Downloaded 72 times









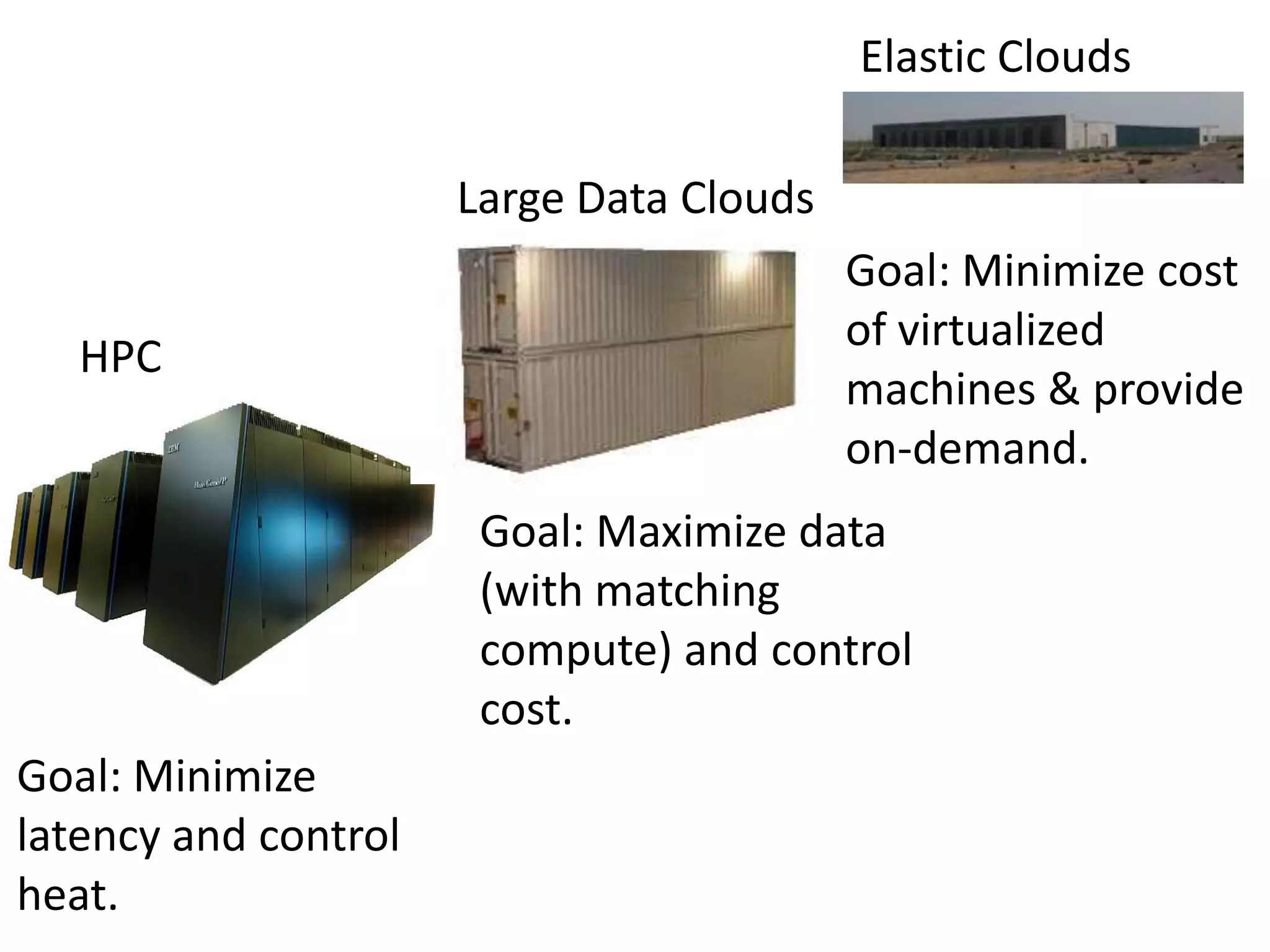
