Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
MS
Uploaded by
Mikio Shiga
PPTX, PDF
869 views
Variational autoencoder
Variational Autoencoderの解説(AIMS 2019/11/09 発表資料)
Science
◦
Related topics:
Deep Learning
•
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 18
2
/ 18
3
/ 18
4
/ 18
5
/ 18
6
/ 18
7
/ 18
8
/ 18
9
/ 18
10
/ 18
11
/ 18
12
/ 18
13
/ 18
14
/ 18
15
/ 18
16
/ 18
17
/ 18
18
/ 18
More Related Content
PDF
数学で解き明かす深層学習の原理
by
Taiji Suzuki
PDF
[DL輪読会]Disentangling by Factorising
by
Deep Learning JP
PDF
Disentanglement Survey:Can You Explain How Much Are Generative models Disenta...
by
Hideki Tsunashima
PDF
Optimizer入門&最新動向
by
Motokawa Tetsuya
PPTX
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
PPTX
DNNの曖昧性に関する研究動向
by
Naoki Matsunaga
PPTX
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
by
Yosuke Shinya
PPTX
Deep Learningで似た画像を見つける技術 | OHS勉強会#5
by
Toshinori Hanya
数学で解き明かす深層学習の原理
by
Taiji Suzuki
[DL輪読会]Disentangling by Factorising
by
Deep Learning JP
Disentanglement Survey:Can You Explain How Much Are Generative models Disenta...
by
Hideki Tsunashima
Optimizer入門&最新動向
by
Motokawa Tetsuya
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
DNNの曖昧性に関する研究動向
by
Naoki Matsunaga
Active Convolution, Deformable Convolution ―形状・スケールを学習可能なConvolution―
by
Yosuke Shinya
Deep Learningで似た画像を見つける技術 | OHS勉強会#5
by
Toshinori Hanya
What's hot
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
PDF
[DL Hacks]Visdomを使ったデータ可視化
by
Deep Learning JP
PDF
[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions
by
Deep Learning JP
PDF
道具としての機械学習:直感的概要とその実際
by
Ichigaku Takigawa
PDF
PCAの最終形態GPLVMの解説
by
弘毅 露崎
PDF
[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning
by
Deep Learning JP
PDF
Anomaly detection 系の論文を一言でまとめた
by
ぱんいち すみもと
PDF
時系列問題に対するCNNの有用性検証
by
Masaharu Kinoshita
PDF
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
PDF
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
by
tmtm otm
PPTX
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
PDF
[DL輪読会]Deep Learning 第15章 表現学習
by
Deep Learning JP
PPTX
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
by
Deep Learning JP
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PDF
論文紹介「A Perspective View and Survey of Meta-Learning」
by
Kota Matsui
PDF
画像認識の初歩、SIFT,SURF特徴量
by
takaya imai
PDF
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
[DL Hacks]Visdomを使ったデータ可視化
by
Deep Learning JP
[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions
by
Deep Learning JP
道具としての機械学習:直感的概要とその実際
by
Ichigaku Takigawa
PCAの最終形態GPLVMの解説
by
弘毅 露崎
[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning
by
Deep Learning JP
Anomaly detection 系の論文を一言でまとめた
by
ぱんいち すみもと
時系列問題に対するCNNの有用性検証
by
Masaharu Kinoshita
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会)
by
narumikanno0918
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
by
tmtm otm
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
[DL輪読会]Deep Learning 第15章 表現学習
by
Deep Learning JP
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
by
Deep Learning JP
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
深層生成モデルと世界モデル
by
Masahiro Suzuki
論文紹介「A Perspective View and Survey of Meta-Learning」
by
Kota Matsui
画像認識の初歩、SIFT,SURF特徴量
by
takaya imai
変分推論法(変分ベイズ法)(PRML第10章)
by
Takao Yamanaka
Similar to Variational autoencoder
PDF
Deep Learning を実装する
by
Shuhei Iitsuka
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
PDF
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
PPTX
パターン認識モデル初歩の初歩
by
t_ichioka_sg
PDF
行列およびテンソルデータに対する機械学習(数理助教の会 2011/11/28)
by
ryotat
PDF
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
PDF
音学シンポジウム2025「ニューラルボコーダ概説:生成モデルと実用性の観点から」
by
NU_I_TODALAB
PDF
20170422 数学カフェ Part2
by
Kenta Oono
PDF
FOBOS
by
Hidekazu Oiwa
PDF
FEPチュートリアル2021 講義3 「潜在変数が連続値、生成モデルが正規分布の場合」の改良版
by
Masatoshi Yoshida
PDF
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
PDF
Unified Expectation Maximization
by
Koji Matsuda
PDF
[DL輪読会]Control as Inferenceと発展
by
Deep Learning JP
PDF
PATTERN RECOGNITION AND MACHINE LEARNING (1.1)
by
Yuma Yoshimoto
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PDF
「トピックモデルによる統計的潜在意味解析」読書会 4章前半
by
koba cky
PDF
A Brief Survey of Schrödinger Bridge (Part I)
by
Morpho, Inc.
