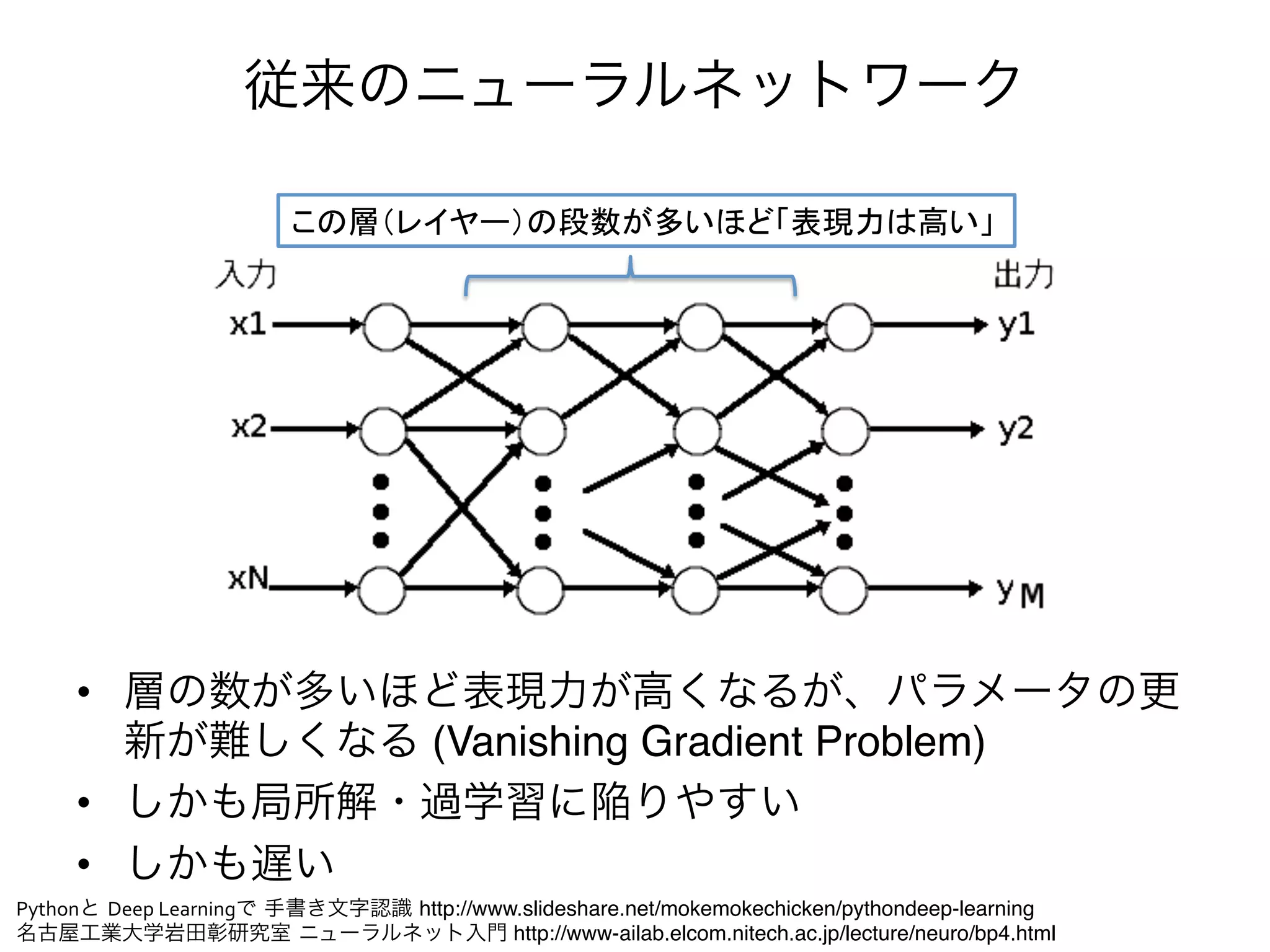
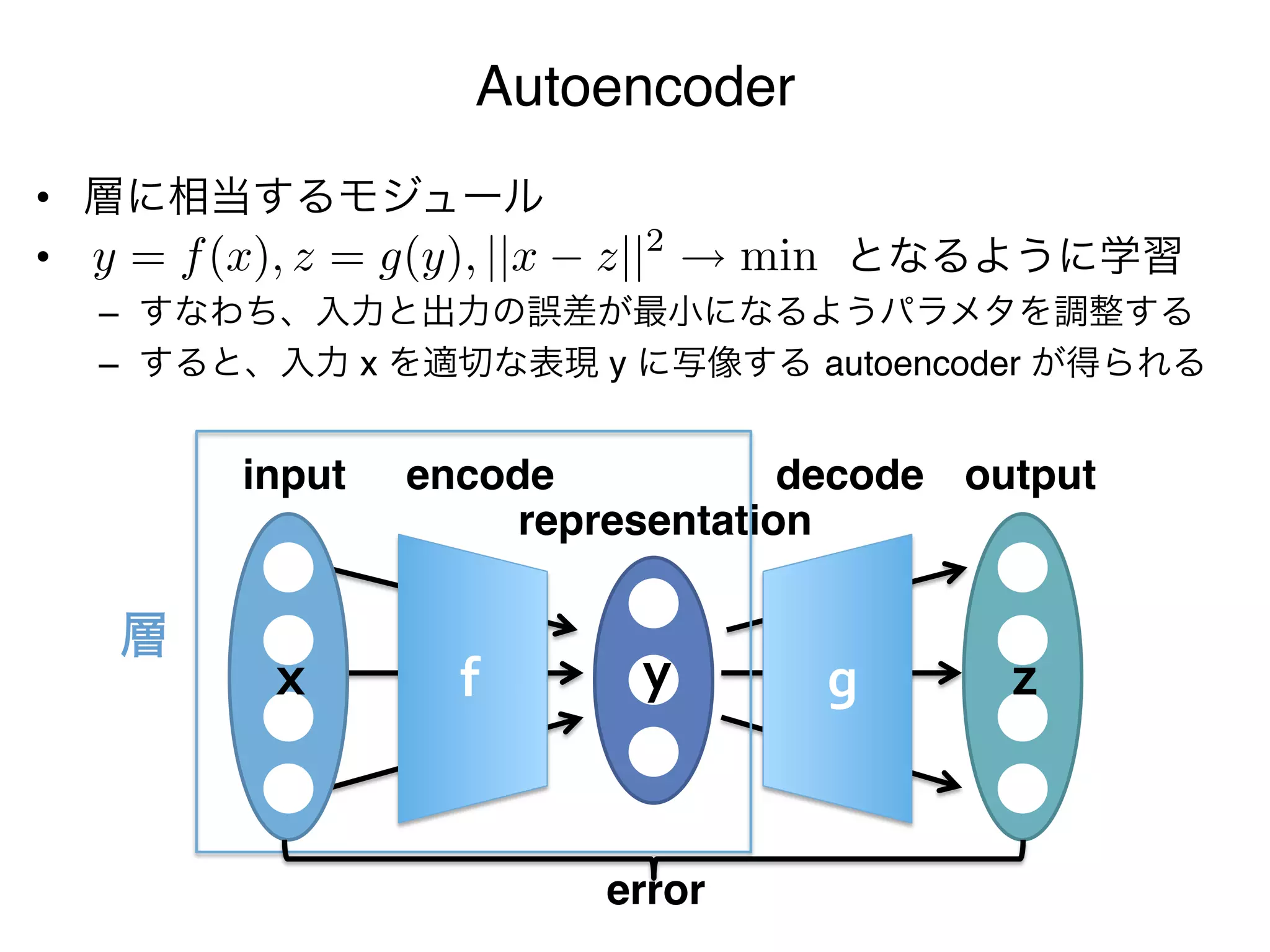
Autoencoder
• 層に相当するモジュール"
y = f (x), z = g(y), ||x z||2
• となるように学習" min
– すなわち、入力と出力の誤差が最小になるようパラメタを調整する"
– すると、入力 x を適切な表現 y に写像する autoencoder が得られる"
input encode decode output
representation
層
x f y g z
error
Denoising Autoencoder
• 下記の式で表されるエンコーダ、デコーダ、誤差を使う"
• s はシグモイド関数"
• 重み W, W’ とバイアス b, b’ を学習する"
• Tied Weights: W^T = W’ とすることもある"