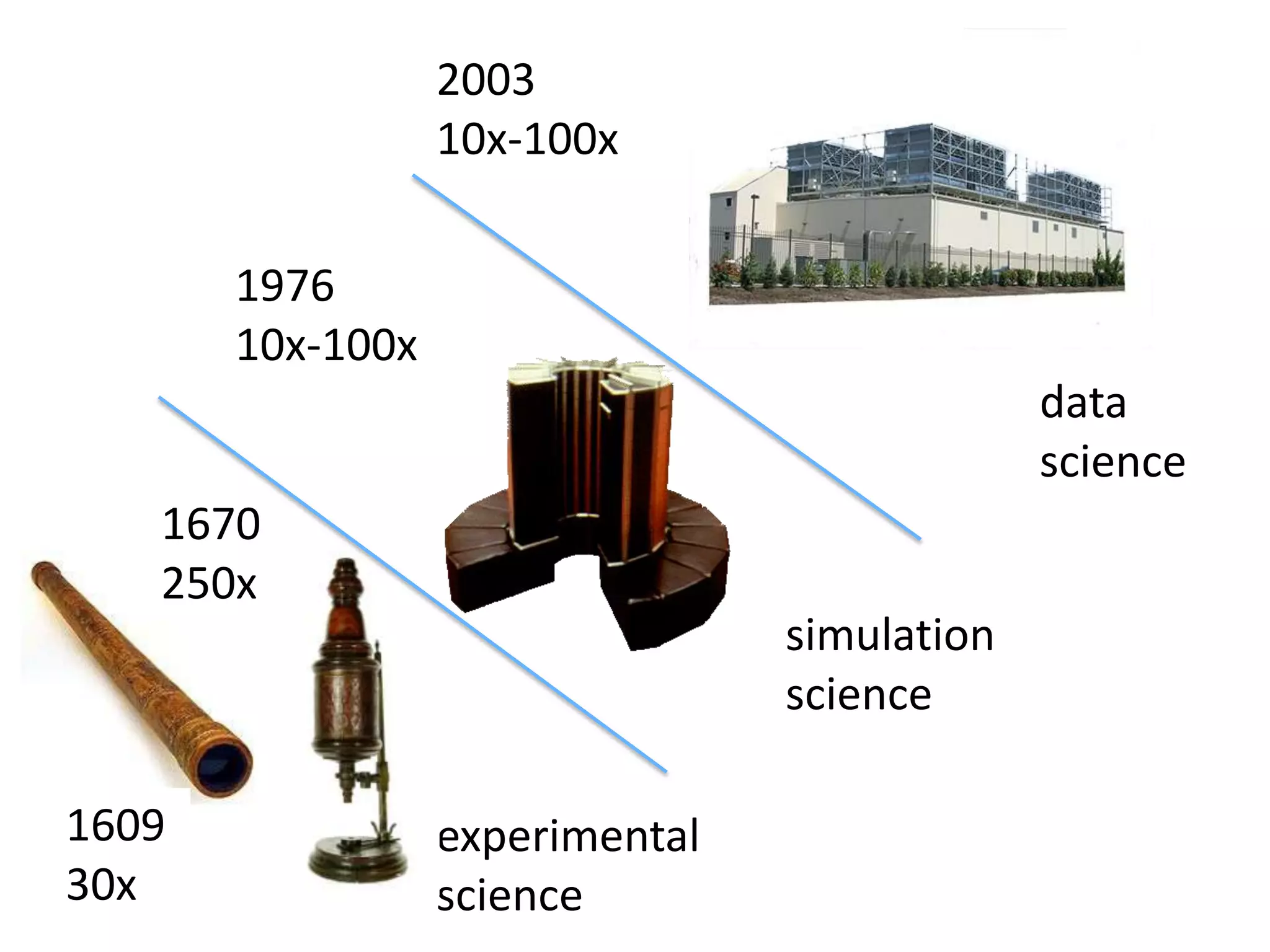
