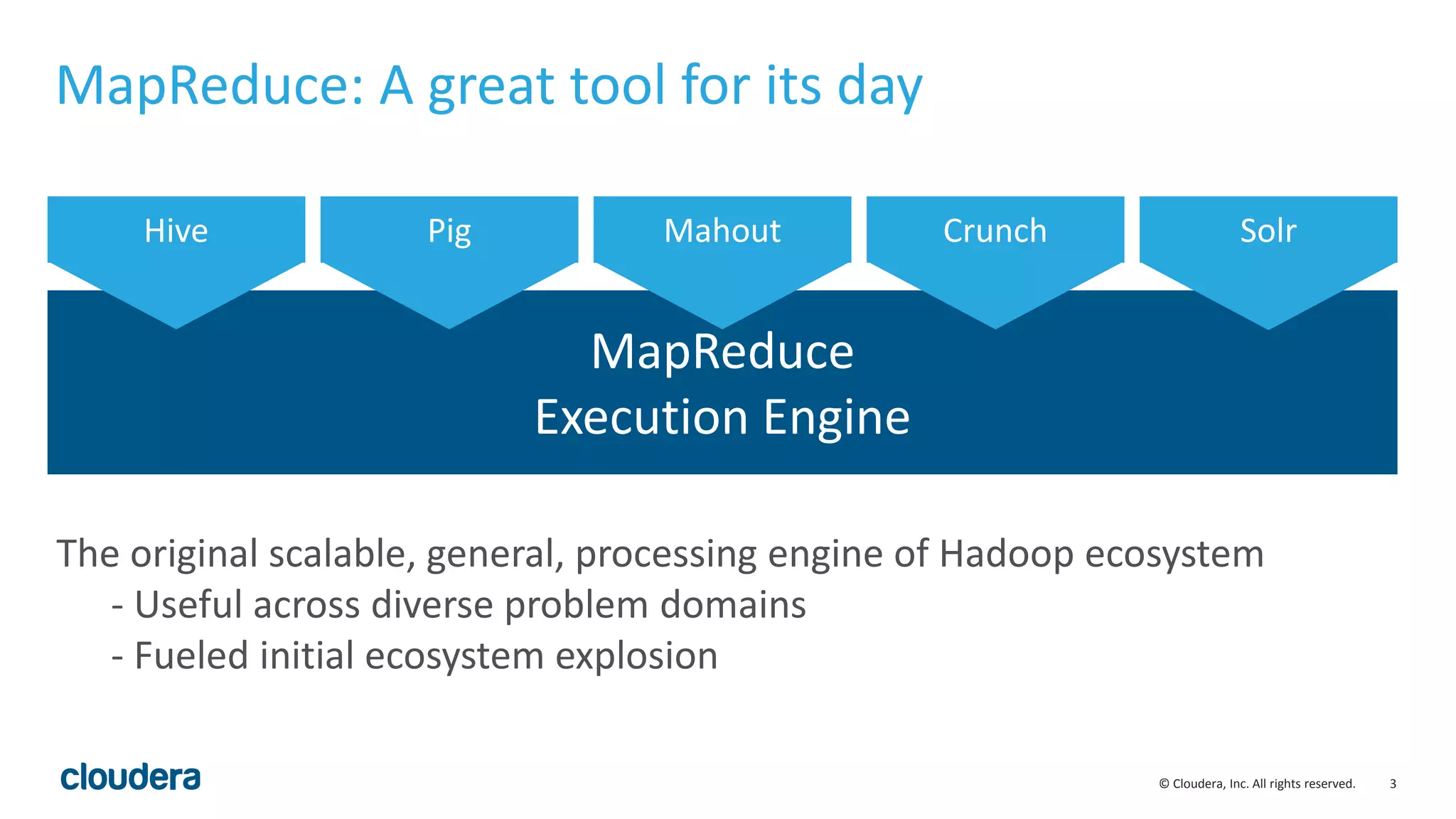


![7© Cloudera, Inc. All rights reserved.