encoder y = s(Wx + b), z = s(W x + b )
y = s(Wx + b), z = s(W x + b )
s(Wx + b), d = s(W x + b )
decoder z
d
H (x, z) =error LH (x, z) =zk + [xk logxk ) log(1xk ) zk )]
[xk log (1 zk + (1 log(1 zk )]
k log zk + (1k=1 k ) log(1 k=1 k )]
x z
input encode decode output
representation
x f y g z
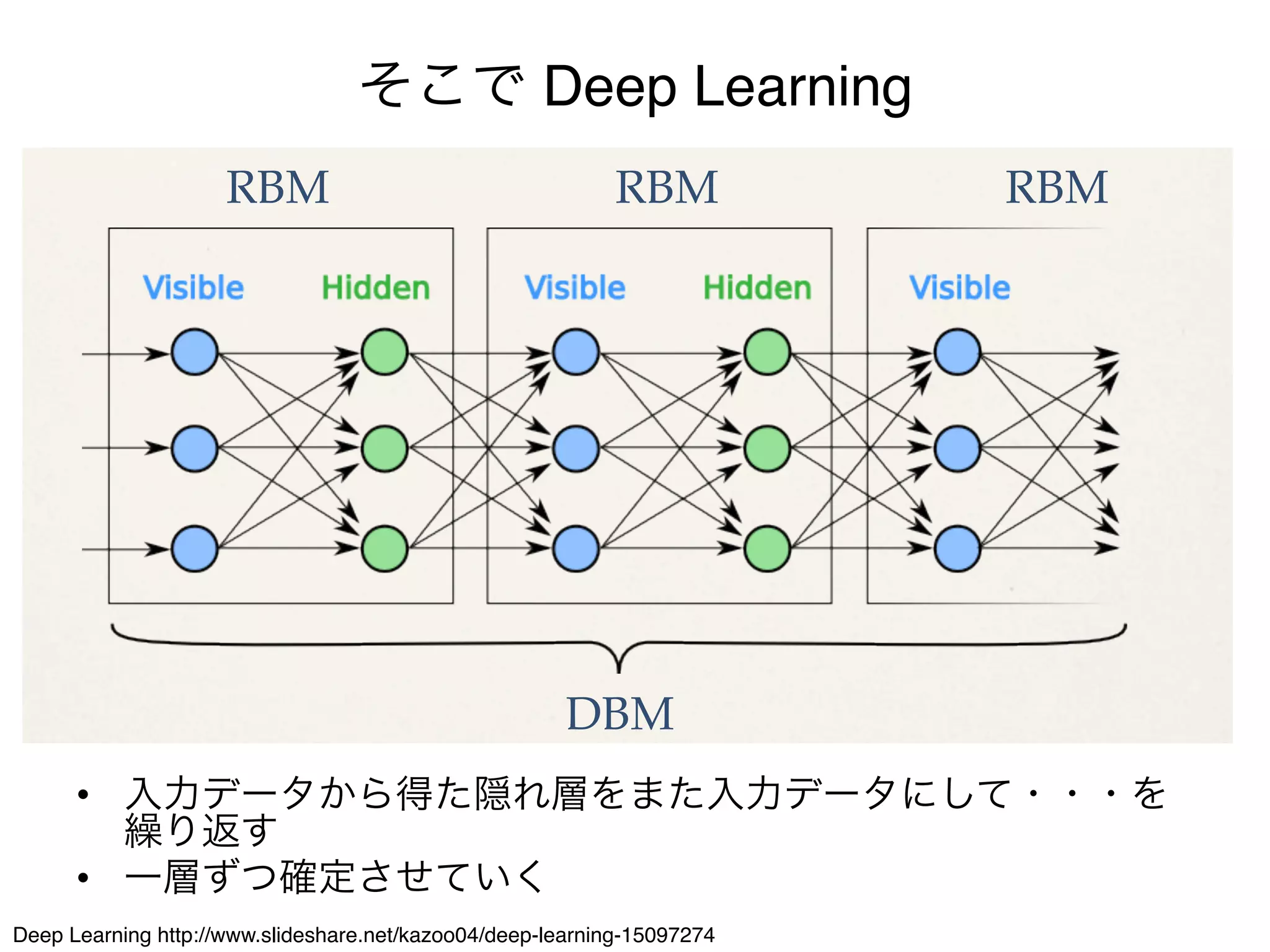
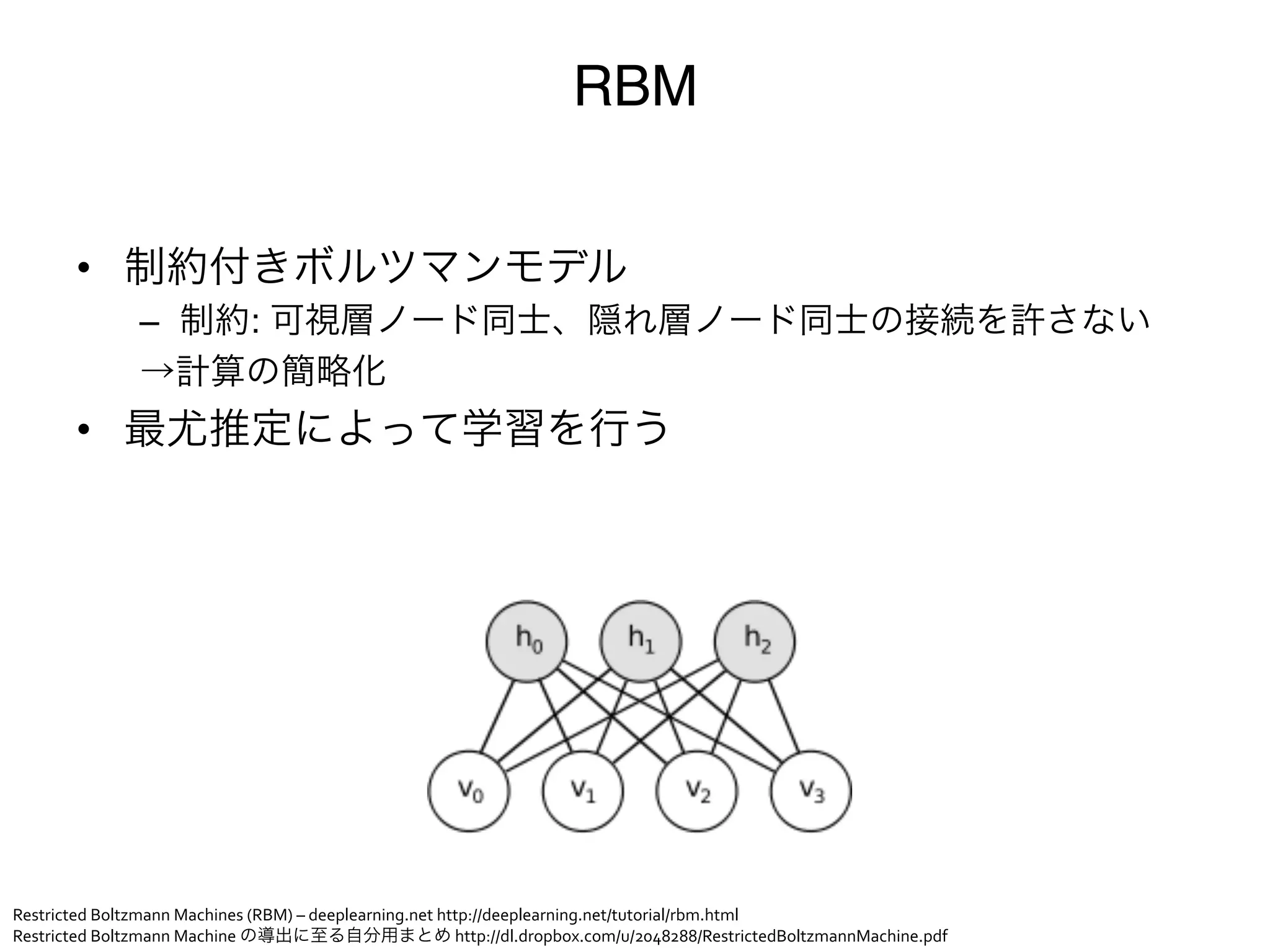
可視ノード集合 v( vi 0, 1) と隠れノード集合 h( hi 0, 1) からなる系