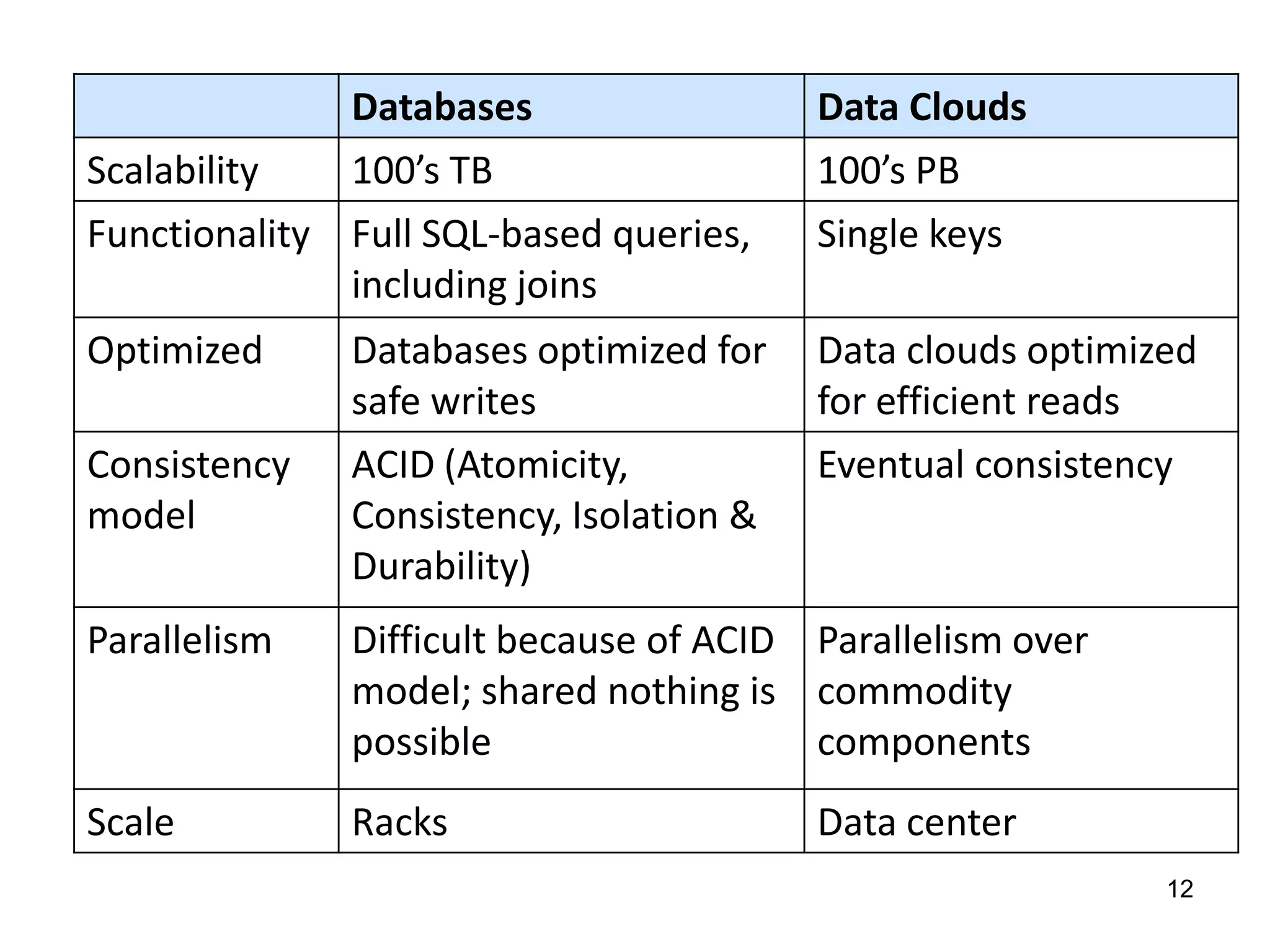