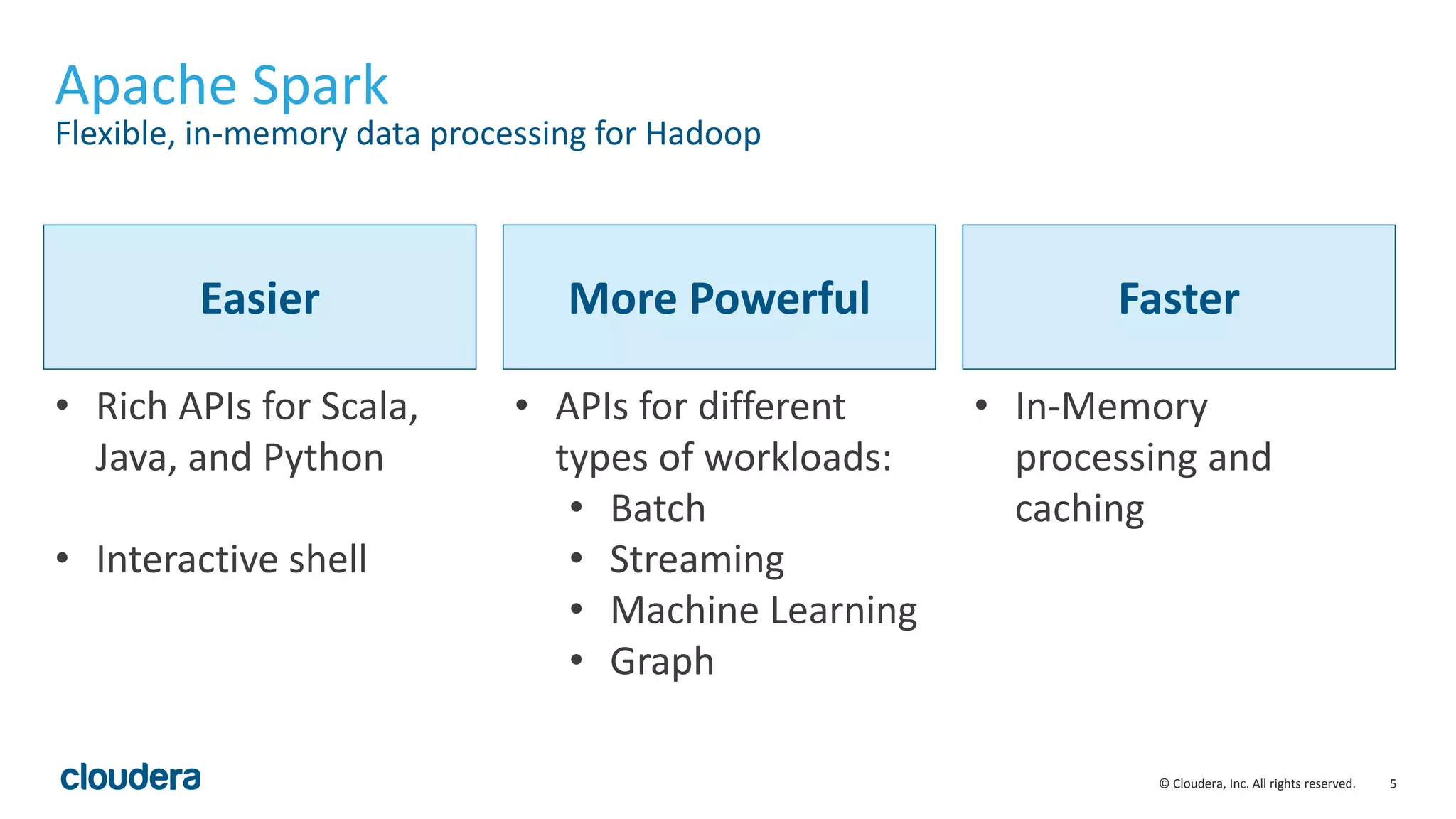
Easy Development
Use Interactively
• Interactive exploration of data
for data scientists
• No need to develop
“applications”
• Developers can prototype
application on live system
$ ./bin/spark-shell --master local[*]
...
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/_,_/_/ /_/_ version 1.5.0-SNAPSHOT
/_/
Using Scala version 2.10.4
(Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_51)
Type in expressions to have them evaluated.
