Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
KS
Uploaded by
KCS Keio Computer Society
5,888 views
深層学習 第6章
深層学習 第6章
Science
◦
Read more
7
Save
Share
Embed
Embed presentation
Download
Downloaded 28 times
1
/ 38
2
/ 38
3
/ 38
4
/ 38
5
/ 38
6
/ 38
7
/ 38
8
/ 38
9
/ 38
10
/ 38
11
/ 38
12
/ 38
13
/ 38
14
/ 38
15
/ 38
16
/ 38
17
/ 38
18
/ 38
19
/ 38
20
/ 38
21
/ 38
22
/ 38
23
/ 38
24
/ 38
25
/ 38
26
/ 38
27
/ 38
28
/ 38
29
/ 38
30
/ 38
31
/ 38
32
/ 38
33
/ 38
34
/ 38
35
/ 38
36
/ 38
37
/ 38
38
/ 38
More Related Content
PDF
[DL輪読会]Inverse Constrained Reinforcement Learning
by
Deep Learning JP
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
PDF
【DL輪読会】Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
by
Deep Learning JP
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PPTX
強化学習2章
by
hiroki yamaoka
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
Direct feedback alignment provides learning in Deep Neural Networks
by
Deep Learning JP
[DL輪読会]Inverse Constrained Reinforcement Learning
by
Deep Learning JP
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
by
Yusuke Uchida
【DL輪読会】Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
by
Deep Learning JP
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
ベイズ統計学の概論的紹介
by
Naoki Hayashi
強化学習2章
by
hiroki yamaoka
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
Direct feedback alignment provides learning in Deep Neural Networks
by
Deep Learning JP
What's hot
PDF
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
PDF
データに内在する構造をみるための埋め込み手法
by
Tatsuya Shirakawa
PDF
[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−
by
Deep Learning JP
PDF
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
PPTX
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
PPTX
[DL輪読会]Neural Ordinary Differential Equations
by
Deep Learning JP
PDF
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
PPTX
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
PDF
POMDP下での強化学習の基礎と応用
by
Yasunori Ozaki
PDF
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...
by
Deep Learning JP
PDF
【DL輪読会】Segment Anything
by
Deep Learning JP
PDF
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
PPTX
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
PDF
論文紹介:Dueling network architectures for deep reinforcement learning
by
Kazuki Adachi
PPTX
Group normalization
by
Ryutaro Yamauchi
PPTX
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
PDF
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
by
SSII
時系列予測にTransformerを使うのは有効か?
by
Fumihiko Takahashi
データに内在する構造をみるための埋め込み手法
by
Tatsuya Shirakawa
[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−
by
Deep Learning JP
方策勾配型強化学習の基礎と応用
by
Ryo Iwaki
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
[DL輪読会]Pay Attention to MLPs (gMLP)
by
Deep Learning JP
[DL輪読会]Neural Ordinary Differential Equations
by
Deep Learning JP
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
POMDP下での強化学習の基礎と応用
by
Yasunori Ozaki
[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...
by
Deep Learning JP
【DL輪読会】Segment Anything
by
Deep Learning JP
ドメイン適応の原理と応用
by
Yoshitaka Ushiku
【論文紹介】How Powerful are Graph Neural Networks?