PDF
Learning Latent Space Energy Based Prior Modelの解説
by
Tomonari Masada
PDF
Crfと素性テンプレート
by
Kei Uchiumi
Deep Learning を実装する
by
Shuhei Iitsuka
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
パターン認識モデル初歩の初歩
by
t_ichioka_sg
行列およびテンソルデータに対する機械学習(数理助教の会 2011/11/28)
by
ryotat
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
音学シンポジウム2025「ニューラルボコーダ概説:生成モデルと実用性の観点から」
by
NU_I_TODALAB
20170422 数学カフェ Part2
by
Kenta Oono
FOBOS
by
Hidekazu Oiwa
FEPチュートリアル2021 講義3 「潜在変数が連続値、生成モデルが正規分布の場合」の改良版
by
Masatoshi Yoshida
【Zansa】第12回勉強会 -PRMLからベイズの世界へ
by
Zansa
Unified Expectation Maximization
by
Koji Matsuda
[DL輪読会]Control as Inferenceと発展
by
Deep Learning JP
PATTERN RECOGNITION AND MACHINE LEARNING (1.1)
by
Yuma Yoshimoto
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
「トピックモデルによる統計的潜在意味解析」読書会 4章前半
by
koba cky
A Brief Survey of Schrödinger Bridge (Part I)
by
Morpho, Inc.
Learning Latent Space Energy Based Prior Modelの解説
by
Tomonari Masada
Crfと素性テンプレート
by
Kei Uchiumi
Variational autoencoder
1.
0 Variational Autoencoder
2.
1 論文 Auto-Encoding Variational Bayes D.P.
Kingma, M. Welling, ICLR 2014. Tutorial on Variational Autoencoders CARL DOERSCH, 2016 https://arxiv.org/abs/1606.05908 元論文 元論文の解説
3.
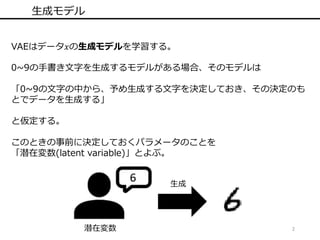
2 生成モデル VAEはデータ𝑥の生成モデルを学習する。 0~9の手書き文字を生成するモデルがある場合、そのモデルは 「0~9の文字の中から、予め生成する文字を決定しておき、その決定のも とでデータを生成する」 と仮定する。 このときの事前に決定しておくパラメータのことを 「潜在変数(latent variable)」とよぶ。 6 潜在変数 生成
4.
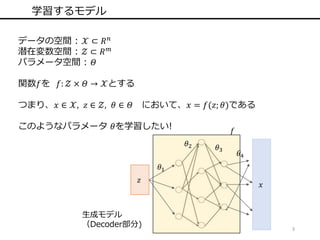
3 学習するモデル データの空間 : 𝒳
⊂ 𝑅 𝑛 潜在変数空間 : 𝒵 ⊂ 𝑅 𝑚 パラメータ空間 : 𝛩 関数𝑓を 𝑓: 𝒵 × 𝛩 → 𝒳とする つまり、𝑥 ∈ 𝒳, 𝑧 ∈ 𝒵, 𝜃 ∈ 𝛩 において、𝑥 = 𝑓(𝑧; 𝜃)である このようなパラメータ 𝜃を学習したい! 𝑧 𝑓 𝜃1 𝜃2 𝜃3 𝑥 𝜃4 生成モデル (Decoder部分)
5.