Type :help for more information.
...
scala> val words = sc.textFile("file:/usr/share/dict/words")
...
words: org.apache.spark.rdd.RDD[String] =
MapPartitionsRDD[1] at textFile at <console>:21
scala> words.count
...
res0: Long = 235886
scala>](https://image.slidesharecdn.com/sparkoneplatformwebinar-151112192528-lva1-app6892/75/Spark-One-Platform-Webinar-7-2048.jpg)

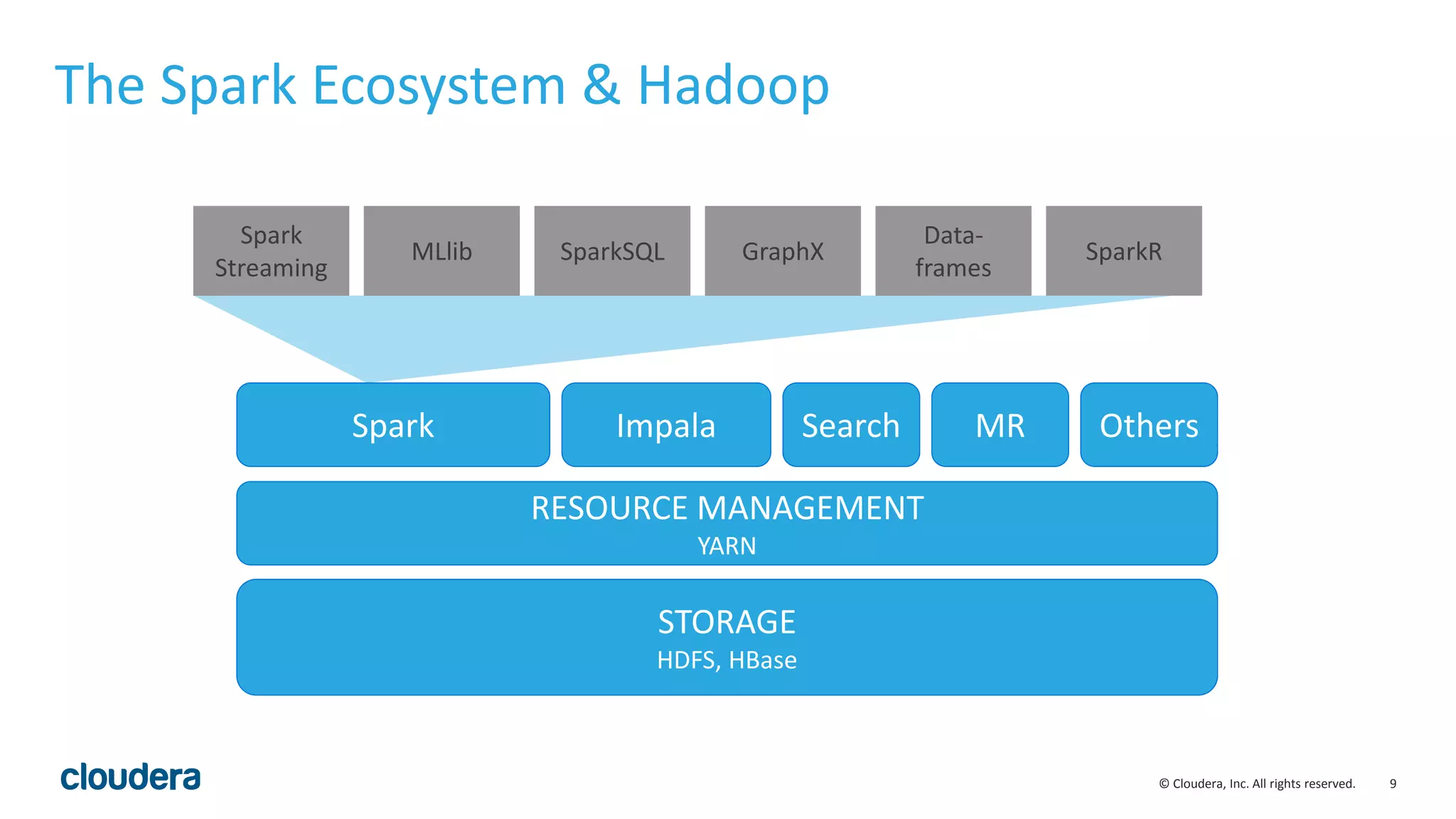
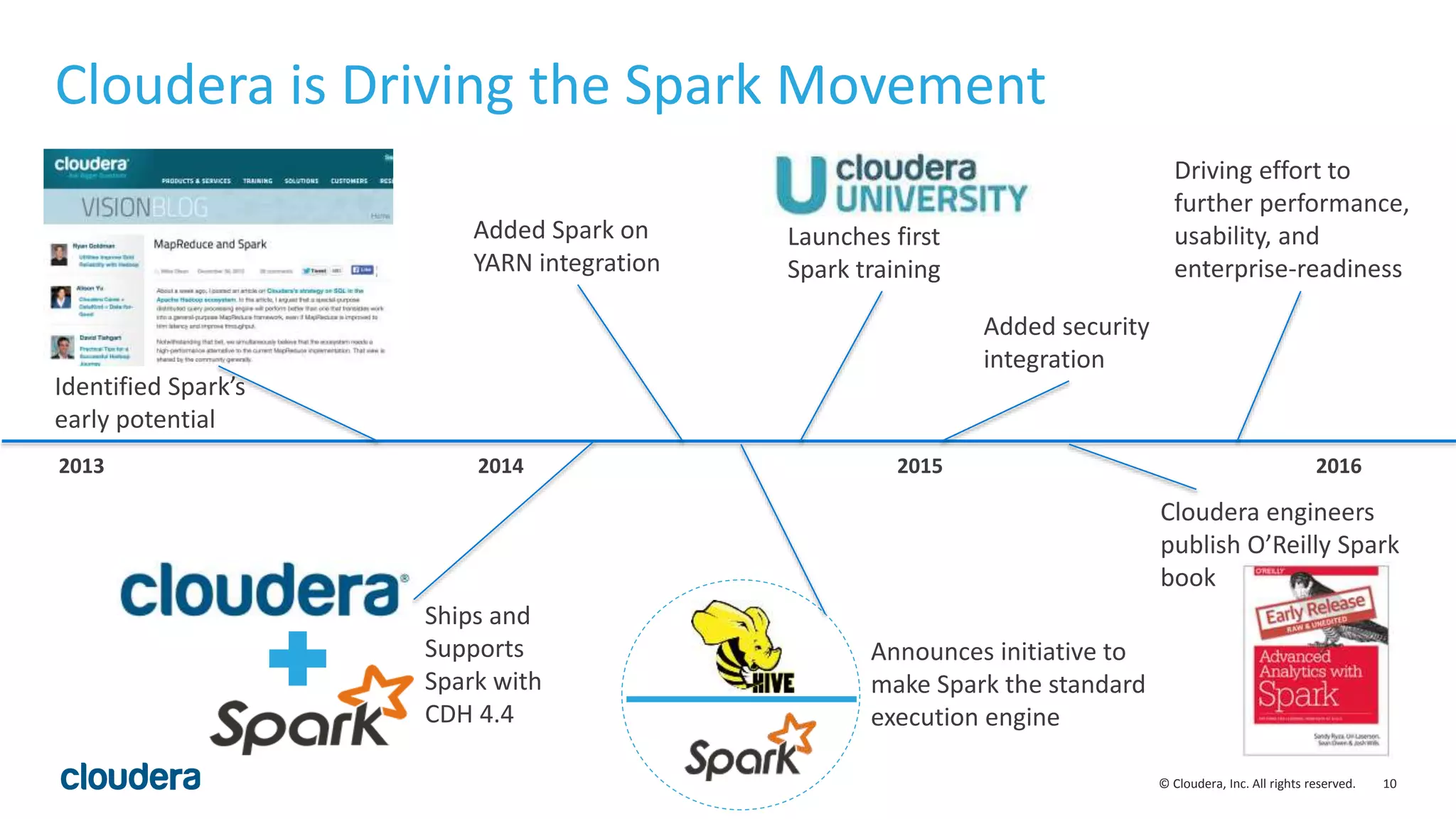

