Download to read offline






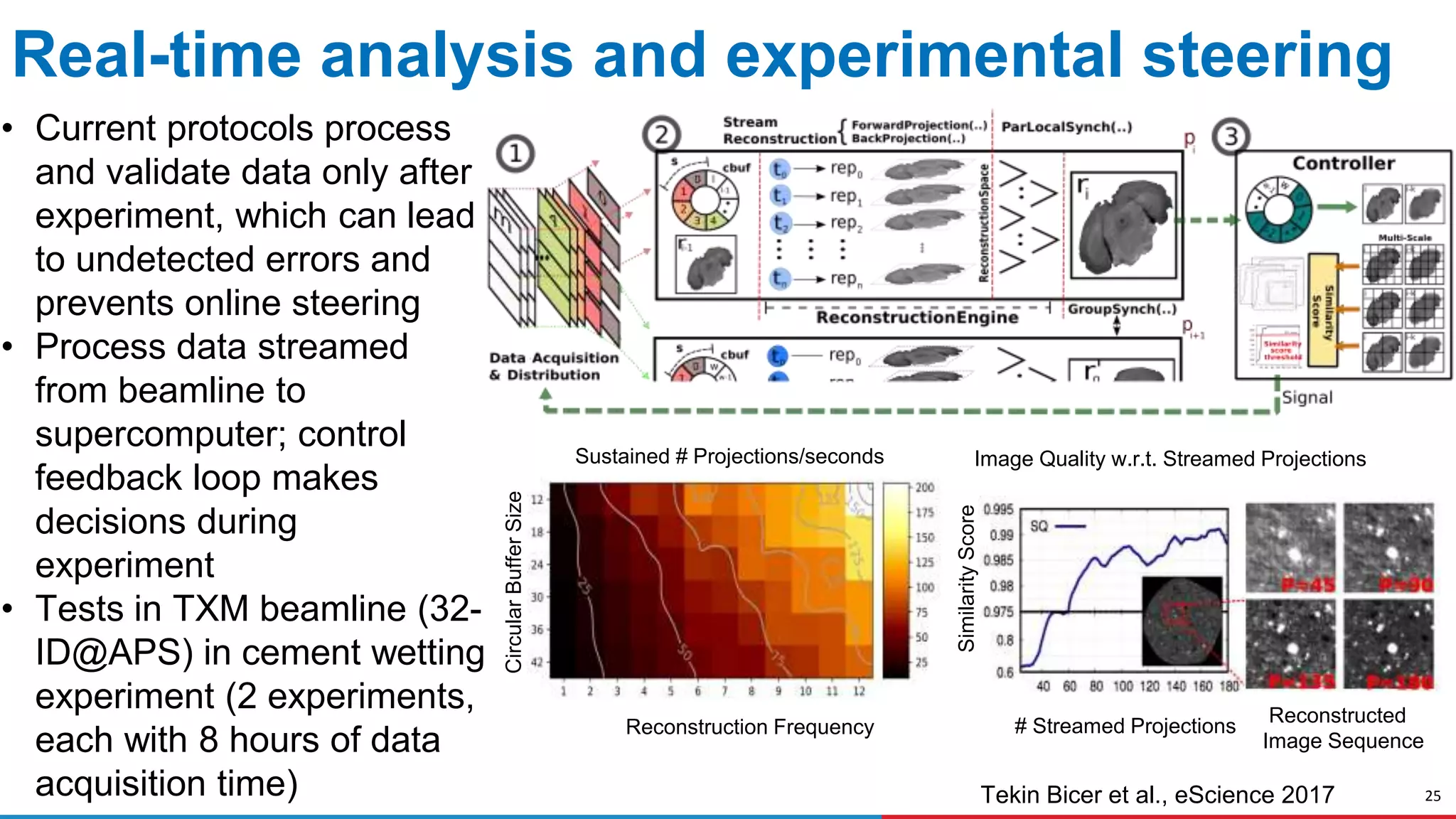
![22
The need for online data analysis and reduction
Traditional approach:
Simulate, output, analyze
Write simulation output to secondary
storage; read back for analysis
Decimate in time when simulation
output rate exceeds output rate of
computer