4 学習するモデル VAEはデータ𝑥を生成するモデルを作りたい →固定のパラメータ𝜃のもと、確率分布𝑝(𝑧)に基づいて決まる潜在変数𝑧が 与えられたときに、生成されたデータ𝑥が訓練データに近いものになるよ うなモデルを作りたい。 𝑥を生成するモデルを𝑝 𝜃 𝑥
𝑧 とおく。VAEは 𝑝 𝑧 = 𝒩 𝑧 0, 𝐼 𝑝 𝜃 𝑥 𝑧 = 𝑙 𝑥; 𝑧, 𝜃 を仮定している。 ここで𝑙 𝑥; 𝑧, 𝜃 は𝑧の尤度関数で、𝑙 𝑥; 𝑧, 𝜃 = 𝒩 𝑥 𝑓 𝑧; 𝜃 , 𝜎2 ∙ 𝐼 を仮定する。 (𝜎2 はハイパーパラメータ) 最適な𝑝 𝜃 𝑥 𝑧 を探すために、以下に示す𝑝 𝜃 𝑥 𝑧 の周辺尤度 𝑝 𝜃 𝑥 = 𝑝 𝜃 𝑥 𝑧 𝑝 𝑧 𝑑𝑧 を最大化する𝜃, 𝑧を探す。
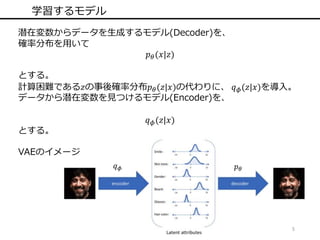
6.
5 学習するモデル 潜在変数からデータを生成するモデル(Decoder)を、 確率分布を用いて 𝑝 𝜃(𝑥|𝑧) とする。 計算困難である𝑧の事後確率分布𝑝 𝜃(𝑧|𝑥)の代わりに、
𝑞 𝜙(𝑧|𝑥)を導入。 データから潜在変数を見つけるモデル(Encoder)を、 𝑞 𝜙(𝑧|𝑥) とする。 VAEのイメージ 𝑞 𝜙 𝑝 𝜃
7.
6 パラメータ𝜃の学習 𝑝 𝜃(𝑥)を最大化するために、パラメータ𝜃を最適化したいが、 𝑝 𝜃(𝑥)は𝜃で微分できないため直接𝜃を最適化できない。 →目的関数を近似的に設定する。 →変分ベイズ同様、尤度の下限(変分下限)を最大化する log
𝑝 𝜃 𝑥 = log 𝑝 𝜃 𝑥 𝑧 𝑝 𝑧 𝑑𝑧 = log 𝑞 𝜙 𝑧 𝑥 𝑝 𝜃 𝑥 𝑧 𝑝 𝑧 𝑞 𝜙 𝑧 𝑥 𝑑𝑧 ≥ 𝑞 𝜙 𝑧 𝑥 log 𝑝 𝜃 𝑥 𝑧 𝑝 𝑧 𝑞 𝜙 𝑧 𝑥 𝑑𝑧 (イェンセンの不等式) = 𝑞 𝜙 𝑧 𝑥 log 𝑝 𝑧 𝑞 𝜙 𝑧 𝑥 + log 𝑝 𝜃 𝑥 𝑧 𝑑𝑧 = 𝑞 𝜙 𝑧 𝑥 log 𝑝 𝜃 𝑥 𝑧 𝑑𝑧 − 𝑞 𝜙 𝑧 𝑥 log 𝑞 𝜙 𝑧 𝑥 𝑝 𝑧 𝑑𝑧 = 𝐸 𝑧~𝑞 𝜙 𝑧 𝑥 log 𝑝 𝜃 𝑥 𝑧 − 𝐷 𝐾𝐿 𝑞 𝜙 𝑧 𝑥 𝑝(𝑧))
8.
7 Encoderの最適化による目的関数の導出 計算困難である𝑧の事後確率分布𝑝 𝜃(𝑧|𝑥)の代わりに、 𝑞
𝜙(𝑧|𝑥)を導入。 Encoderは𝑞 𝜙(𝑧|𝑥)を予測する。 Encoderの予測が正しいかどうかは𝑞 𝜙(𝑧|𝑥)と𝑝 𝜃(𝑧|𝑥)の差をみてやればよい →KL距離を計算する 𝐾𝐿 𝑞 𝜙 𝑧 𝑥 ||𝑝 𝜃 𝑧 𝑥 = 𝑞 𝜙 𝑧 𝑥 log 𝑞 𝜙 𝑧 𝑥 𝑝 𝑧 𝑑𝑧 = 𝑞 𝜙 𝑧 𝑥 log 𝑞 𝜙 𝑧 𝑥 − log 𝑝 𝜃 𝑧 𝑥 𝑑𝑧 = 𝑞 𝜙 𝑧 𝑥 {log𝑞 𝜙 𝑧 𝑥 − log 𝑝 𝜃 x z 𝑝 z 𝑝 𝜃(𝑥) }𝑑𝑧 = log𝑝 𝜃 𝑥 + 𝑞 𝜙 𝑧 𝑥 log 𝑞 𝜙 𝑧 𝑥 𝑝 𝑧 𝑑𝑧 − 𝑞 𝜙 𝑧 𝑥 log 𝑝 𝜃 𝑥 𝑧 𝑑𝑧 = log𝑝 𝜃 𝑥 + 𝐾𝐿(𝑞 𝜙 𝑧 𝑥 𝑝(𝑧) − 𝐸 𝑧~𝑞 𝜙 𝑧 𝑥 log𝑝 𝜃 𝑥 𝑧
9.