by
Masanao Ochi
論文紹介:Dueling network architectures for deep reinforcement learning
by
Kazuki Adachi
Group normalization
by
Ryutaro Yamauchi
【DL輪読会】High-Resolution Image Synthesis with Latent Diffusion Models
by
Deep Learning JP
SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜
by
SSII
Similar to 深層学習 第6章
PPTX
深層学習の数理
by
Taiji Suzuki
PPTX
Deep Learning Chap. 6: Deep Feedforward Networks
by
Shion Honda
PDF
DeepLearningBook勉強会 6.2章
by
Masafumi Tsuyuki
PDF
第2回 メドレー読書会
by
Toshifumi
PPTX
PRML第6章「カーネル法」
by
Keisuke Sugawara
PDF
20170422 数学カフェ Part1
by
Kenta Oono
PPTX
Deep learning basics described
by
Naoki Watanabe
PDF
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
PDF
深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計
by
Yuta Sugii
PDF
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
PDF
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
PPTX
パターン認識モデル初歩の初歩
by
t_ichioka_sg
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PDF
[DL輪読会]Deep Learning 第5章 機械学習の基礎
by
Deep Learning JP
PDF
Prml sec6
by
Keisuke OTAKI
PPTX
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
by
Daiyu Hatakeyama
PDF
Deep learning入門
by
magoroku Yamamoto
PPTX
Positive-Unlabeled Learning with Non-Negative Risk Estimator
by
Kiryo Ryuichi
PDF
深層学習入門
by
Danushka Bollegala
深層学習の数理
by
Taiji Suzuki
Deep Learning Chap. 6: Deep Feedforward Networks
by
Shion Honda
DeepLearningBook勉強会 6.2章
by
Masafumi Tsuyuki
第2回 メドレー読書会
by
Toshifumi
PRML第6章「カーネル法」
by
Keisuke Sugawara
20170422 数学カフェ Part1
by
Kenta Oono
Deep learning basics described
by
Naoki Watanabe
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
深層学習 勉強会第1回 ディープラーニングの歴史とFFNNの設計
by
Yuta Sugii
深層学習(講談社)のまとめ(1章~2章)
by
okku apot
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
パターン認識モデル初歩の初歩
by
t_ichioka_sg
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
[DL輪読会]Deep Learning 第5章 機械学習の基礎
by
Deep Learning JP
Prml sec6
by
Keisuke OTAKI
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
by
Daiyu Hatakeyama
Deep learning入門
by
magoroku Yamamoto
Positive-Unlabeled Learning with Non-Negative Risk Estimator
by
Kiryo Ryuichi
深層学習入門
by
Danushka Bollegala
More from KCS Keio Computer Society
PPTX
Large scale gan training for high fidelity natural
by
KCS Keio Computer Society
PPTX
Imagenet trained cnns-are_biased_towards
by
KCS Keio Computer Society
PPTX
機械学習ゼミ: Area attenttion
by
KCS Keio Computer Society
PPTX
機械学習ゼミ 2018/10/17
by
KCS Keio Computer Society
PDF
機械学習ゼミ2018 06 15
by
KCS Keio Computer Society
PPTX
Control by deep learning
by
KCS Keio Computer Society
PDF
Vector-Based navigation using grid-like representations in artificial agents
by
KCS Keio Computer Society
PDF
文章生成の未解決問題
by
KCS Keio Computer Society
PDF
Word2vec alpha
by
KCS Keio Computer Society
PDF
テンソル代数
by
KCS Keio Computer Society
PDF
Hindsight experience replay
by
KCS Keio Computer Society
PDF
Kml 輪読514
by
KCS Keio Computer Society
PDF
ゼロから作るDeepLearning 5章 輪読
by
KCS Keio Computer Society
PDF
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
PDF
ゼロから作るDeepLearning 2~3章 輪読
by
KCS Keio Computer Society
PDF
ゼロから作るDeepLearning 4章 輪読
by
KCS Keio Computer Society
PDF
Soft Actor Critic 解説
by
KCS Keio Computer Society
PDF
ゼロから作るDeepLearning 3.3~3.6章 輪読
by
KCS Keio Computer Society
PDF
[論文略説]Stochastic Thermodynamics Interpretation of Information Geometry
by
KCS Keio Computer Society
PPTX
Graph Convolutional Network 概説
by
KCS Keio Computer Society
Large scale gan training for high fidelity natural
by
KCS Keio Computer Society
Imagenet trained cnns-are_biased_towards
by
KCS Keio Computer Society
機械学習ゼミ: Area attenttion
by
KCS Keio Computer Society
機械学習ゼミ 2018/10/17
by
KCS Keio Computer Society
機械学習ゼミ2018 06 15
by
KCS Keio Computer Society
Control by deep learning
by
KCS Keio Computer Society
Vector-Based navigation using grid-like representations in artificial agents
by
KCS Keio Computer Society
文章生成の未解決問題
by
KCS Keio Computer Society
Word2vec alpha
by
KCS Keio Computer Society
テンソル代数
by
KCS Keio Computer Society
Hindsight experience replay
by
KCS Keio Computer Society
Kml 輪読514
by
KCS Keio Computer Society
ゼロから作るDeepLearning 5章 輪読
by
KCS Keio Computer Society
ELBO型VAEのダメなところ
by
KCS Keio Computer Society
ゼロから作るDeepLearning 2~3章 輪読
by
KCS Keio Computer Society
ゼロから作るDeepLearning 4章 輪読
by
KCS Keio Computer Society
Soft Actor Critic 解説
by
KCS Keio Computer Society
ゼロから作るDeepLearning 3.3~3.6章 輪読
by
KCS Keio Computer Society
[論文略説]Stochastic Thermodynamics Interpretation of Information Geometry
by
KCS Keio Computer Society
Graph Convolutional Network 概説
by
KCS Keio Computer Society
深層学習 第6章
1.