がその状態をとる確率 p(v, h) はエネルギー関数 E(v, h) と分散関数を用いて
以下のように定義される(c.f. カノニカル分布)。
E(v,h)
e
p(v, h) = (1)
Z
エネルギー関数 : E(x) = bT v cT h vT Wh (2)
分配関数 : Z = e E(v,h)
(3)
v h
v, h, W は可視層のバイアス、隠れ層のバイアス、重み行列と呼ばれるパラ
メタである。この系の尤度は、以下のように定義される。
尤度 J log p(v, h) q = log eE(v,h) q log Z (4)
h h
ただし f (v) q = v f (v)q(v), すなわち q は観測データの確率分布 q(v)
の期待値である。
尤度 J を任意のパラメタ について最大化するため、導関数を求める。
J 1 E 1 E
22.
ただし f (v) q = v f (v)q(v), すなわち q は観測データの確率分布 q(v)
の期待値である。
尤度 J を任意のパラメタ について最大化するため、導関数を求める。
J 1 E 1 E
= E
e E
q + e E
(5)
he h
Z v h
ここで、条件付き確率の定義 p(h|v) = より、
E(v,h)
Pe E(v,h)
h e
J E E
= p(h|v)q(v) + p(v, h) (6)
v h v h
E E
= p(h|v)q(v) + p(h,v) (7)
また、条件付き確率を計算して下記を得る(ここで厳密解を求められること
が「制限付き」の特徴)。
p(h|v) = s(Wv + b ) (8)
p(v|h) = s(Wh + b) (9)
ただし、s(x) はシグモイド関数である。
以上より、RBM は
References
• Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation
Learning: A Review and New Perspectives."