8 Encoderの最適化による目的関数の導出 𝐾𝐿 𝑞 𝜙
𝑧 𝑥 ||𝑝 𝜃 𝑧 𝑥 = log𝑝 𝜃 𝑥 + 𝐾𝐿 𝑞 𝜙 𝑧 𝑥 ||𝑝(𝑧) − 𝐸 𝑧~𝑞 𝜙 𝑧 𝑥 log𝑝 𝜃 𝑥 𝑧 log 𝑝 𝜃 𝑥 − 𝐾𝐿 𝑞 𝜙 𝑧 𝑥 ||𝑝 𝜃 𝑧 𝑥 = 𝐸 𝑧~𝑞 𝜙 𝑧 𝑥 log𝑝 𝜃 𝑥 𝑧 − 𝐾𝐿 𝑞 𝜙 𝑧 𝑥 ||𝑝 𝜃(𝑧) KLは非負より、 log𝑝 𝜃 𝑥 ≥ 𝐸 𝑧~𝑞 𝜙 𝑧 𝑥 log𝑝 𝜃 𝑥 𝑧 − 𝐾𝐿 𝑞 𝜙 𝑧 𝑥 ||𝑝(𝑧) となる。(変分下限で求めたものと同じ!) よって、VAEの損失関数は、 ℒ 𝜃, 𝜙, 𝑥 = −log 𝑝 𝜃(𝑥) となり、上式から ℒ′ = −𝐸 𝑧~𝑞 𝜙 𝑧 𝑥 log 𝑝 𝜃 𝑥 𝑧 + 𝐾𝐿 𝑞 𝜙 𝑧 𝑥 ||𝑝(𝑧) を最小化する
10.
9 損失関数の意味 ℒ′ = −𝐸
𝑧~𝑞 𝜙 𝑧 𝑥 log 𝑝 𝜃 𝑥 𝑧 + 𝐾𝐿 𝑞 𝜙 𝑧 𝑥 ||𝑝(𝑧) 第一項 𝐸 𝑧~𝑞 𝜙 𝑧 𝑥 log 𝑝 𝜃 𝑥 𝑧 𝑞 𝜙 𝑧 𝑥 からサンプリングした𝑧を用いて、 𝑝 𝜃 𝑥 𝑧 からサンプリングして得 られた𝑥がもとの𝑥(入力データ)である度合い。 (𝑥 ⟶ 𝑧 ⟶ 𝑥というオートエンコーダを考えている。) 複号誤差と呼ばれる。 第二項 𝐾𝐿 𝑞 𝜙 𝑧 𝑥 ||𝑝(𝑧) 𝑞 𝜙 𝑧 𝑥 が𝑝(𝑧)からどれだけ離れているかを示す。 𝑞 𝜙 𝑧 𝑥 を𝑥に無関係な𝑝(𝑧)に近づけることで過学習を防ぐ。 正則化項と呼ばれる。
11.
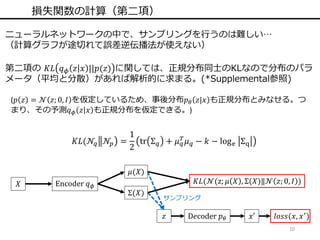
10 損失関数の計算(第二項) 𝑋 Encoder 𝑞
𝜙 𝜇(𝑋) Σ(𝑋) 𝐾𝐿(𝒩(z; 𝜇 𝑋 , Σ(𝑋)‖𝒩 𝑧; 0, 𝐼 ) 𝑧 D𝑒coder 𝑝 𝜃 𝑥′ 𝑙𝑜𝑠𝑠(𝑥, 𝑥′) ニューラルネットワークの中で、サンプリングを行うのは難しい… (計算グラフが途切れて誤差逆伝播法が使えない) 第二項の 𝐾𝐿 𝑞 𝜙 𝑧 𝑥 ||𝑝(𝑧) に関しては、正規分布同士のKLなので分布のパラ メータ(平均と分散)があれば解析的に求まる。(*Supplemental参照) (𝑝 𝑧 = 𝒩 𝑧; 0, 𝐼 を仮定しているため、事後分布𝑝 𝜃 𝑧|𝑥 も正規分布とみなせる。つ まり、その予測𝑞 𝜙 𝑧 𝑥 も正規分布を仮定できる。) 𝐾𝐿(𝒩𝑞 𝒩𝑝 = 1 2 tr Σ 𝑞 + 𝜇 𝑞 𝑇 𝜇 𝑞 − 𝑘 − loge Σq サンプリング
12.