KML輪読 「深層学習」 第6章 今井研究室4年 阿部佑樹 2018/6/9
2.
前回までのあらすじ 1. 前々回:「深層学習」6章 ○ 内容は「ゼロから作る」の総集編 2.
前回:(深層学習)テンソル代数 ○ 「深層学習」を読むための行列のお勉強 今回から「深層学習」読んでいきます! 必要になると思う知識 ● ニューラルネットワークの雰囲気 ● 確率分布と期待値 ○ 補足しながらやります ○ 今までのアプローチと違うところ 2
3.
今日のトピック ● XORの復習 ● 機械学習の基礎(補足) ●
コスト関数 ○ 負の対数尤度 ● 出力ユニット ○ ガウス分布、ベルヌーイ分布、マルチヌーイ分布 ● 隠れユニット ○ ReLU、ReLUの一般化、マックスアウトユニット、シグモイ ド、ハイパボリックタンジェント ● 機械学習で有名な定理 ○ 普遍性定理 ○ ノーフリーランチ定理 3
4.
今日のトピック ● XORの復習 ● 機械学習の基礎(補足) ●
コスト関数 ○ 負の対数尤度 ● 出力ユニット ○ ガウス分布、ベルヌーイ分布、マルチヌーイ分布 ● 隠れユニット ○ ReLU、ReLUの一般化、マックスアウトユニット、シグモイ ド、ハイパボリックタンジェント ● 機械学習で有名な定理 ○ 普遍性定理 ○ ノーフリーランチ定理 4
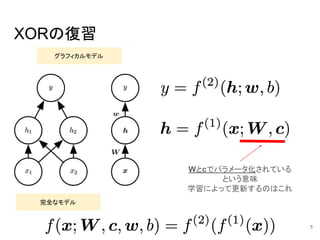
5.
XORの復習 グラフィカルモデル 完全なモデル Wとcでパラメータ化されている という意味 学習によって更新するのはこれ 5
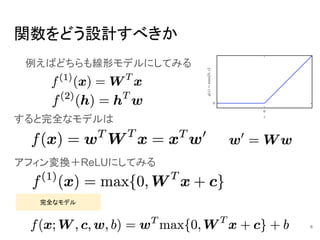
6.
関数をどう設計すべきか 例えばどちらも線形モデルにしてみる すると完全なモデルは アフィン変換+ReLUにしてみる 完全なモデル 6
7.
XORの復習まとめ XORを近似する関数を学習するために、 ● 隠れ層(hidden layer)の導入 ●
活性化関数(activation function)の導入 ○ 非線形関数(ReLU) モデル構築に関して他に習ってきたこと ● 活性化関数:シグモイド ● 損失関数:平均二乗誤差、交差エントロピー ● 勾配更新:誤差逆伝播法(だいたい一緒なので割愛) 「深層学習」第6章を通して1つずつ詳しく見ていこう 7
8.
今日のトピック ● XORの復習 ● 機械学習の基礎(補足) ●
コスト関数 ○ 負の対数尤度 ● 出力ユニット ○ ガウス分布、ベルヌーイ分布、マルチヌーイ分布 ● 隠れユニット ○ ReLU、ReLUの一般化、マックスアウトユニット、シグモイ ド、ハイパボリックタンジェント ● 機械学習で有名な定理 ○ 普遍性定理 ○ ノーフリーランチ定理 8
9.