Online: y = F(x)
Offline: a = A(y), b= B(y), …
New approach:
Online data analysis & reduction
Co-optimize simulation, analysis,
reduction for performance and
information output
Substitute CPU cycles for I/O, via online
data (de)compression and/or analysis
a) Online: a = A(F(x)), b = B(F(x)), …
b) Online: r = R(F(x))
Offline: a = A’(r), b = B’(r), or
a = A(U(r)), b = B(U(r))
[R = reduce, U = un-reduce]](https://image.slidesharecdn.com/hipc-foster-december-2017-180116162417/75/Computing-Just-What-You-Need-Online-Data-Analysis-and-Reduction-at-Extreme-Scales-22-2048.jpg)
![23
Exascale computing at Argonne by 2021
Precision medicine
Data from
sensors and
scientific
instruments
Simulation and
modeling of
materials and
physical
systems
Support for three types of computing:
Traditional: HPC simulation and modeling
Learning: Machine learning, deep learning, AI
Data: Data analytics, data science, big data
[Artists impression]](https://image.slidesharecdn.com/hipc-foster-december-2017-180116162417/75/Computing-Just-What-You-Need-Online-Data-Analysis-and-Reduction-at-Extreme-Scales-23-2048.jpg)





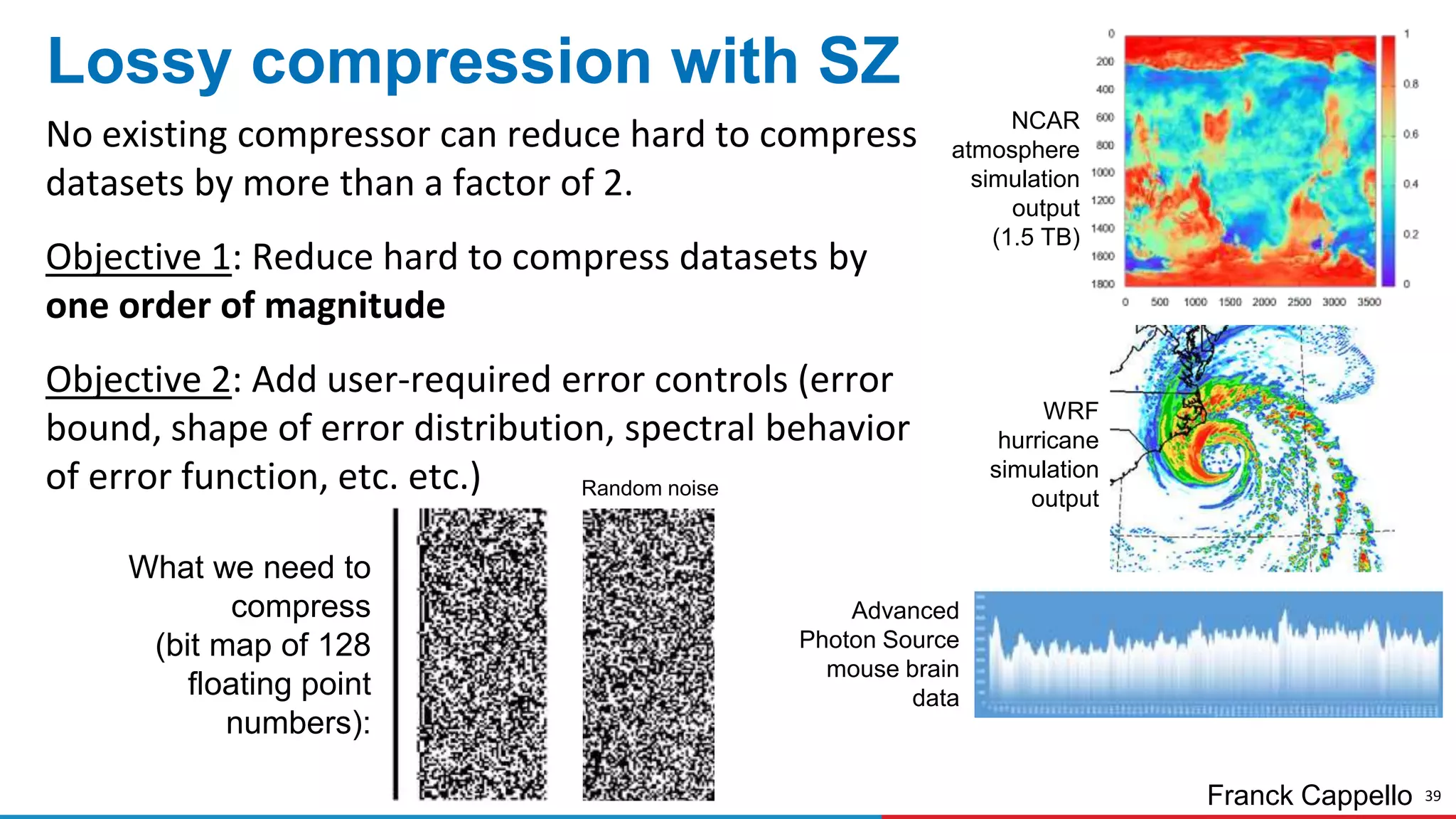
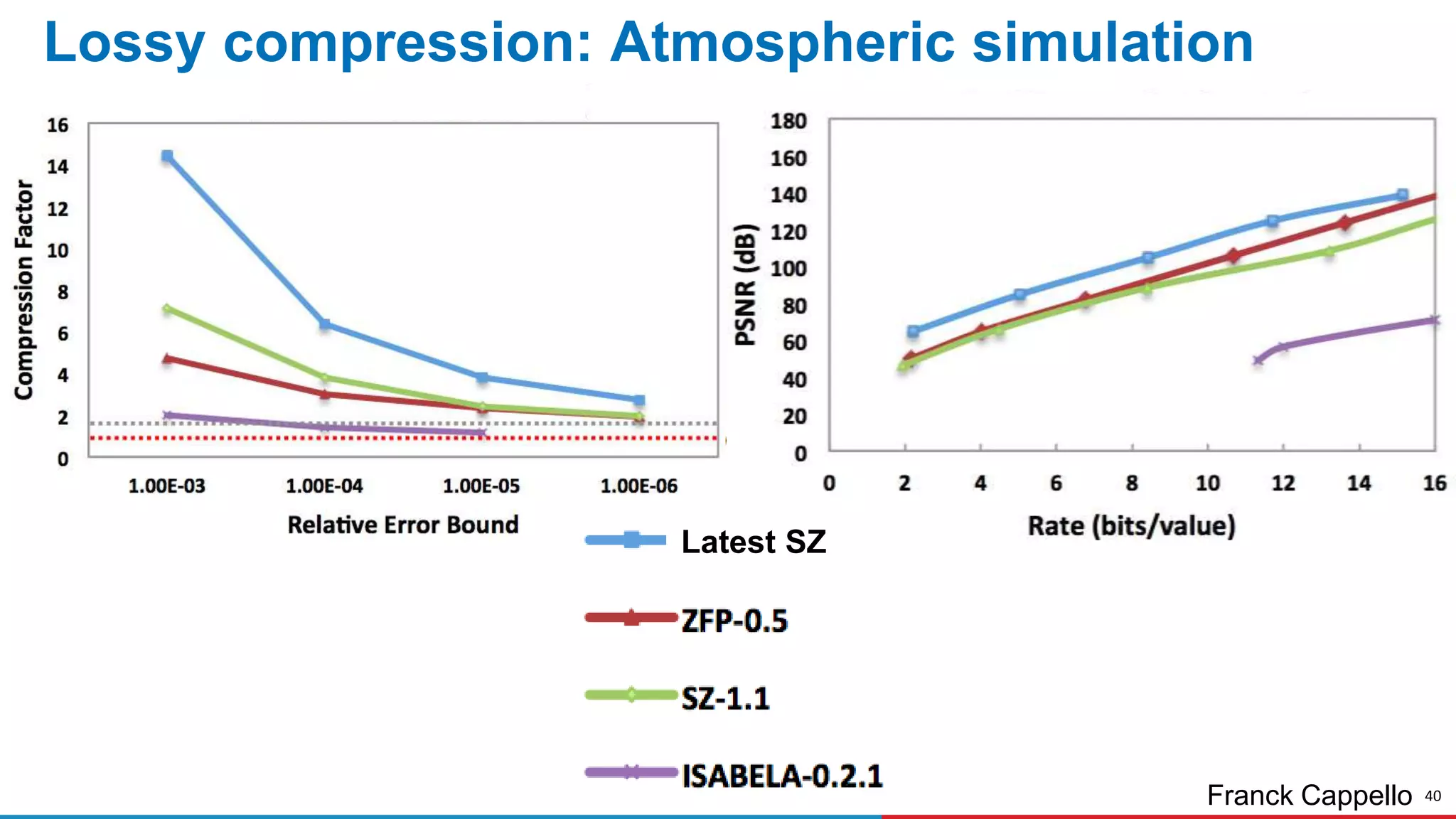
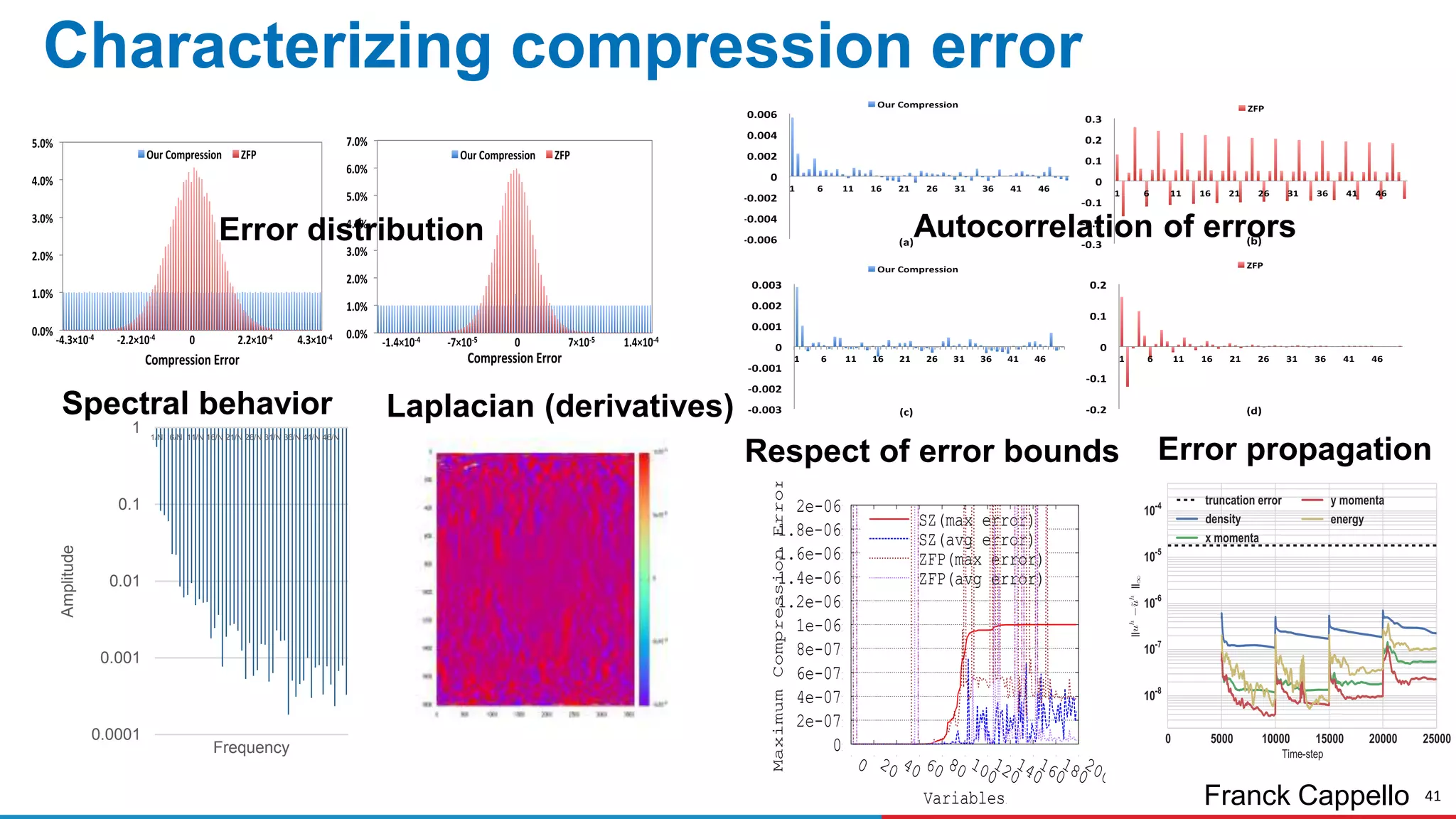
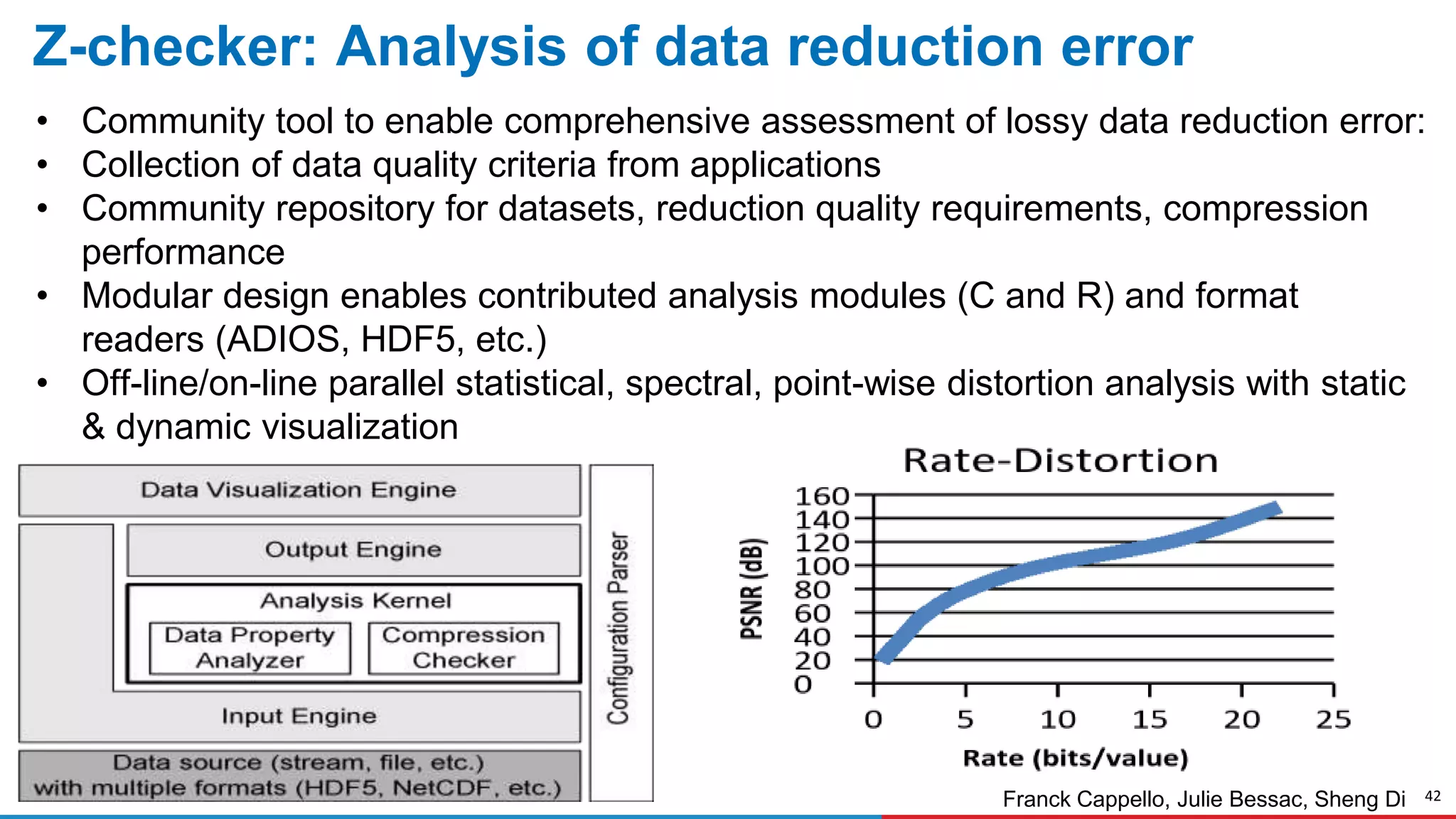


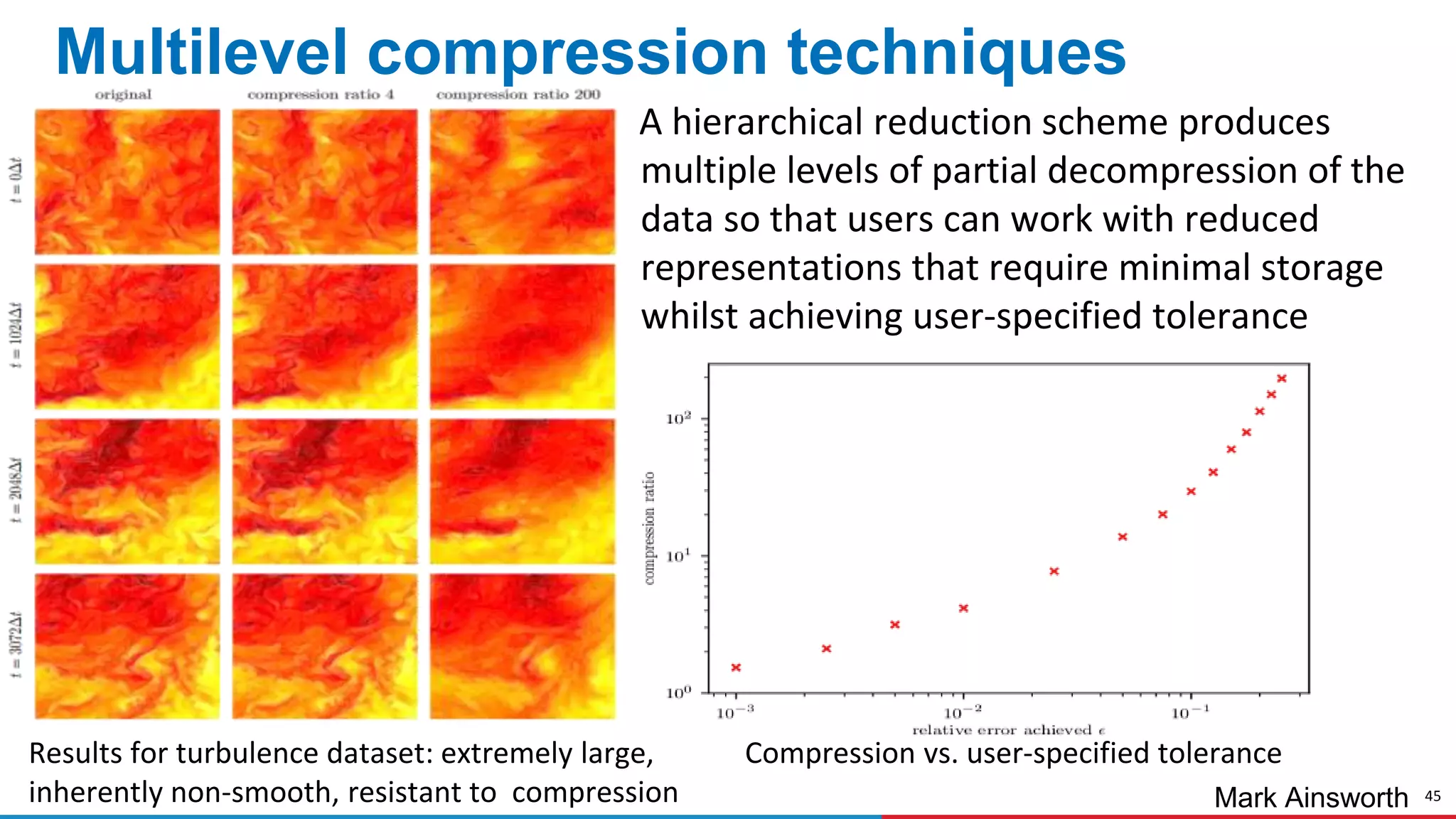
