Downloaded 30 times

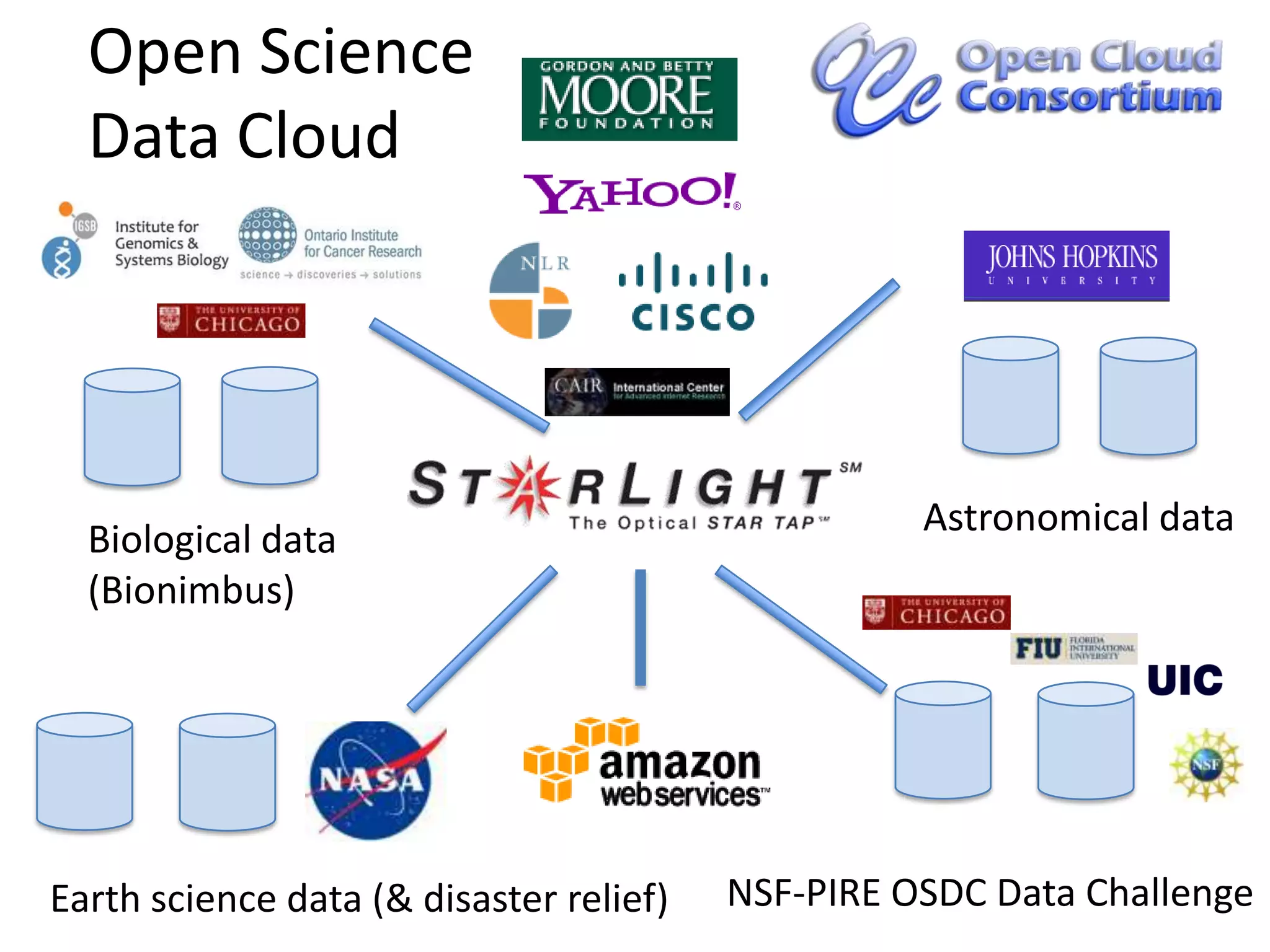



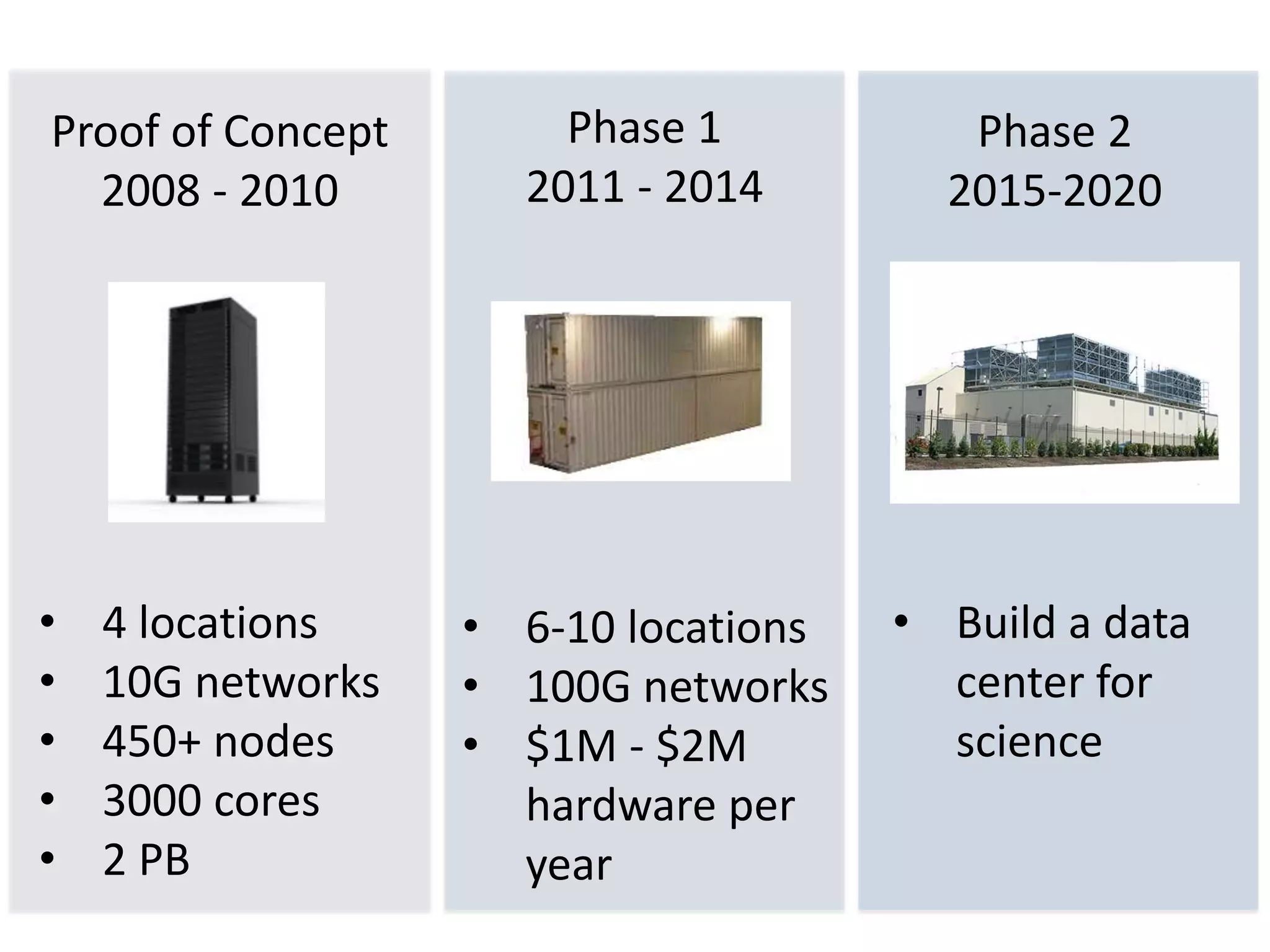

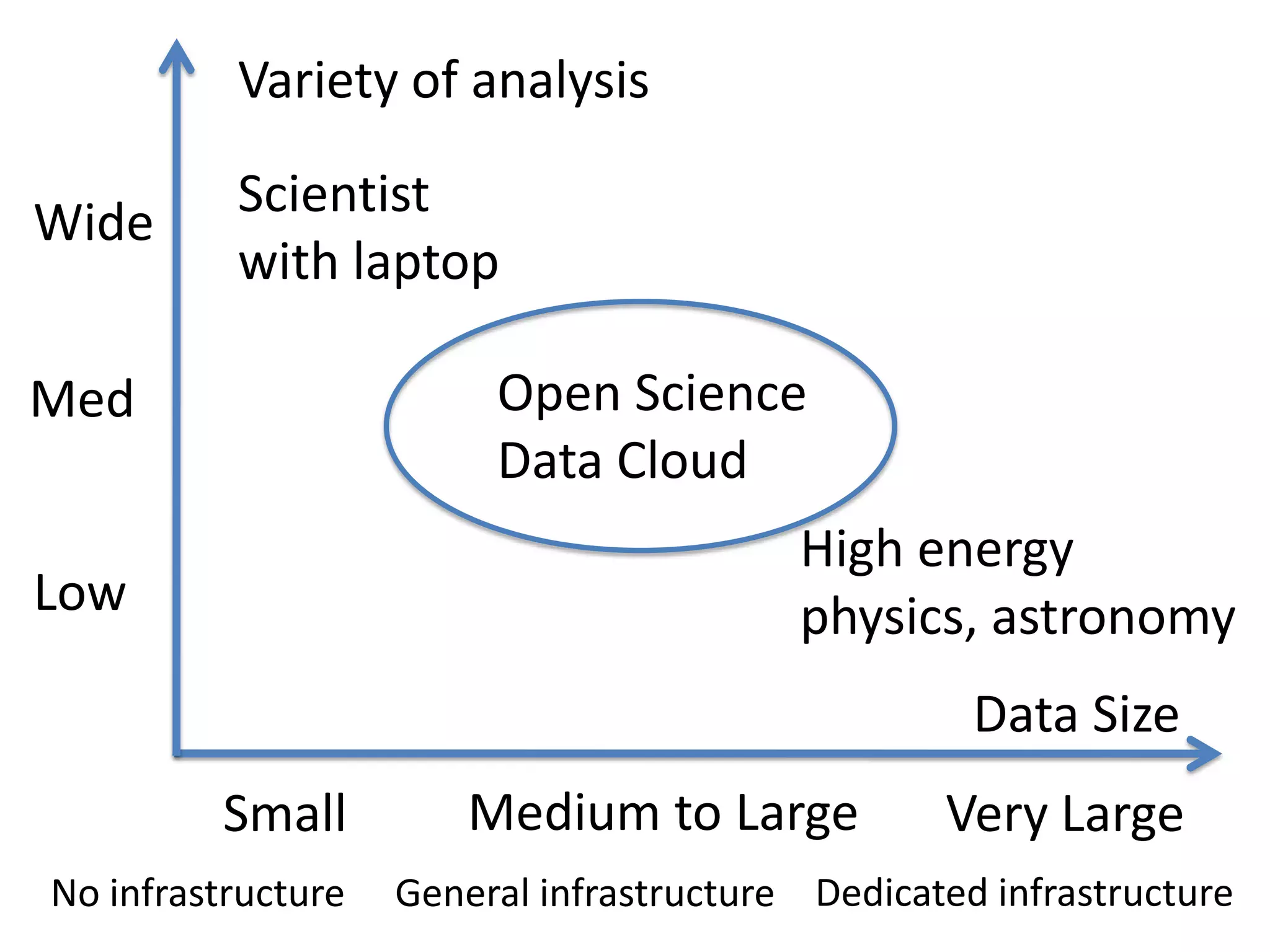
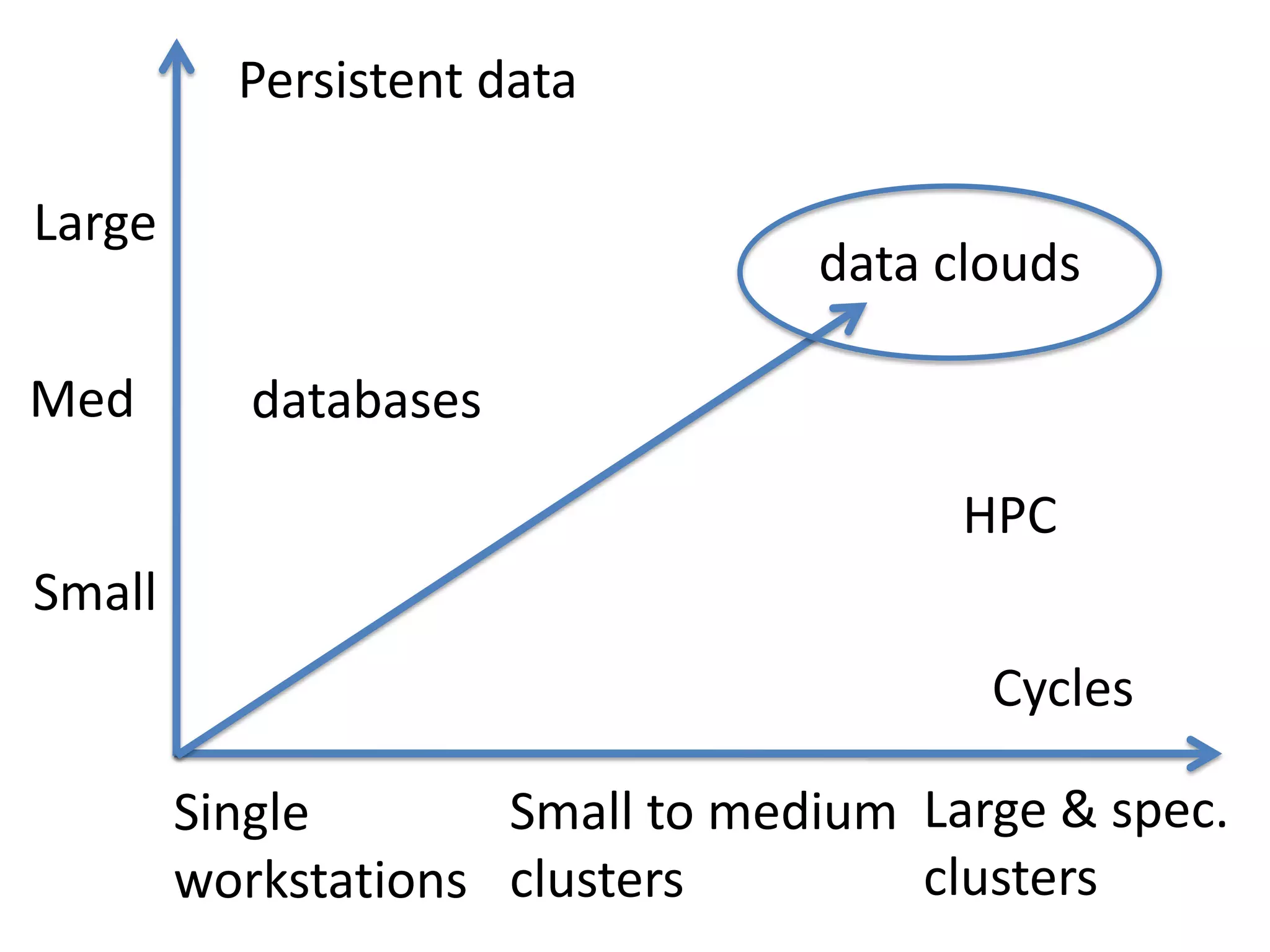