• Yoshua Bengio. Learning Deep Architectures for AI. "
• Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, Yoshua Bengio, Pierre-
Antoine Manzagol. Stacked Denoising Autoencoders: Learning Useful
Representations in a Deep Network with a Local Denoising Criterion"
• Deeplearning.net http://deeplearning.net/"
• Pythonと Deep Learningで 手書き文字認識
http://www.slideshare.net/mokemokechicken/pythondeep-learning"
• 名古屋工業大学岩田彰研究室 ニューラルネット入門
http://www-ailab.elcom.nitech.ac.jp/lecture/neuro/bp4.html"
• Deep Learning -株式会社ウサギィ 五木田 和也
http://www.slideshare.net/kazoo04/deep-learning-15097274"
• Restricted Boltzmann Machineの学習手法についての簡単なまとめ
http://mglab.blogspot.jp/2012/08/restricted-boltzmann-machine.html






![Denoising Autoencoder
• 下記の式で表されるエンコーダ、デコーダ、誤差を使う"
• s はシグモイド関数"
• 重み W, W’ とバイアス b, b’ を学習する"
• Tied Weights: W^T = W’ とすることもある"
encoder y = s(Wx + b), z = s(W x + b )
y = s(Wx + b), z = s(W x + b )
s(Wx + b), d = s(W x + b )
decoder z
d
H (x, z) =error LH (x, z) =zk + [xk logxk ) log(1xk ) zk )]
[xk log (1 zk + (1 log(1 zk )]
k log zk + (1k=1 k ) log(1 k=1 k )]
x z
input encode decode output
representation
x f y g z](https://image.slidesharecdn.com/121227deeplearningiitsuka-121228132014-phpapp01/75/Deep-Learning-9-2048.jpg)

![>>> # Theano のかんたんな使い方
>>> # まず、ふつうの演算
...
>>> import theano
>>> import theano.tensor as T
>>> x = T.dscalar(“x”) # x という名前のスカラー変数
>>> y = x**2 + 4*x # 式を表現
>>> f = theano.function([x], y) # 関数の生成。[]で囲まれた変数が関数の
引数となる
>>> f(0)
array(0.0)
>>> f(1)
array(5.0)
>>>
>>> # 次に、自動微分をさせてみる
...
>>> z = T.grad(y, x) # y を微分した式を z として表現
>>> f_prime = theano.function([x], z)
>>> f_prime(0)
array(4.0)
>>> f_prime(1)
array(6.0)](https://image.slidesharecdn.com/121227deeplearningiitsuka-121228132014-phpapp01/75/Deep-Learning-11-2048.jpg)

![def get_cost_updates(self, corruption_level, learning_rate):
tilde_x = self.get_corrupted_input(self.x, corruption_level)
y = encode(tilde_x)
z = decode(y)
L = - T.sum(self.x * T.log(z) + (1 - self.x) * T.log(1 - z),
axis=1)
cost = T.mean(L)
update(vbias, hbias, W) #パラメタの更新
return (cost, [vbias, hbias, W])
if __name__ == '__main__':
# 損傷率 0%, 30%, 50% の autoencoder
for c_rate in [0., 0.3, 0.5]:
da = dA(T.matrix(‘x’), 784, 500)
cost, updates = da.get_cost_updates(c_rate, 0.1)
train_da = theano.function(..., train_dataset, updates, cost)
img = PIL.Image.fromarray(da))
img.save(‘hoge’+c_rate+‘.png’)](https://image.slidesharecdn.com/121227deeplearningiitsuka-121228132014-phpapp01/75/Deep-Learning-14-2048.jpg)


![Tutorial からダウンロードしたプログラムを実行"
Corruption Rate = [0, 0.3, 0.5] に対応するフィルタ(重み行列 W)の例
o% 3o% 5o%](https://image.slidesharecdn.com/121227deeplearningiitsuka-121228132014-phpapp01/75/Deep-Learning-17-2048.jpg)









































![[DL輪読会]Understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170217-170217024917-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)




