11 損失関数の計算(第一項) では、第一項 𝐸 𝑧~𝑞
𝜙 𝑧 𝑥 log 𝑝 𝜃 𝑥 𝑧 は? 期待値はサンプリング近似で求める 𝐸 𝑧~𝑞 𝜙 𝑧 𝑥 log 𝑝 𝜃 𝑥 𝑧 ≃ 1 𝐿 𝑙=1 𝐿 log 𝑝(𝑥|𝑧 𝑙) 𝐿個の𝑧を𝑞 𝜙 𝑧 𝑥 からサンプリングし、それぞれの𝑧, 𝑥から求めた log 𝑝 𝜃(𝑥|𝑧)の平均を期待値とする。 しかし、このままだと結局𝑧のサンプリングを行わないといけない (ニューラルネットワークだと使えない) →確率分布に従ってサンプリングするのではなく、関数から決定論的に𝑧 を生成する
13.
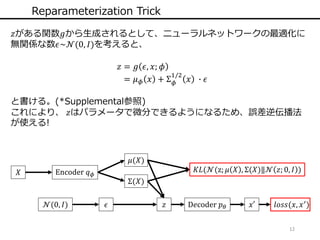
12 Reparameterization Trick 𝑧がある関数𝑔から生成されるとして、ニューラルネットワークの最適化に 無関係な数𝜖~𝒩(0, 𝐼)を考えると、 𝑧
= 𝑔 𝜖, 𝑥; 𝜙 = 𝜇 𝜙 𝑥 + Σ 𝜙 1/2 𝑥 ∙ 𝜖 と書ける。(*Supplemental参照) これにより、 𝑧はパラメータで微分できるようになるため、誤差逆伝播法 が使える! 𝑋 Encoder 𝑞 𝜙 𝜇(𝑋) Σ(𝑋) 𝐾𝐿(𝒩(z; 𝜇 𝑋 , Σ(𝑋)‖𝒩 𝑧; 0, 𝐼 ) 𝑧 D𝑒coder 𝑝 𝜃 𝑥′ 𝑙𝑜𝑠𝑠(𝑥, 𝑥′)𝒩(0, 𝐼) 𝜖
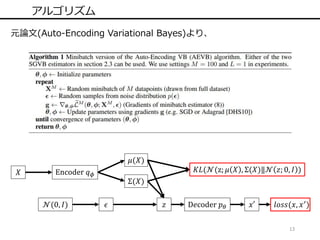
14.
13 アルゴリズム 元論文(Auto-Encoding Variational Bayes)より、 𝑋
Encoder 𝑞 𝜙 𝜇(𝑋) Σ(𝑋) 𝐾𝐿(𝒩(z; 𝜇 𝑋 , Σ(𝑋)‖𝒩 𝑧; 0, 𝐼 ) 𝑧 D𝑒coder 𝑝 𝜃 𝑥′ 𝑙𝑜𝑠𝑠(𝑥, 𝑥′)𝒩(0, 𝐼) 𝜖
15.
14 Supplemental 正規分布同士のKL距離 𝒩 𝜇,
Σ = 1 2𝜋 𝑑 Σ exp − 1 2 𝑥 − 𝜇 𝑇Σ−1 𝑥 − 𝜇 以下に示す、平均𝜇共分散行列Σのd次元多変量正規分布を考える。 二つの正規分布𝑝 𝑥 = 𝒩 𝜇1, Σ1 , 𝑞 𝑥 = 𝒩 𝜇2, Σ2 のKL距離を考える。 𝐷 𝐾𝐿(𝑃 𝑄 = −∞ ∞ 𝑝 𝑥 log 𝑝 𝑥 𝑞 𝑥 𝑑𝑥 log 𝑝 𝑥 𝑞 𝑥 = 1 2 log Σ2 Σ1 + 1 2 𝑥 − 𝜇2 𝑇Σ2 −1 𝑥 − 𝜇2 − 1 2 𝑥 − 𝜇1 𝑇Σ1 −1 (𝑥 − 𝜇1) logの中身について展開する。 KL距離を期待値で表すと、以下のようになる。 𝐷 𝐾𝐿(𝑃 𝑄 = 𝐸 𝑝 1 2 log Σ2 Σ1 + 𝐸 𝑝 1 2 𝑥 − 𝜇2 𝑇 Σ2 −1 𝑥 − 𝜇2 − 𝐸 𝑝 1 2 𝑥 − 𝜇1 𝑇 Σ1 −1 𝑥 − 𝜇1
16.