機械学習の基礎(補足) データを科学的に分析する際の数理的手法:統計学 データの分析から、データ自身ではなくその背後にある母集団の 知識を獲得することを目標にしている。 母集団の性質はデータ生成分布Pdata(x)により特徴付けられて いるものとする。 9 ⇒ 不確実性を伴う現象を確率的にモデル化する! システムに寄与する全ての因子を観測することはできないので、 データは何か確率的なプロセスに従って生じているものとみなす。
10.
機械学習の基礎(補足) データを特徴付けるのに十分な統計量をパラメータと呼ぶ。 真のデータ生成分布Pdata(x)は無数のパラメータを持っている (はず)なので完全に知ることは望み薄。 なので通常は、 真のデータ生成分布Pdata(x)をよく近似できると期待されるモデ ル分布Pmodel(x;θ)を仮定し最適値θ*をデータから推定。 10 点推定 データ集合 に対して推定値 が真のパラメータを良く近似
11.
機械学習の基礎(補足) パラメトリックな場合には広く使える強力な手法 データ生成分布のパラメトリックモデルPmodel(x;θ)と与えられた データ集合を用いて、 11 最尤推定法 (maximal likelihood
method) 変数θに関する量とみなしてL(θ)と書き尤度関数と呼ぶ。 ある観測値が得られたのは、パラメータθの値がある観測値が得 られる確率を大きくするものだったから、と考える。
12.
機械学習の基礎(補足) すると与えられたデータに対して尤もらしいパラメータの値は尤度 を最大化したものだということになる。 12 実用上は計算機がアンダーフローを起こさないよう対数を取る。 機械学習では最小化の問題を解くことが多いので負の対数尤度 を取る。よって推定するパラメータは、 このように何らかの目的関数を最大化、あるいは最小化すること で最適なパラメータ値を決定するのが機械学習における常套手 段である。
13.
今日のトピック ● XORの復習 ● 機械学習の基礎(補足) ●
コスト関数 ○ 負の対数尤度 ● 出力ユニット ○ ガウス分布、ベルヌーイ分布、マルチヌーイ分布 ● 隠れユニット ○ ReLU、ReLUの一般化、マックスアウトユニット、シグモイ ド、ハイパボリックタンジェント ● 機械学習で有名な定理 ○ 普遍性定理 ○ ノーフリーランチ定理 13
14.
コスト関数(損失関数) 大抵パラメトリックモデルでは最尤法の原則を使用する。 無視された定数項はガウス分布の分散に基づく。 出力分布の最尤推定と平均二乗誤差の最小化が等価。 コスト関数の具体的な形は対数尤度の形によって異なる。 例えば回帰、 14
15.
コスト関数(損失関数) 他には分類、 15 これをデータによって学習させるには最尤法に従って、 機械学習の実装で用いられるのは負の対数尤度だった。 これで誤差関数を定義したものは、データの経験分布とモデル分 布の間の交差エントロピー(cross entropy)と呼ばれる。
16.
コスト関数(損失関数)(補足) 同じ確率変数Xに対して異なる確率分布P(X)とQ(X)があるとき、 カルバックライブラーダイバージェンスを使ってこの2つの分布に どれだけ差があるのかを測ることができる。 16 PとQが同じ分布の場合にKLダイバージェンスは0になる。また KLダイバージェンスは非負である。 交差エントロピーはKLダイバージェンスと密接に関係 = Qに関して交差エントロピーを最小化 = Qに関してKLダイバージェンスを最小化 Qに関して負の対数尤度を最小化
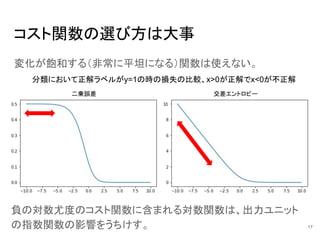
17.
コスト関数の選び方は大事 変化が飽和する(非常に平坦になる)関数は使えない。 17 分類において正解ラベルがy=1の時の損失の比較、x>0が正解でx<0が不正解 二乗誤差 交差エントロピー 負の対数尤度のコスト関数に含まれる対数関数は、出力ユニット の指数関数の影響をうちけす。
18.