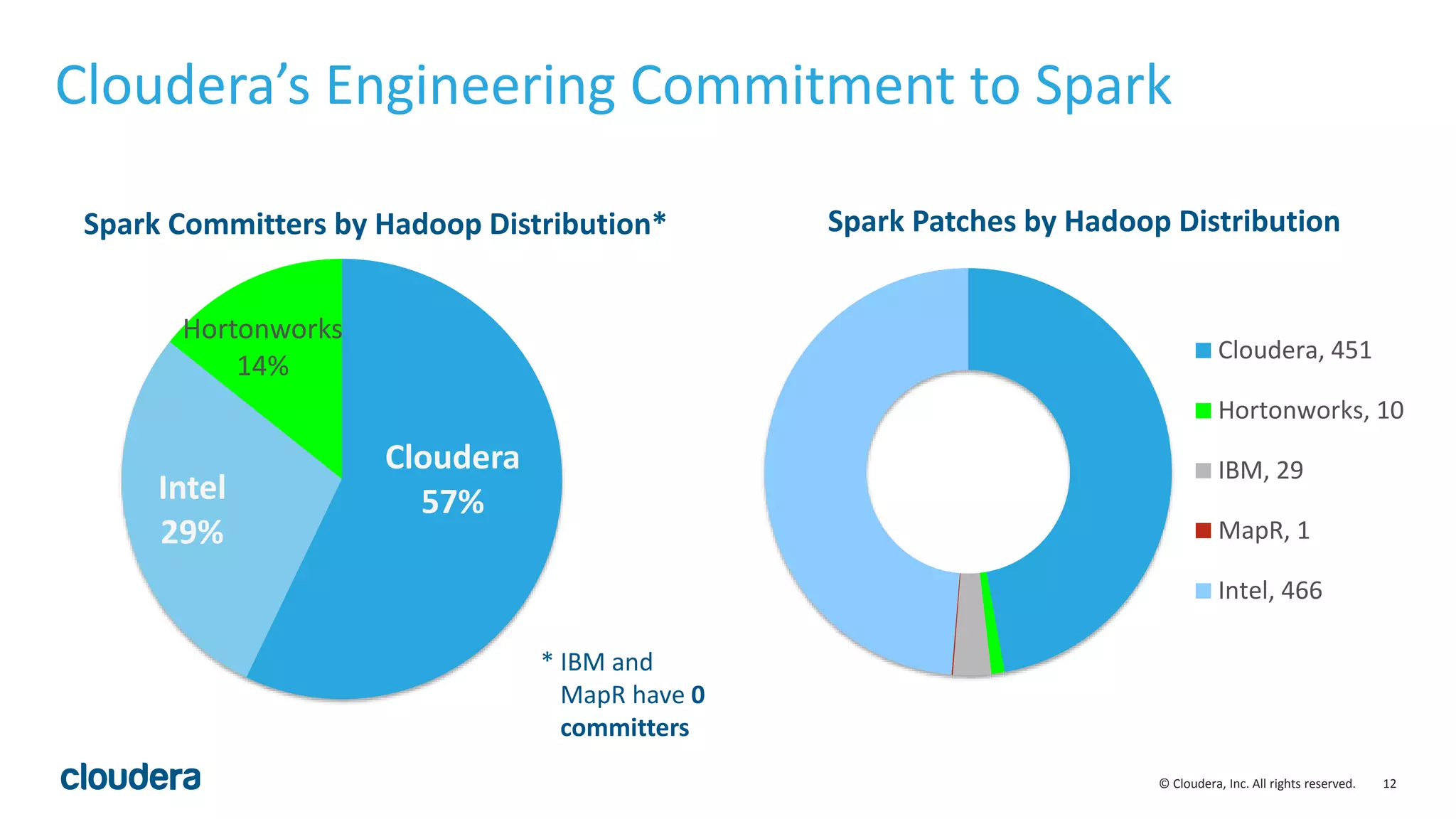




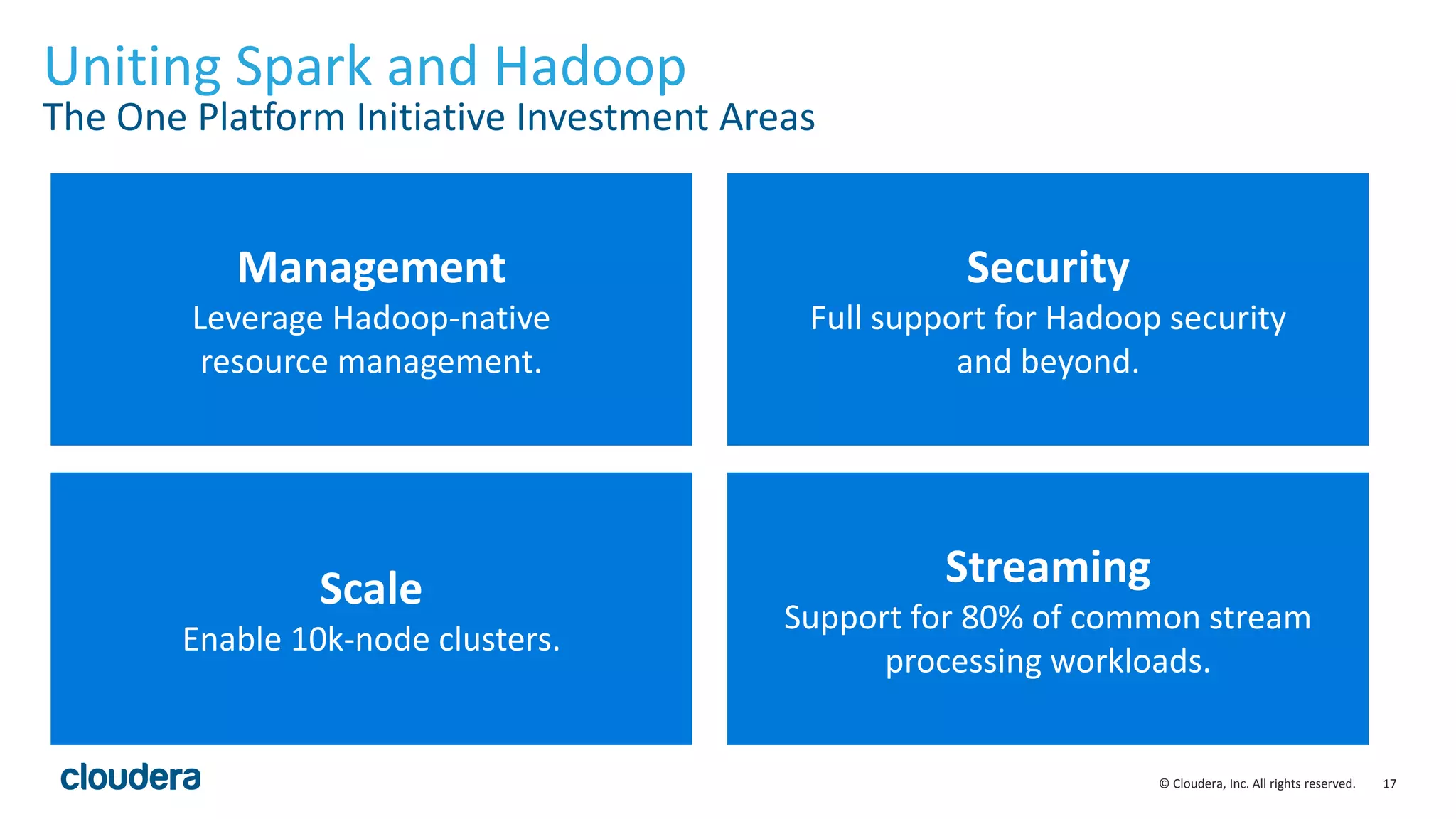




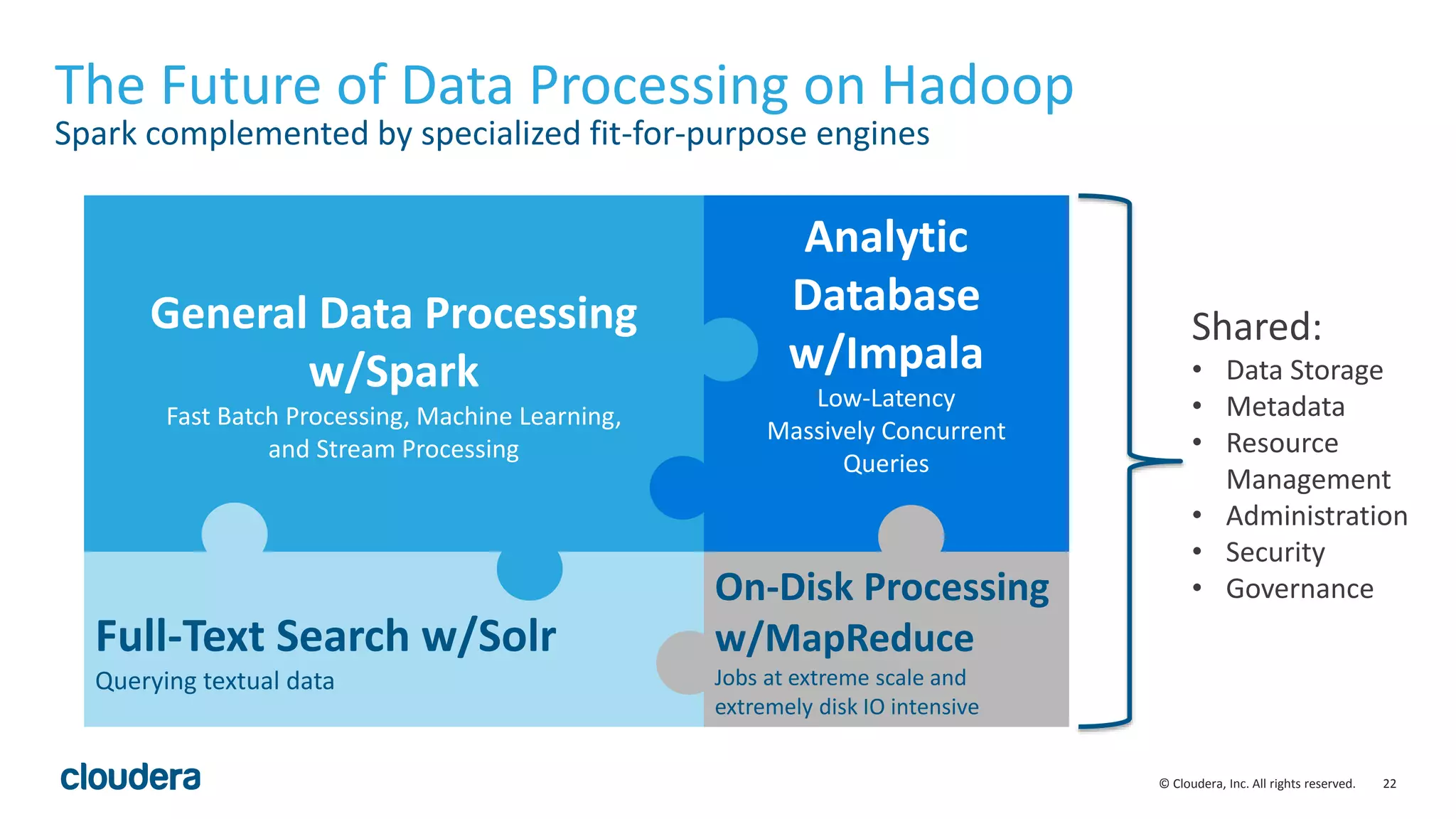
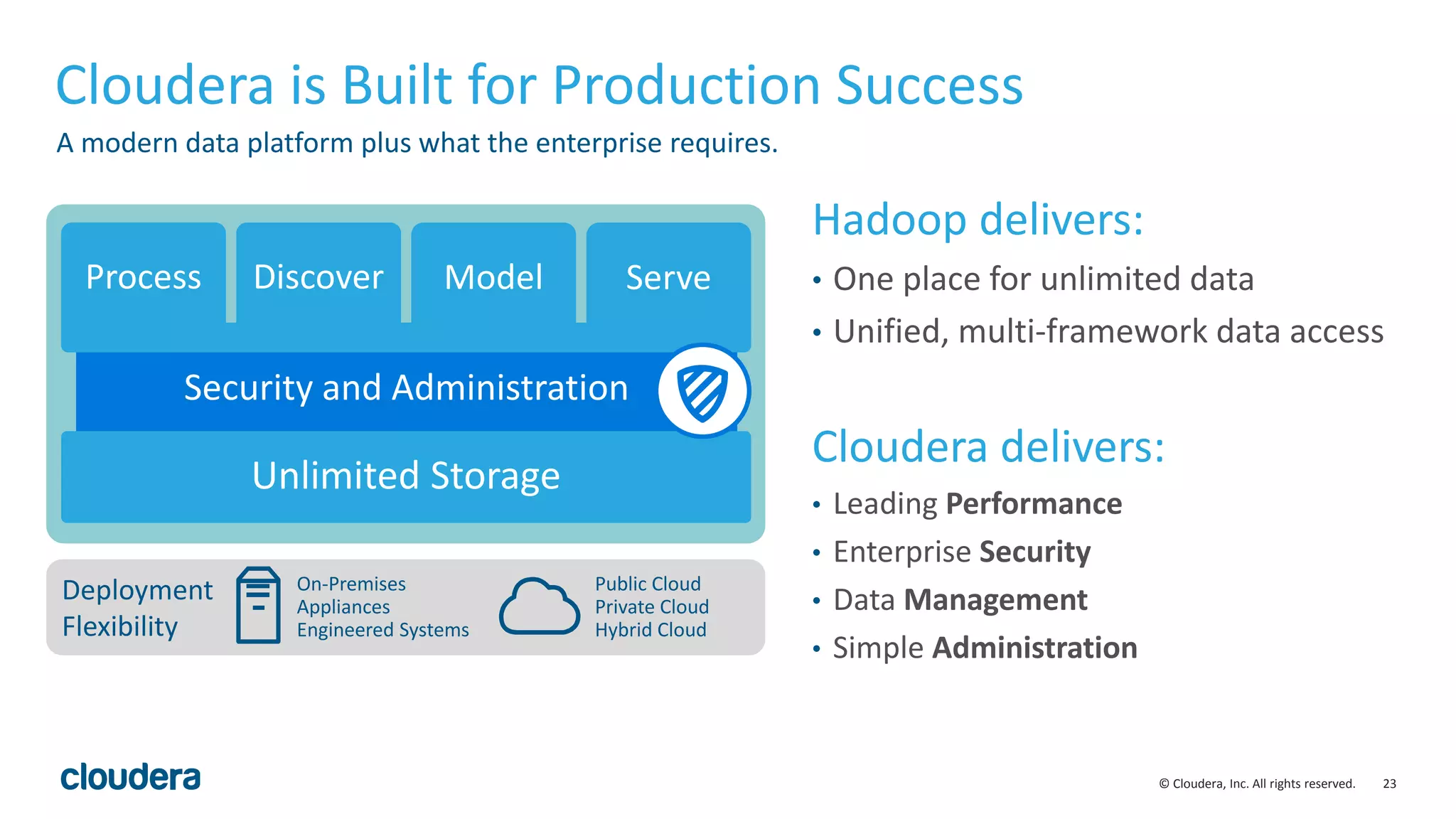





This document discusses Cloudera's initiative to make Spark the standard execution engine for Hadoop. It outlines how Spark improves on MapReduce by leveraging distributed memory and having a simpler developer experience. It also describes Cloudera's investments in areas like management, security, scale, and streaming to further Spark's capabilities and make it production-ready. The goal is for Spark to replace MapReduce as the execution engine and for specialized engines like Impala to handle specific workloads, with all sharing the same data, metadata, resource management, and other platform services.







































































![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)