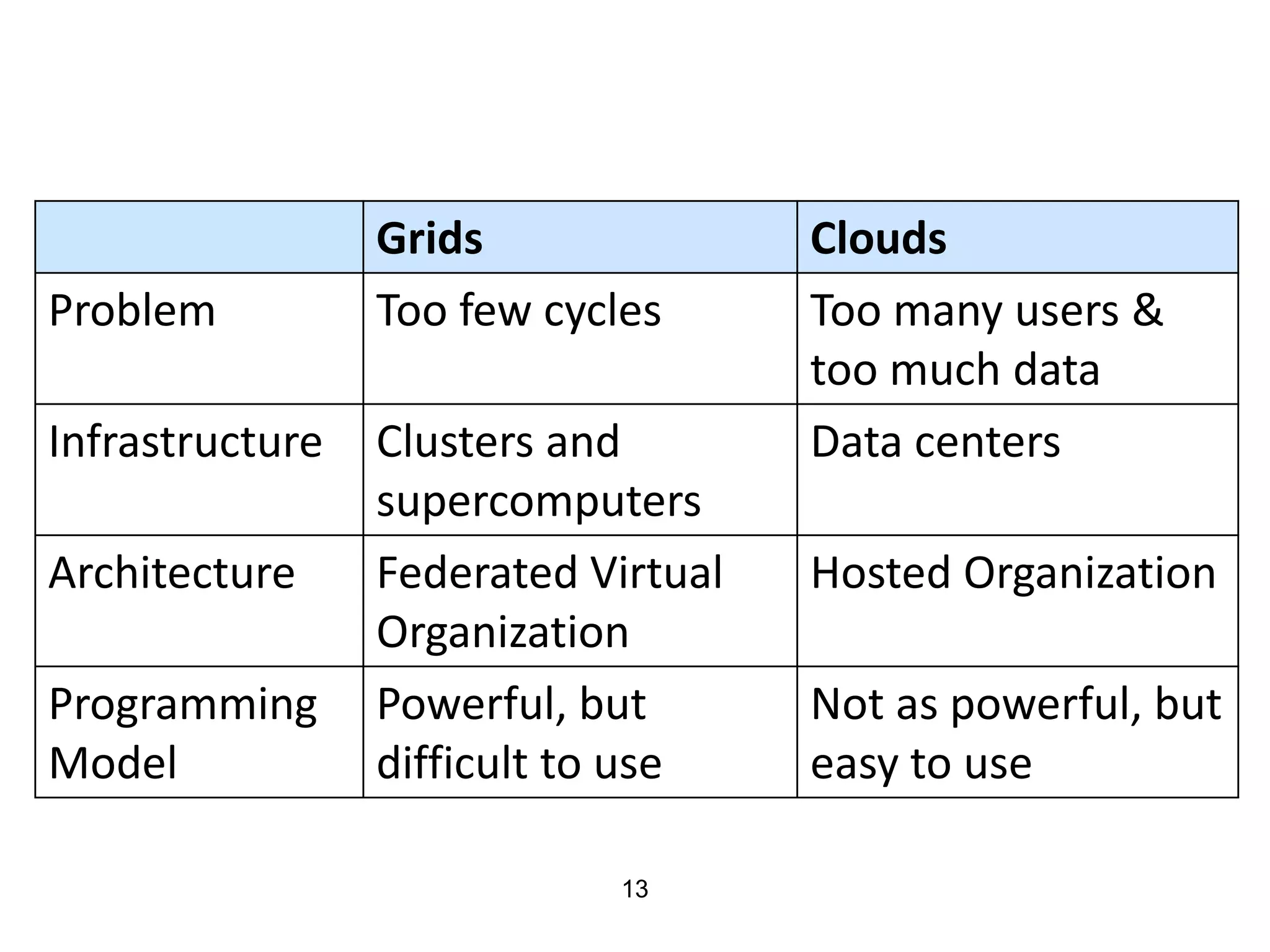