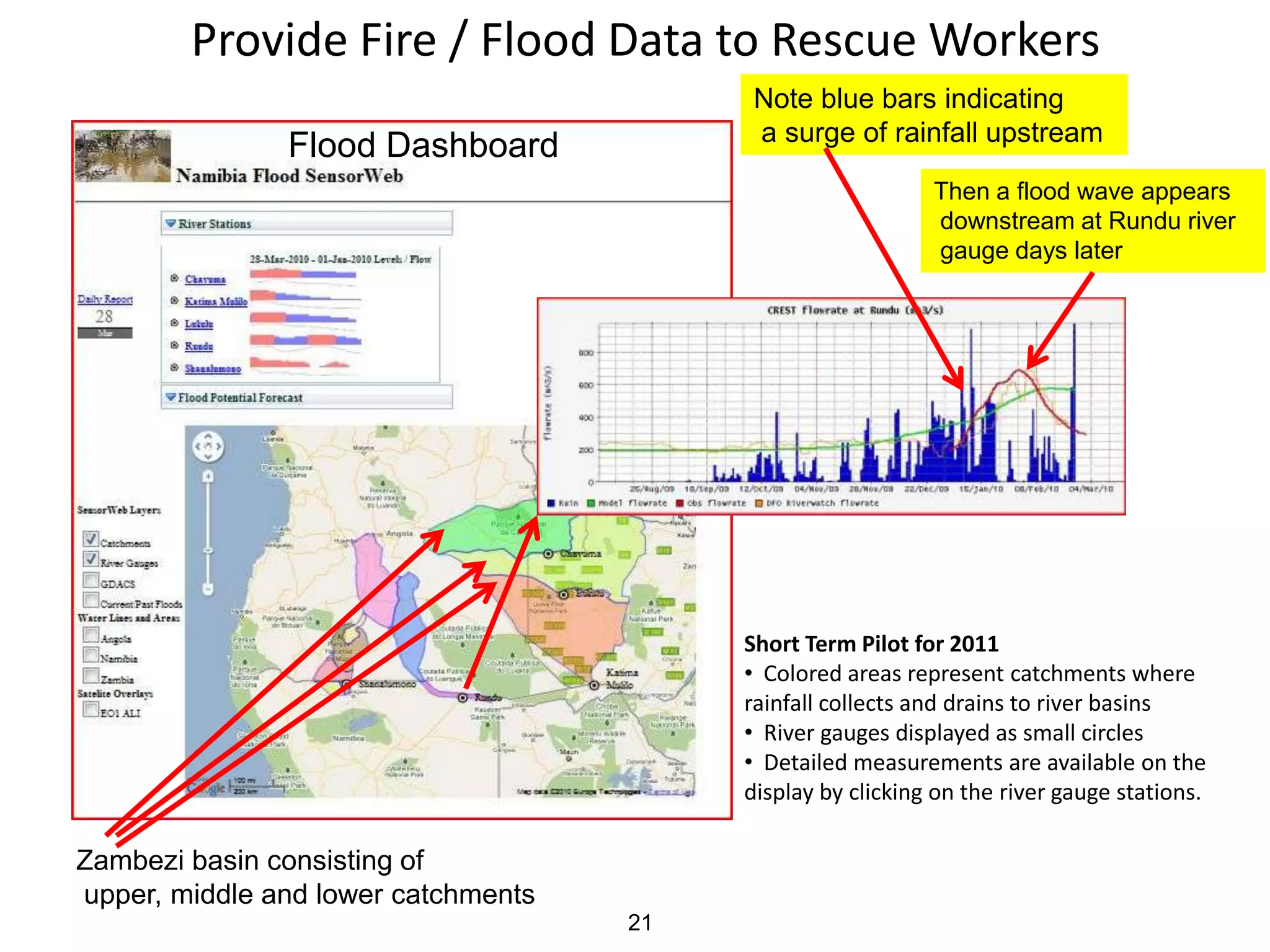












The Open Science Data Cloud is a hosted, managed, distributed facility that allows scientists to manage and archive medium and large datasets, provide computational resources to analyze the data, and share the data with colleagues and the public. It currently consists of 6 racks, 212 nodes, 1568 cores and 0.9 PB of storage across 4 locations with 10G networks. Projects using the Open Science Data Cloud include Bionimbus for hosting genomics data and Matsu 2 for providing flood data to disaster response teams. The goal is to build it out over the next 10 years into a small data center for science that can preserve data like libraries and museums preserve collections.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