今日のトピック ● XORの復習 ● 機械学習の基礎(補足) ●
コスト関数 ○ 負の対数尤度 ● 出力ユニット ○ ガウス分布、ベルヌーイ分布、マルチヌーイ分布 ● 隠れユニット ○ ReLU、ReLUの一般化、マックスアウトユニット、シグモイ ド、ハイパボリックタンジェント ● 機械学習で有名な定理 ○ 普遍性定理 ○ ノーフリーランチ定理 18
19.
出力ユニット コスト関数の選択は出力ユニットの選択と強く結びついている。ほ とんどの場合、単純にデータ分布とモデル分布の間の交差エント ロピーが利用される。 さっきの例は、出力ユニットがガウス分布に従うなら、 出力の表現方法の選択によって交差エントロピーの関数の形が 決まる。 19
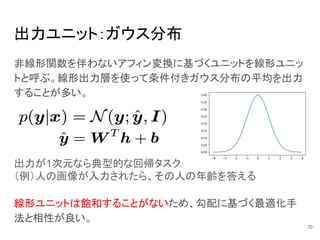
20.
出力ユニット:ガウス分布 非線形関数を伴わないアフィン変換に基づくユニットを線形ユニッ トと呼ぶ。線形出力層を使って条件付きガウス分布の平均を出力 することが多い。 出力が1次元なら典型的な回帰タスク (例)人の画像が入力されたら、その人の年齢を答える 線形ユニットは飽和することがないため、勾配に基づく最適化手 法と相性が良い。 20
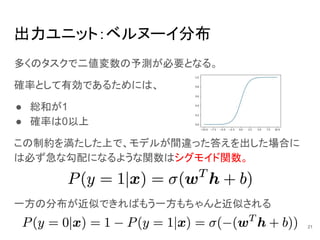
21.
出力ユニット:ベルヌーイ分布 多くのタスクで二値変数の予測が必要となる。 確率として有効であるためには、 ● 総和が1 ● 確率は0以上 この制約を満たした上で、モデルが間違った答えを出した場合に は必ず急な勾配になるような関数はシグモイド関数。 一方の分布が近似できればもう一方もちゃんと近似される 21
22.
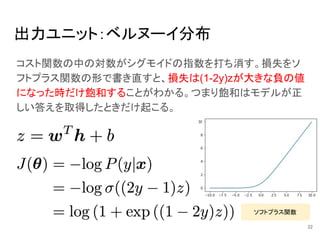
出力ユニット:ベルヌーイ分布 コスト関数の中の対数がシグモイドの指数を打ち消す。損失をソ フトプラス関数の形で書き直すと、損失は(1-2y)zが大きな負の値 になった時だけ飽和することがわかる。つまり飽和はモデルが正 しい答えを取得したときだけ起こる。 ソフトプラス関数 22
23.
出力ユニット:マルチヌーイ分布 N個の取りうる離散値に関する確率分布を表現したい場合はソフ トマックス関数が利用できる。 二値変数に関する確率分布を表現するために利用されたシグモ イド関数の一般化と考えられる。 23
24.
出力ユニット:マルチヌーイ分布 対数尤度を最大化するときは、全ての zjを小さくする方向に寄与する。 尤度(出力yの値がiとなるような確率)は、 入力が常にコスト関数に直接影響こ の項は飽和しない 対数尤度を最大化するときは、ziを大 きくする方向に寄与する。 直感的に、負の対数尤度のコスト関数は、最も活性化されている 間違った予測に対して必ず大きなペナルティを課す。 24
25.
今日のトピック ● XORの復習 ● 機械学習の基礎(補足) ●
コスト関数 ○ 負の対数尤度 ● 出力ユニット ○ ガウス分布、ベルヌーイ分布、マルチヌーイ分布 ● 隠れユニット ○ ReLU、ReLUの一般化、マックスアウトユニット、シグモイ ド、ハイパボリックタンジェント ● 機械学習で有名な定理 ○ 普遍性定理 ○ ノーフリーランチ定理 25
26.