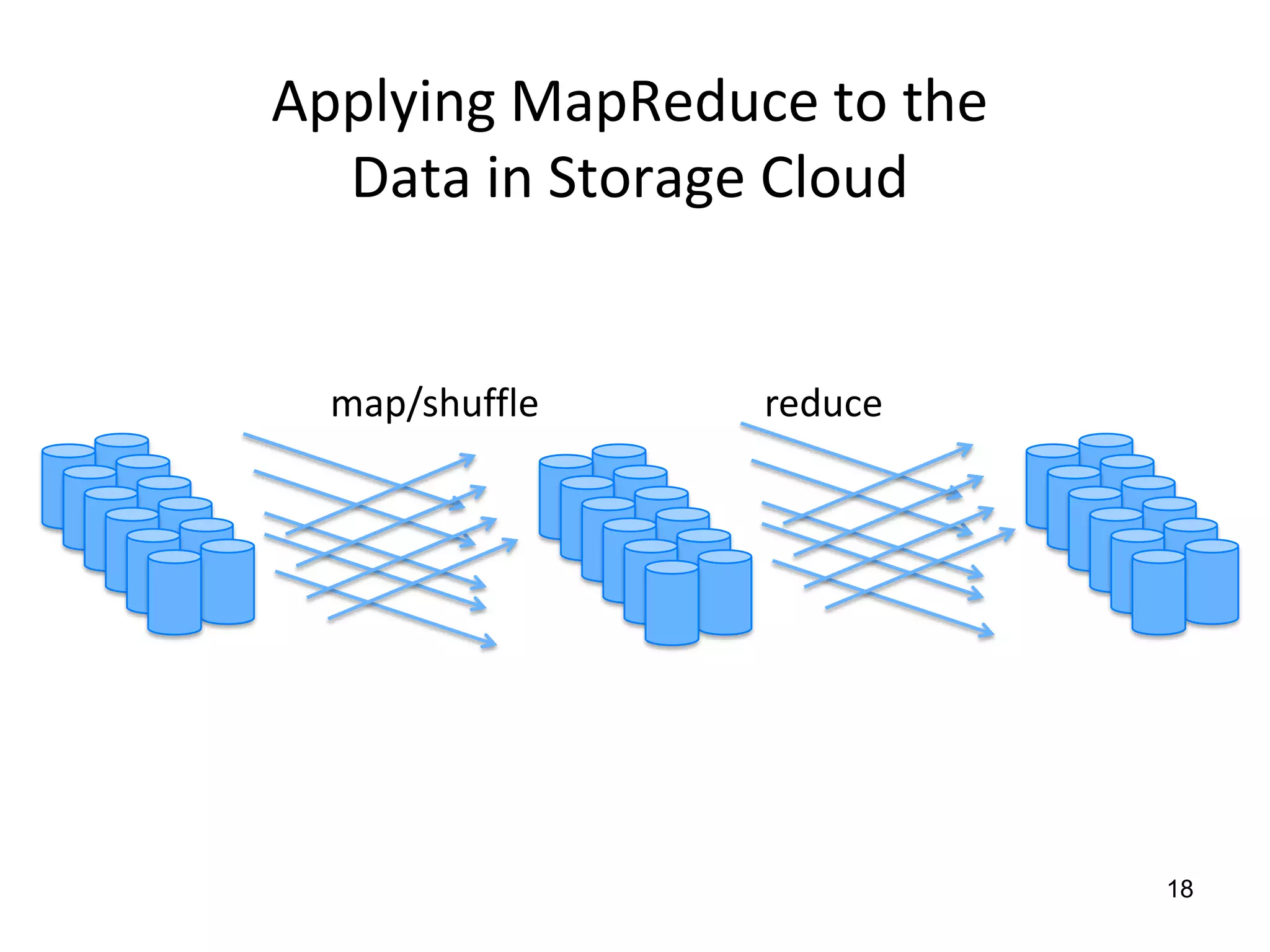