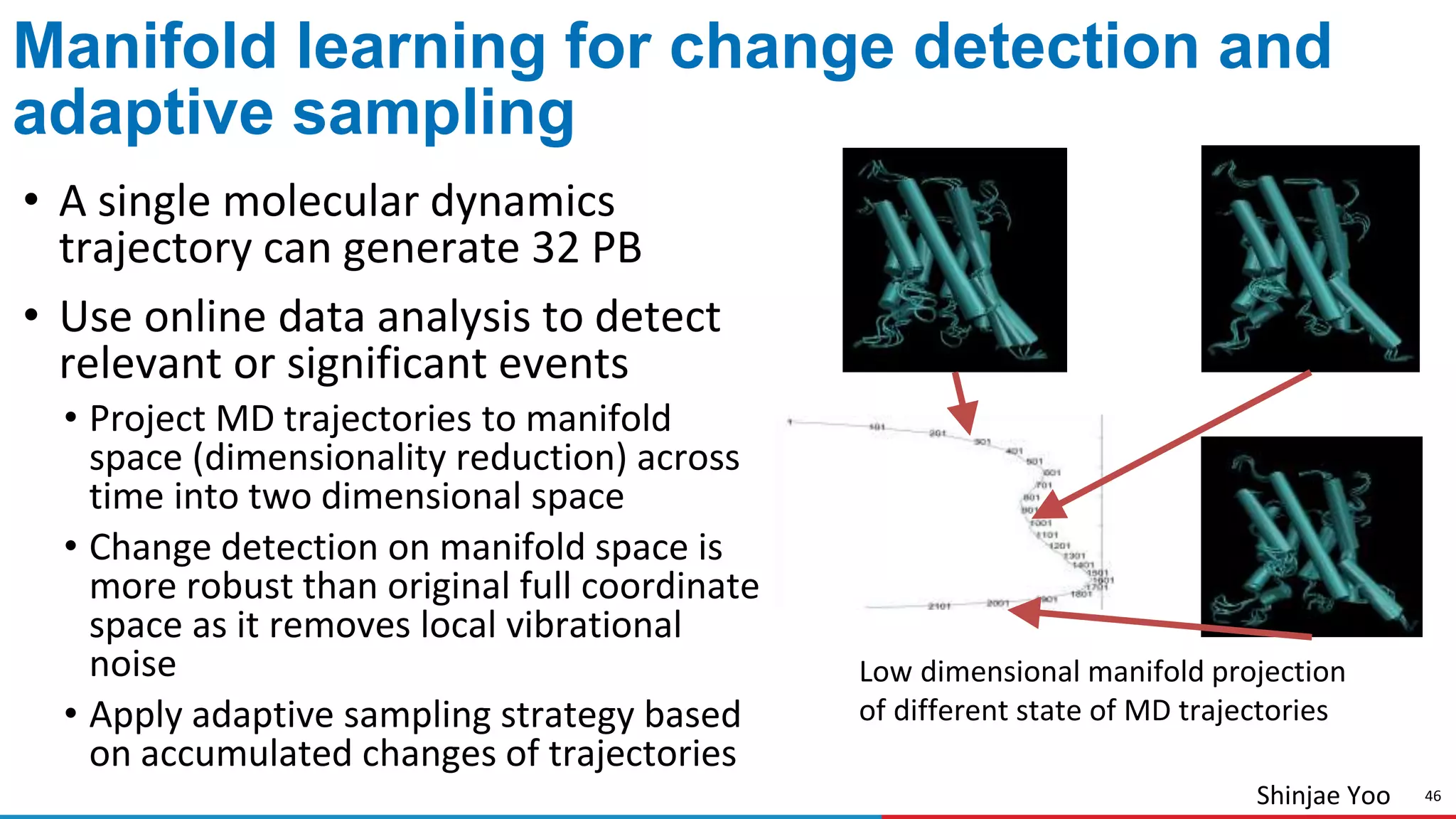
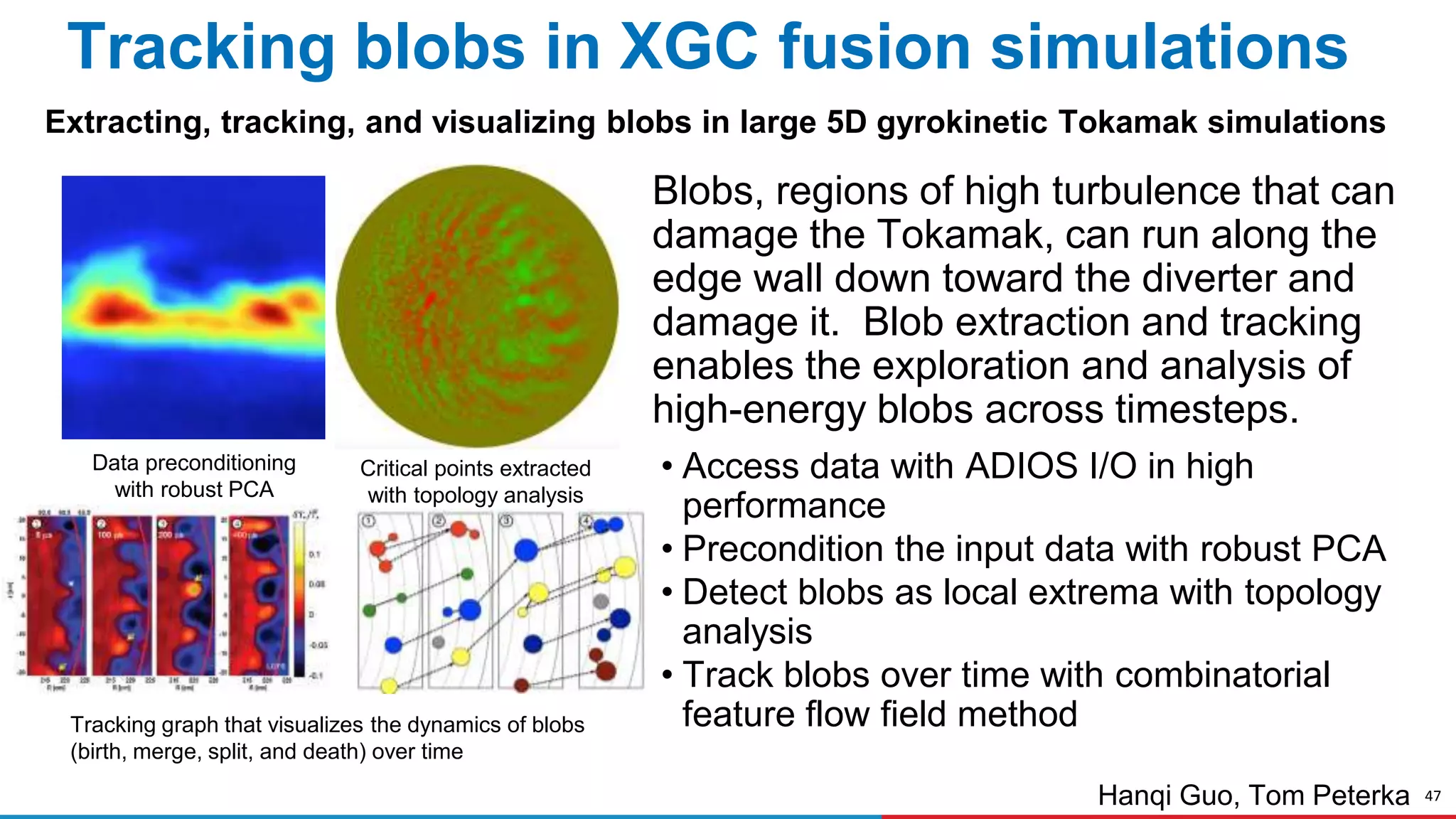

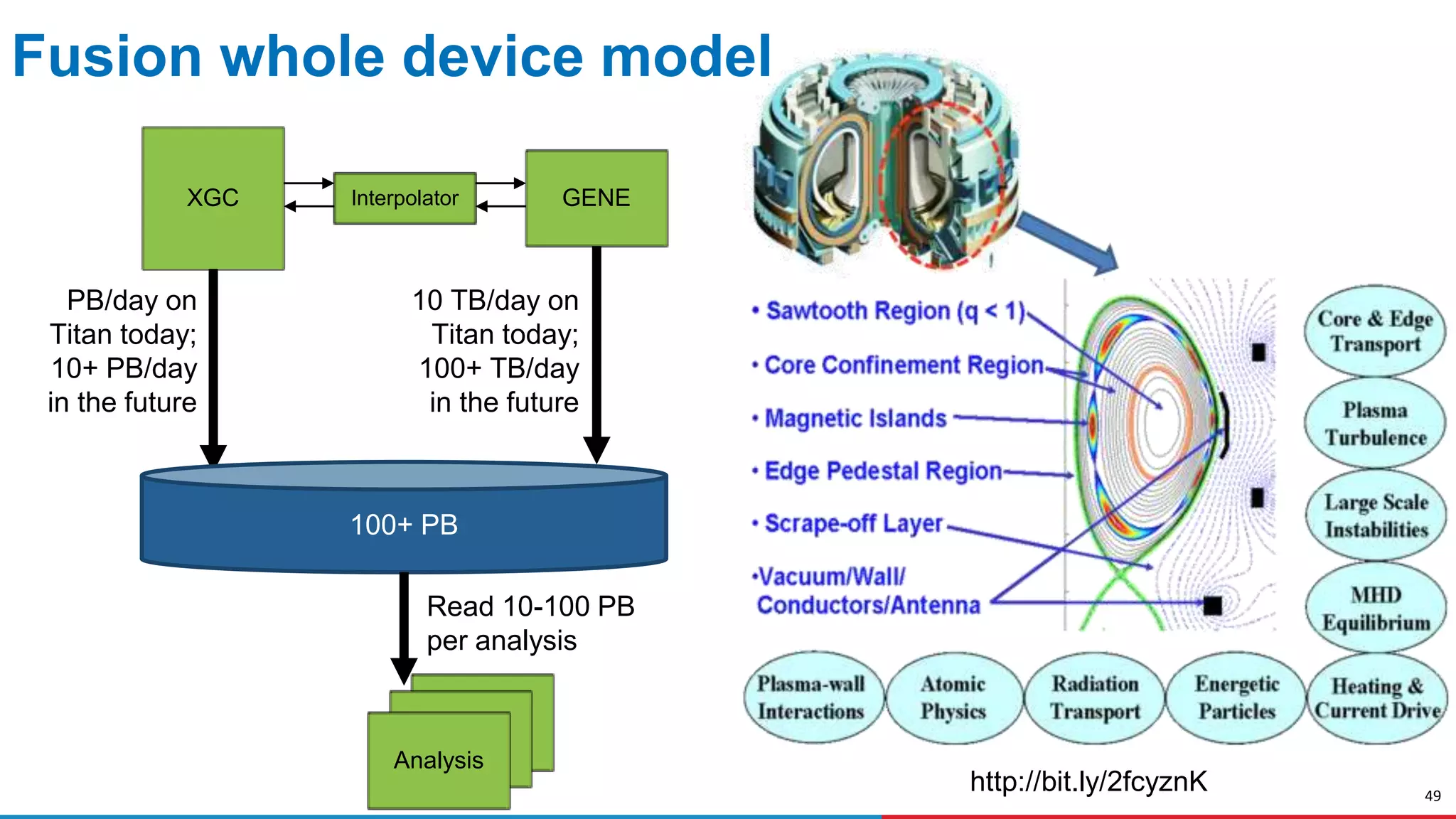
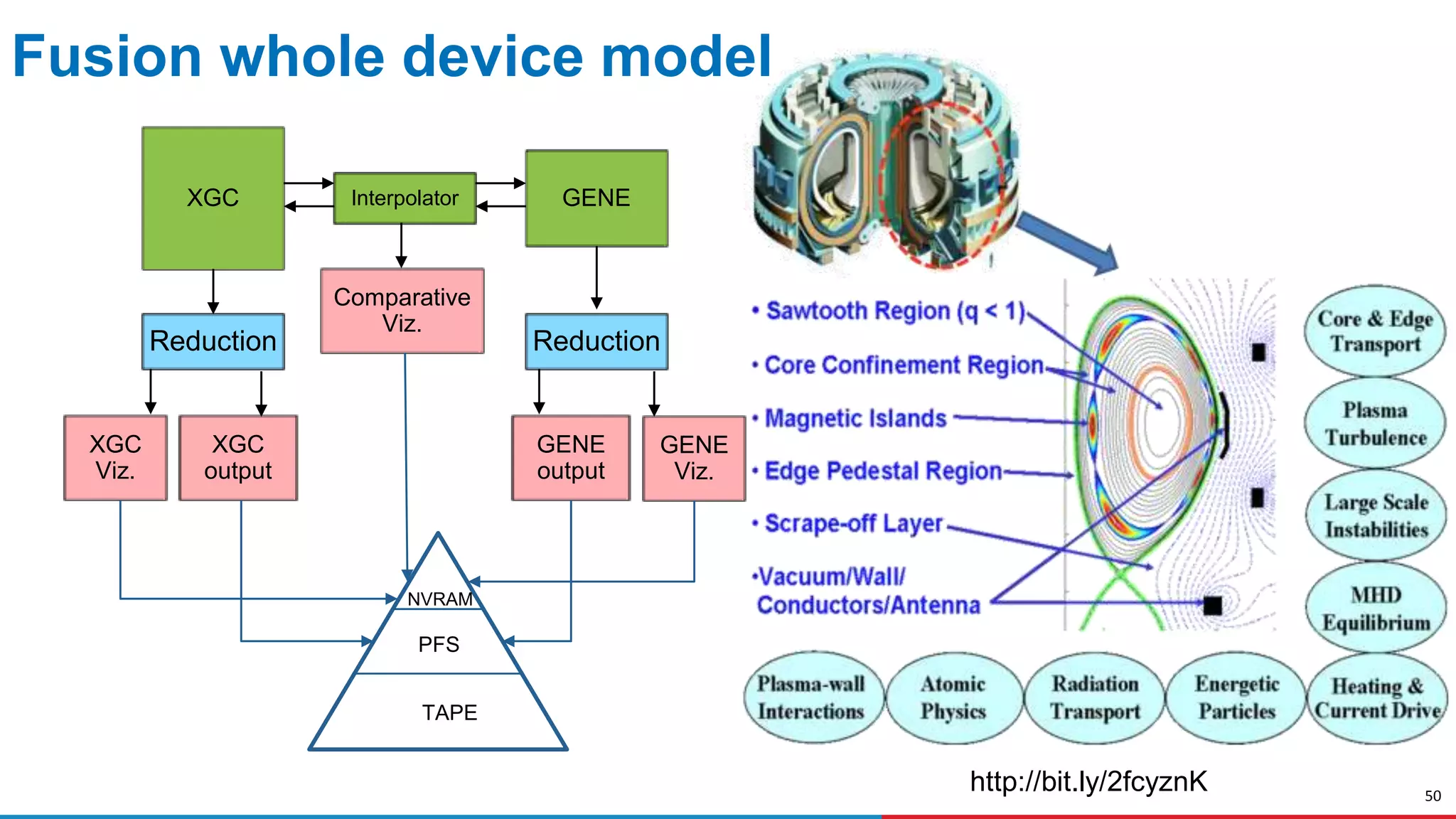
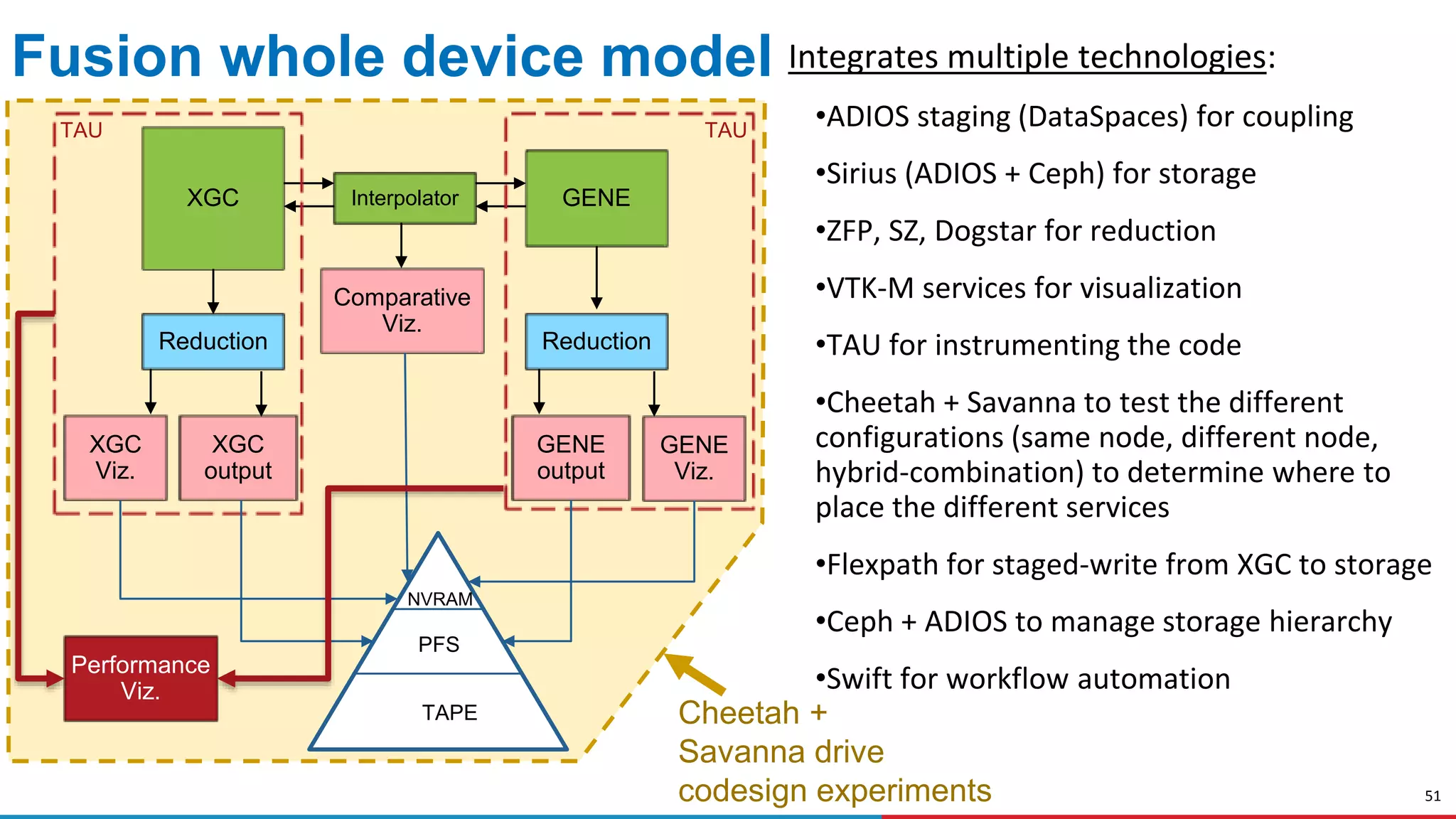

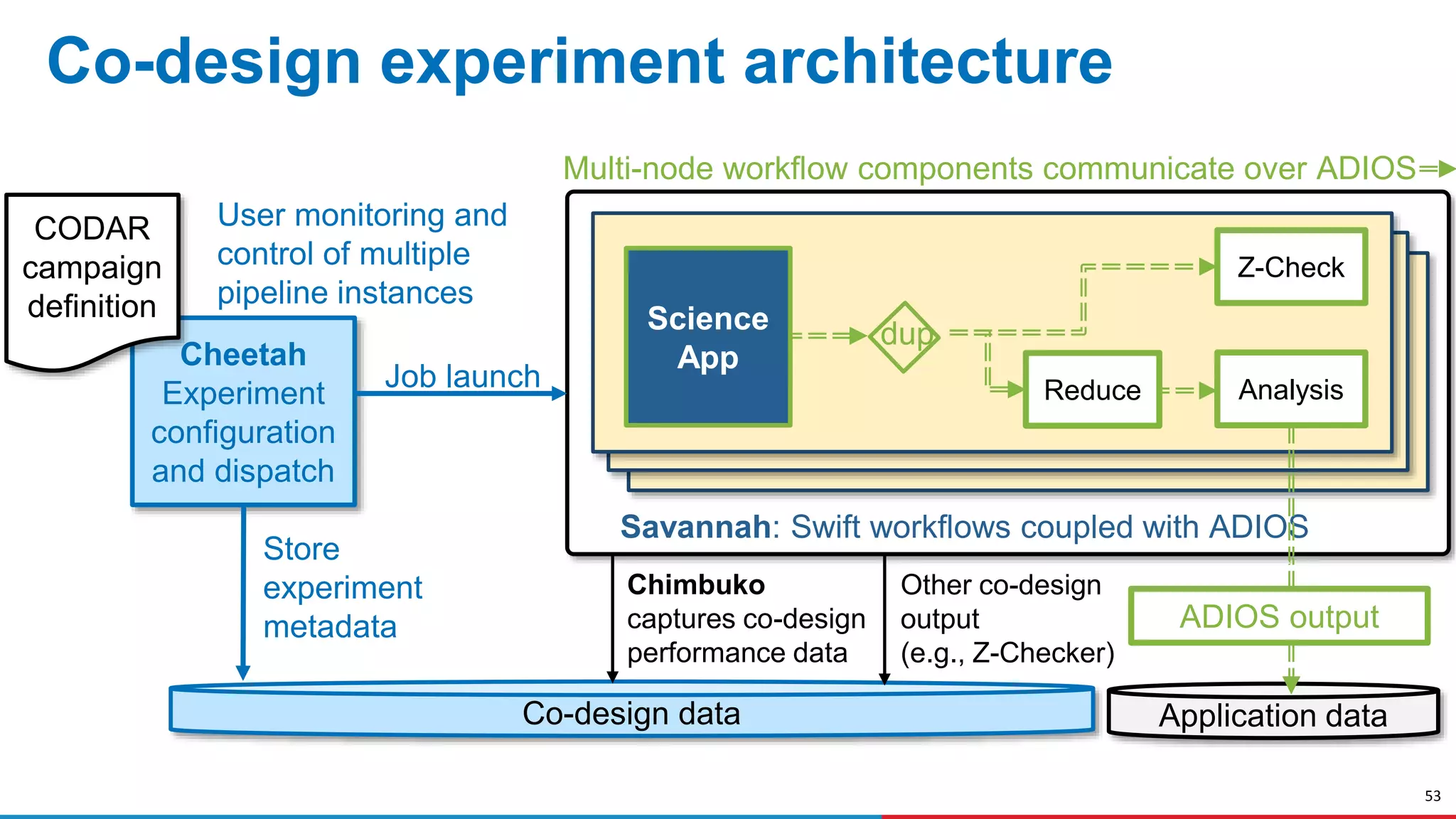
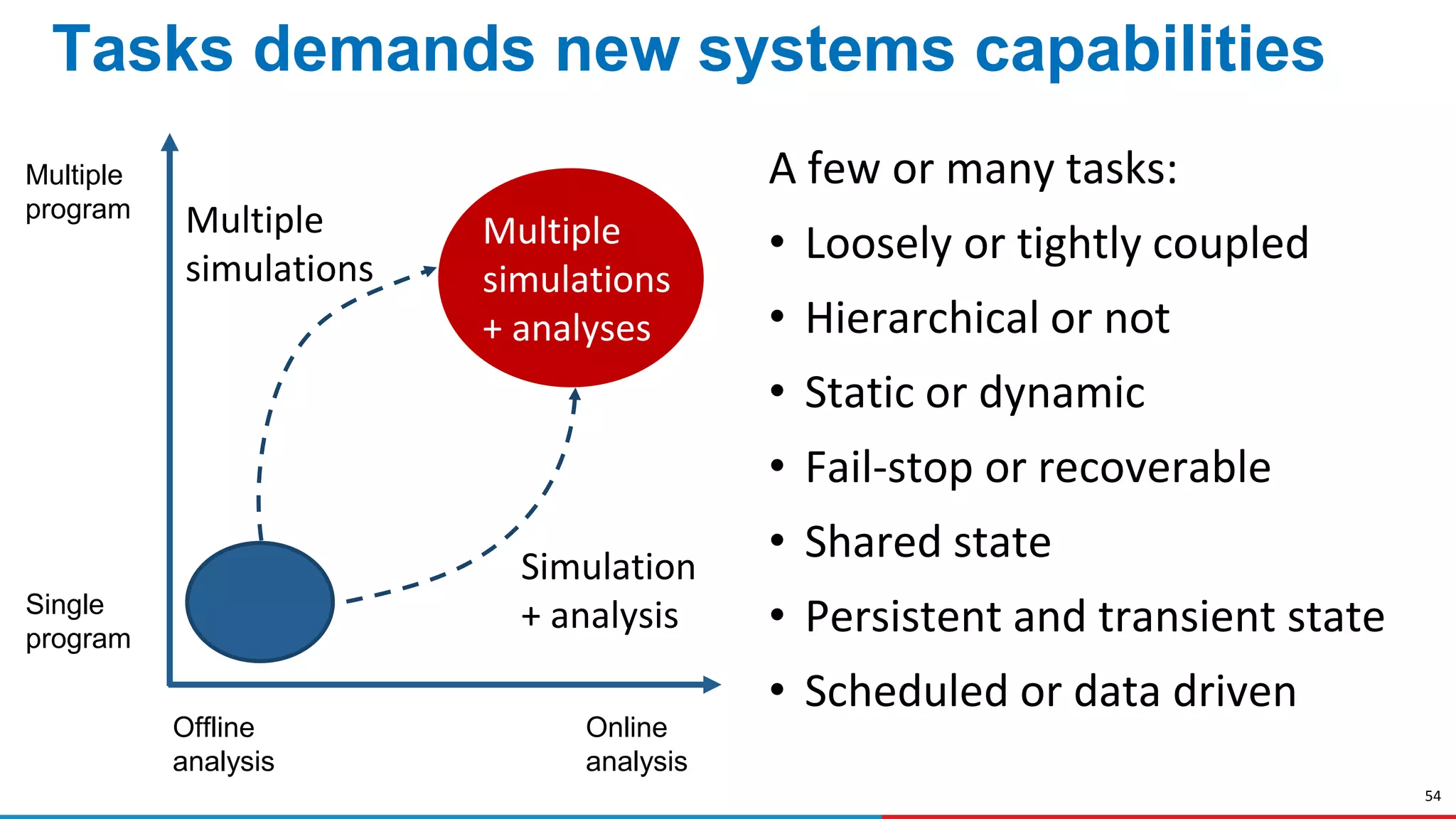



The document discusses advances in online data analysis and reduction for extreme scale computing, highlighting the integration of automation to enhance the research data lifecycle. Emphasizing the importance of real-time analysis, it outlines the challenges faced in handling large datasets and proposes a co-optimized approach that integrates simulation, analysis, and data reduction. It also introduces the Codar initiative, which aims to develop infrastructure for effective online data services and addresses key research questions related to data management and error impact.























































