隠れユニット ここまでは勾配降下法によって学習するパラメトリックな機械学習 アルゴリズムのほとんどに共通するものに焦点を当ててきた。 順伝播型ネットワーク固有の問題 モデルの隠れ層の中で使用する隠れユニットの種類をどう選択す るか(理論的な原則に基づく確実な指針は多くない) 各種の隠れユニットに関して、それを使うことについての基本的な 洞察をいくつか説明する。 26
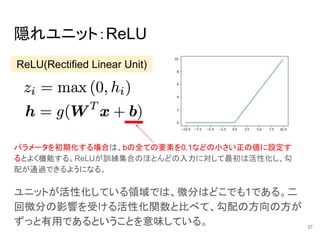
27.
隠れユニット:ReLU ユニットが活性化している領域では、微分はどこでも1である。二 回微分の影響を受ける活性化関数と比べて、勾配の方向の方が ずっと有用であるということを意味している。 ReLU(Rectified Linear Unit) パラメータを初期化する場合は、bの全ての要素を0.1などの小さい正の値に設定す るとよく機能する。ReLUが訓練集合のほとんどの入力に対して最初は活性化し、勾 配が通過できるようになる。 27
28.
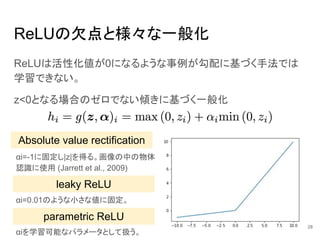
ReLUの欠点と様々な一般化 ReLUは活性化値が0になるような事例が勾配に基づく手法では 学習できない。 z<0となる場合のゼロでない傾きに基づく一般化 Absolute value rectification αi=-1に固定し|z|を得る。画像の中の物体 認識に使用
(Jarrett et al., 2009) leaky ReLU αi=0.01のような小さな値に固定。 parametric ReLU αiを学習可能なパラメータとして扱う。 28
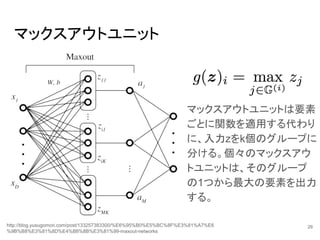
29.
マックスアウトユニット マックスアウトユニットは要素 ごとに関数を適用する代わり に、入力zをk個のグループに 分ける。個々のマックスアウ トユニットは、そのグループ の1つから最大の要素を出力 する。 http://blog.yusugomori.com/post/133257383300/%E6%95%B0%E5%BC%8F%E3%81%A7%E6 %9B%B8%E3%81%8D%E4%B8%8B%E3%81%99-maxout-networks 29
30.
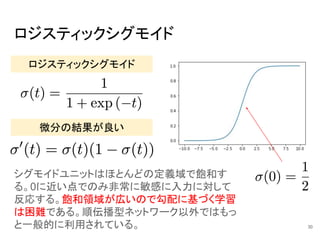
ロジスティックシグモイド ロジスティックシグモイド 微分の結果が良い シグモイドユニットはほとんどの定義域で飽和す る。0に近い点でのみ非常に敏感に入力に対して 反応する。飽和領域が広いので勾配に基づく学習 は困難である。順伝播型ネットワーク以外ではもっ と一般的に利用されている。 30
31.
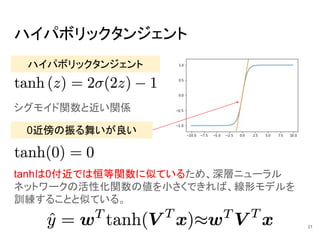
ハイパボリックタンジェント ハイパボリックタンジェント シグモイド関数と近い関係 0近傍の振る舞いが良い tanhは0付近では恒等関数に似ているため、深層ニューラル ネットワークの活性化関数の値を小さくできれば、線形モデルを 訓練することと似ている。 31
32.
今日のトピック ● XORの復習 ● 機械学習の基礎(補足) ●
コスト関数 ○ 負の対数尤度 ● 出力ユニット ○ ガウス分布、ベルヌーイ分布、マルチヌーイ分布 ● 隠れユニット ○ ReLU、ReLUの一般化、マックスアウトユニット、シグモイ ド、ハイパボリックタンジェント ● 機械学習で有名な定理 ○ 普遍性定理 ○ ノーフリーランチ定理 32
33.