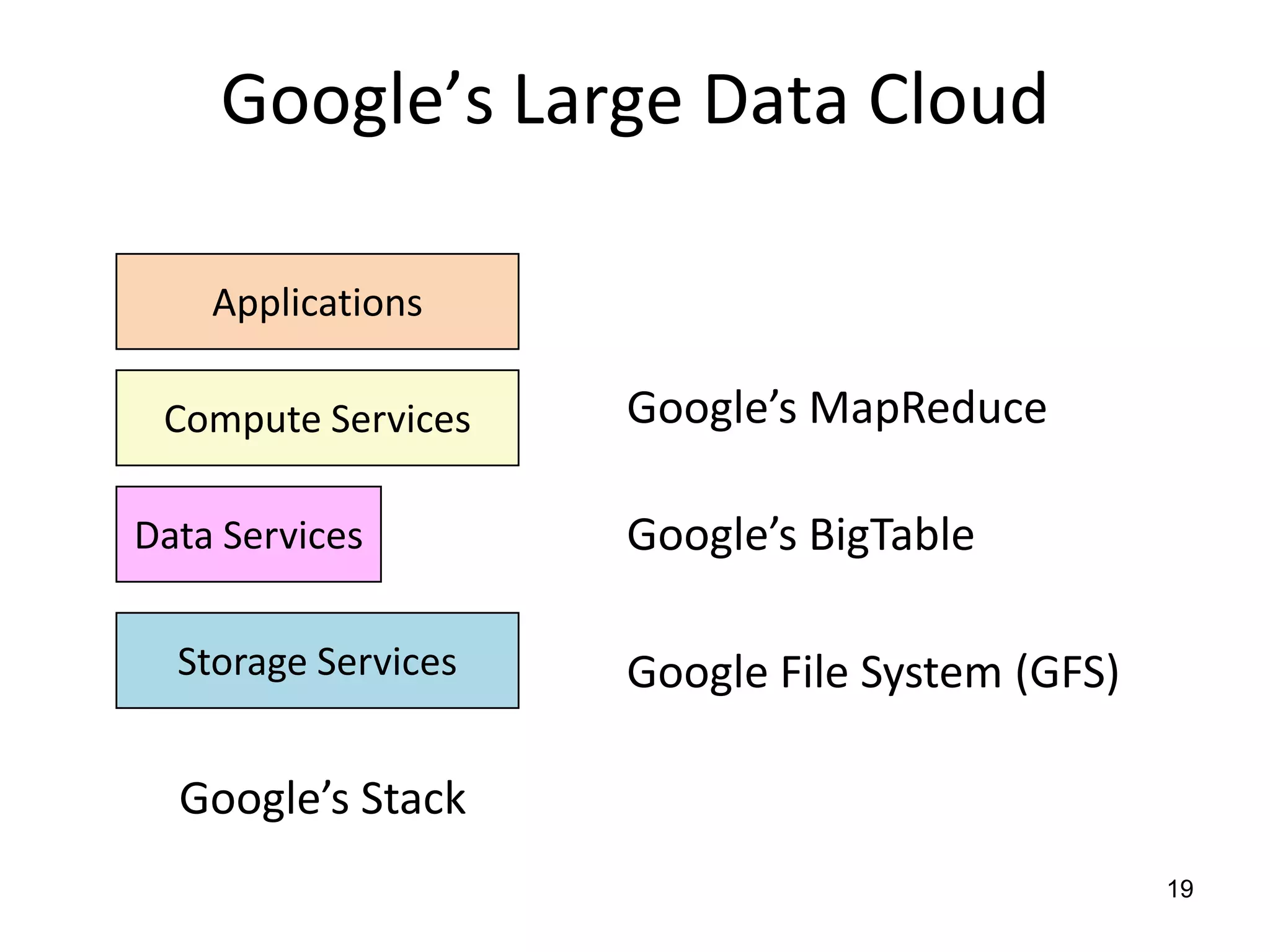
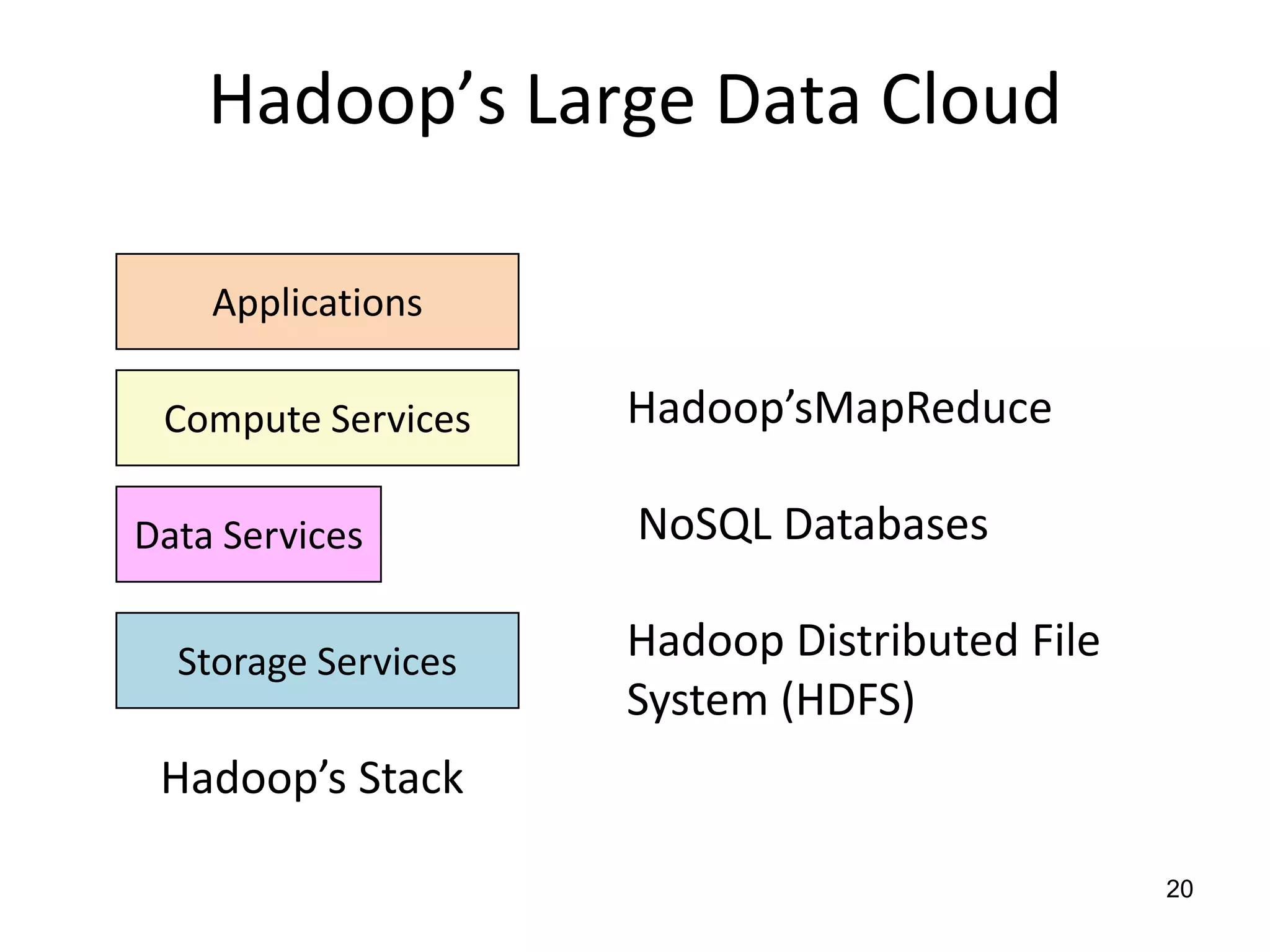