15 Supplemental 正規分布同士のKL距離 第一項は定数なので、 𝐸 𝑝 1 2 log Σ2 Σ1 = 1 2 log Σ2 Σ1 The
matrix Cookbook(http://orion.uwaterloo.ca/~hwolkowi/matrixcookbook.pdf) の式(380)同様、第二項以降は次のようになる。 𝐸 𝑝 1 2 𝑥 − 𝜇2 𝑇Σ2 −1 𝑥 − 𝜇2 = 1 2 tr Σ2 −1 Σ1 + 𝜇1 − 𝜇2 𝑇Σ2 −1 𝜇1 − 𝜇2 𝐸 𝑝 1 2 𝑥 − 𝜇1 𝑇Σ1 −1 𝑥 − 𝜇1 = 1 2 tr Σ1 −1 Σ1 = 𝑑 2 よって、これらをまとめて = 1 2 log Σ2 Σ1 + tr Σ2 −1 Σ1 + 𝜇1 − 𝜇2 𝑇 Σ2 −1 𝜇1 − 𝜇2 − 𝑑 𝐷 𝐾𝐿(𝑃 𝑄 = 𝐸 𝑝 1 2 log Σ2 Σ1 + 𝐸 𝑝 1 2 x − 𝜇2 𝑇 Σ2 −1 𝑥 − 𝜇2 − 𝐸 𝑝 1 2 𝑥 − 𝜇1 𝑇 Σ1 −1 𝑥 − 𝜇1
17.
16 Supplemental 多変量正規分布に従う乱数の生成 𝒩 (𝜇
𝜙, Σ 𝜙)に従う乱数𝑧を𝒩 (0, 𝐼)に従う乱数𝜖を用いて生成する。 ここで𝑦 = 𝑄𝑧が𝒩 (0, Σ 𝜙)に従うとすると、 𝑦′ = 𝑦 + 𝜇 𝜙は𝒩 (𝜇 𝜙, Σ 𝜙)に従う。 よって、 𝑦 = 𝑄𝑧となるQを求める。 𝐸 𝑌 = 𝐸 𝑄𝑍 = 𝑄𝐸 𝑍 = 0 𝑉 𝑌 = 𝐸 𝑌 − 𝐸 𝑌 𝑌 − 𝐸 𝑌 𝑇 = 𝐸 𝑄𝑍 𝑄𝑍 𝑇 = 𝑄𝐸 𝑍 − 𝐸 𝑍 𝑍 − 𝐸 𝑍 𝑇 𝑄 𝑇 = 𝑄𝑉 𝐸 𝑄 𝑇 = 𝑄𝑄 𝑇 より、Σ 𝜙 = 𝑄𝑄 𝑇 となるように𝑄を定める。(コレスキー分解) よって、 𝑧 = 𝜇 𝜙 𝑥 + Σ 𝜙 1/2 𝑥 ∙ 𝜖 と書ける。
18.
17 参考 Auto-Encoding Variational Bays https://arxiv.org/abs/1312.6114 Tutorial
on Variational Autoencoders https://arxiv.org/abs/1606.05908 http://musyoku.github.io/2016/04/29/auto-encoding-variational-bayes/ 元論文解説記事 VAE解説pdf https://nzw0301.github.io/notes/vae.pdf The matrix Cookbook (行列演算公式集) http://orion.uwaterloo.ca/~hwolkowi/matrixcookbook.pdf https://www.youtube.com/watch?v=7CPcvLs8iEs 確率的ニューラルネットの解説 http://www.ee.bgu.ac.il/~rrtammy/DNN/StudentPresentations/AutoEncoderOrZalman.pdf 元論文著者のスライド
Download













![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL Hacks]Visdomを使ったデータ可視化](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20181115-181116004623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Glow: Generative Flow with Invertible 1×1 Convolutions](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20180720-180723071258-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)