普遍性定理 ネットワークが十分な数の隠れユニットを持つ場合、線形の出力 層と(ロジスティックシグモイド活性化関数のような)「押しつぶす」 ことができる活性化関数(ReLUもOK)を持つ隠れ層が少なくとも 1つ含まれる順伝播型ネットワークは、どんなボレル可測関数でも 任意の精度で近似できる。 ひらたく言えば、、、 順伝播ニューラルネットワークは任意の関数を任意の精度で近似 できる!(数学科の人ごめんなさい) 1つの隠れ層でもこの定理は成り立つ(深層でなくてよい) 33
34.
普遍性定理 普遍性定理は、どんな関数を学習するかに関わらず、大きなMLP であればその関数を表現できるということを意味している。しかし 訓練アルゴリズムがその関数を学習できるかどうかは保証されて いない。 ● 目的の関数に対応するパラメータの値を発見できない可能性 ● 訓練アルゴリズムは過剰適合が理由で間違った関数を選択 する可能性 1つの隠れ層を持つ順伝播型ネットワークは任意の関数を表現す るのに十分だが、その層は非現実的に大きなサイズとなる可能性 がある。多くの場合、より深いモデルを利用すると、目的の関数を 表現するために必要なユニットの数を減らし、汎化誤差も減らすこ とができる。 34
35.
深いモデルを使うことへの様々な解釈 学習したい関数が複数の単純な関数で構成されるという非常に 汎用的な信念を意味している。 統計的に 学習の問題は潜在的な変動要因を発見することであり、さらには それがもっと単純な他の潜在的な変動要因で記述できると考えら れる。 学習したい関数が複数のステップからなるコンピュータプログラム であり、その各ステップは直前のステップの出力を利用するという 信念を表現していると解釈できる。 表現学習的に コンピュータサイエンス的に 35
36.
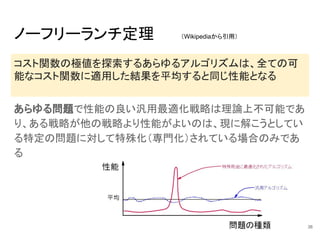
ノーフリーランチ定理 あらゆる問題で性能の良い汎用最適化戦略は理論上不可能であ り、ある戦略が他の戦略より性能がよいのは、現に解こうとしてい る特定の問題に対して特殊化(専門化)されている場合のみであ る 36 コスト関数の極値を探索するあらゆるアルゴリズムは、全ての可 能なコスト関数に適用した結果を平均すると同じ性能となる (Wikipediaから引用)
37.
ノーフリーランチ定理と普遍性定理 普遍性定理 順伝播ニューラルネットワークは任意の関数を任意の精度で近似 できる ノーフリーランチ定理 普遍的に優れた機械学習アルゴリズムは存在しない 37 ある関数が与えられたときに、その関数を任意の精度で近似でき る順伝播ネットワークが存在する。 関数を表現するための普遍的なシステム 普遍性定理 ノーフリーランチ定理
38.
まとめ 今日の内容は、 ● 機械学習を確率的な側面から見てみた ● 順伝播型ニューラルネットワークの構成要素を詳しく見てみた 使った参考書は、 ●
深層学習(第6章) ● これならわかる深層学習入門(第2章) もうちょっと詳しく知りたい人は、 ● 深層学習の最初から読んでみる 38
Download



























![[DL輪読会]Inverse Constrained Reinforcement Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20210709icrl-210709021811-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−](https://cdn.slidesharecdn.com/ss_thumbnails/20190415dlhacks-190422075753-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)























![[論文略説]Stochastic Thermodynamics Interpretation of Information Geometry](https://cdn.slidesharecdn.com/ss_thumbnails/aa-180330124241-thumbnail.jpg?width=640&height=640&fit=bounds)