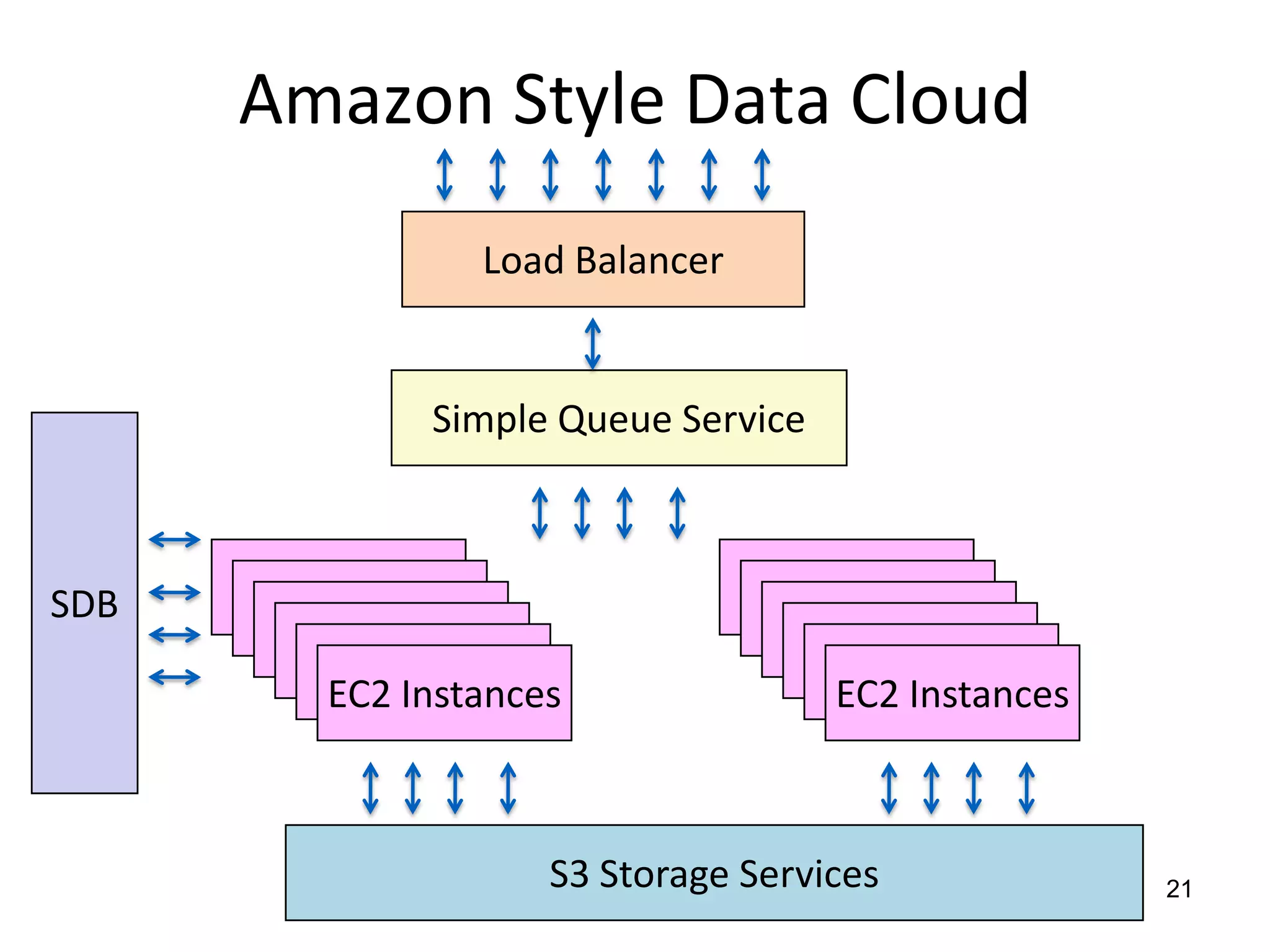








