This document discusses new features in Apache Hive 2.0, including:
1) Adding procedural SQL capabilities through HPLSQL for writing stored procedures.
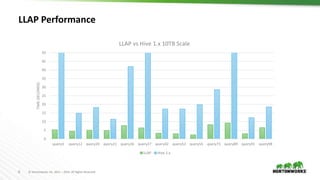
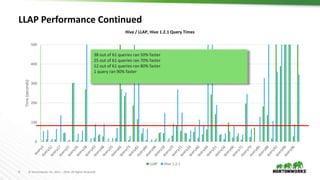
2) Improving query performance through LLAP which uses persistent daemons and in-memory caching to enable sub-second queries.
3) Speeding up query planning by using HBase as the metastore instead of a relational database.
4) Enhancements to Hive on Spark such as dynamic partition pruning and vectorized operations.
5) Default use of the cost-based optimizer and continued improvements to statistics collection and estimation.







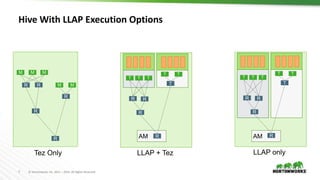





![15 © Hortonworks Inc. 2011 – 2016. All Rights Reserved
Hive 2.0 Incompabilities
Java 7 & 8 supported, 6 no longer supported
Requires Hadoop 2.x, Hadoop 1.x no longer supported
MapReduce deprecated, Tez or Spark recommended instead
– At some future date MR will be removed
Some configuration defaults changed, e.g.
– bucketing enforced by default
– metadata schema no longer created if it is missing
– SQL Standard authorization used by default
We plan to remove Hive CLI in the future and replace with beeline CLI
– Why?
• Makes it easier for users to deploy secure clusters where all access is via [OJ]DBC
• It is cleaner to maintain one code path
– Does not require HiveServer2, can run HS2 embedded in beeline](https://image.slidesharecdn.com/hive2-160414142406/85/Hive2-0-sql-speed-scale-hadoop-summit-dublin-apr-2016-15-320.jpg)














































