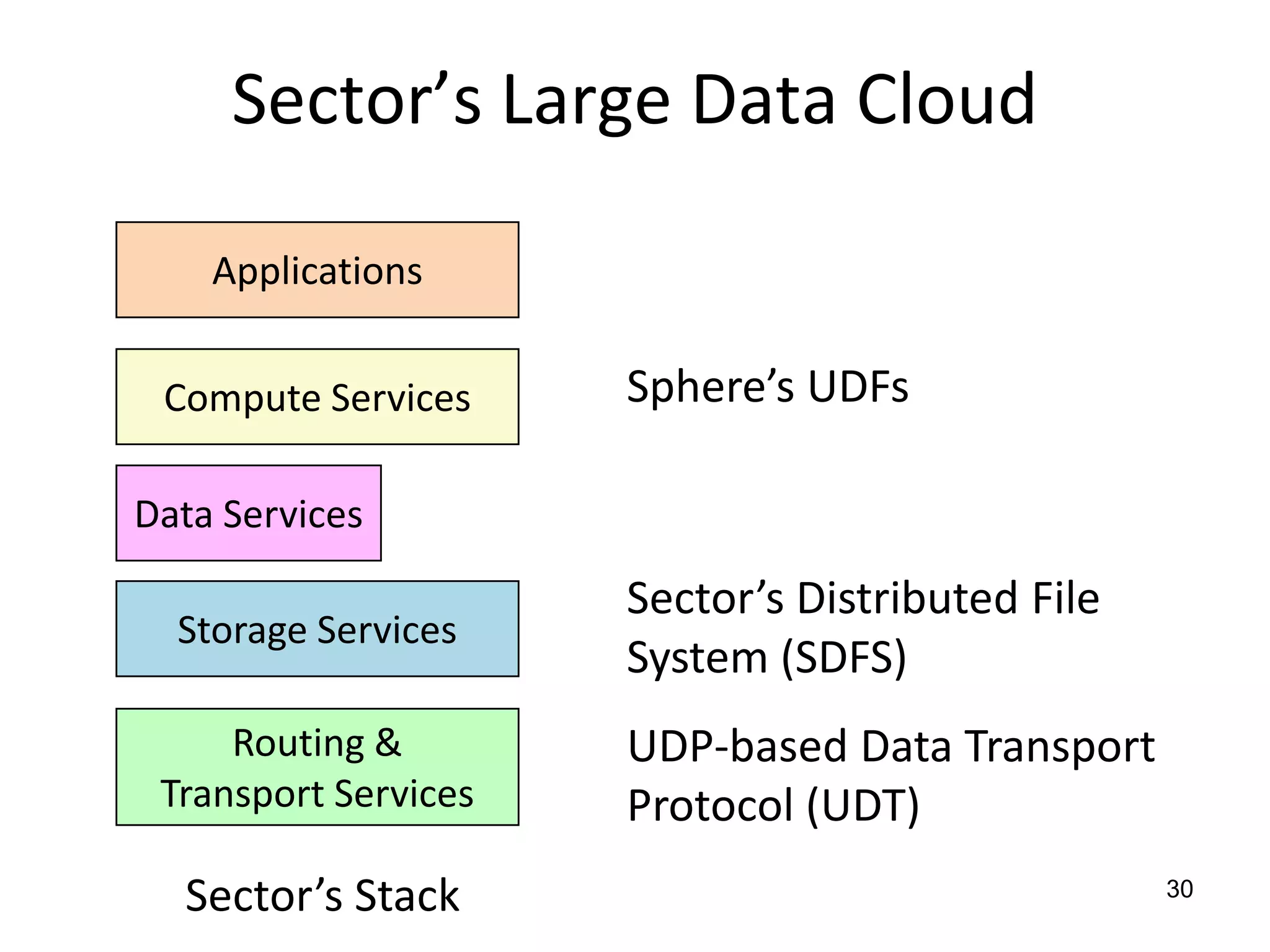
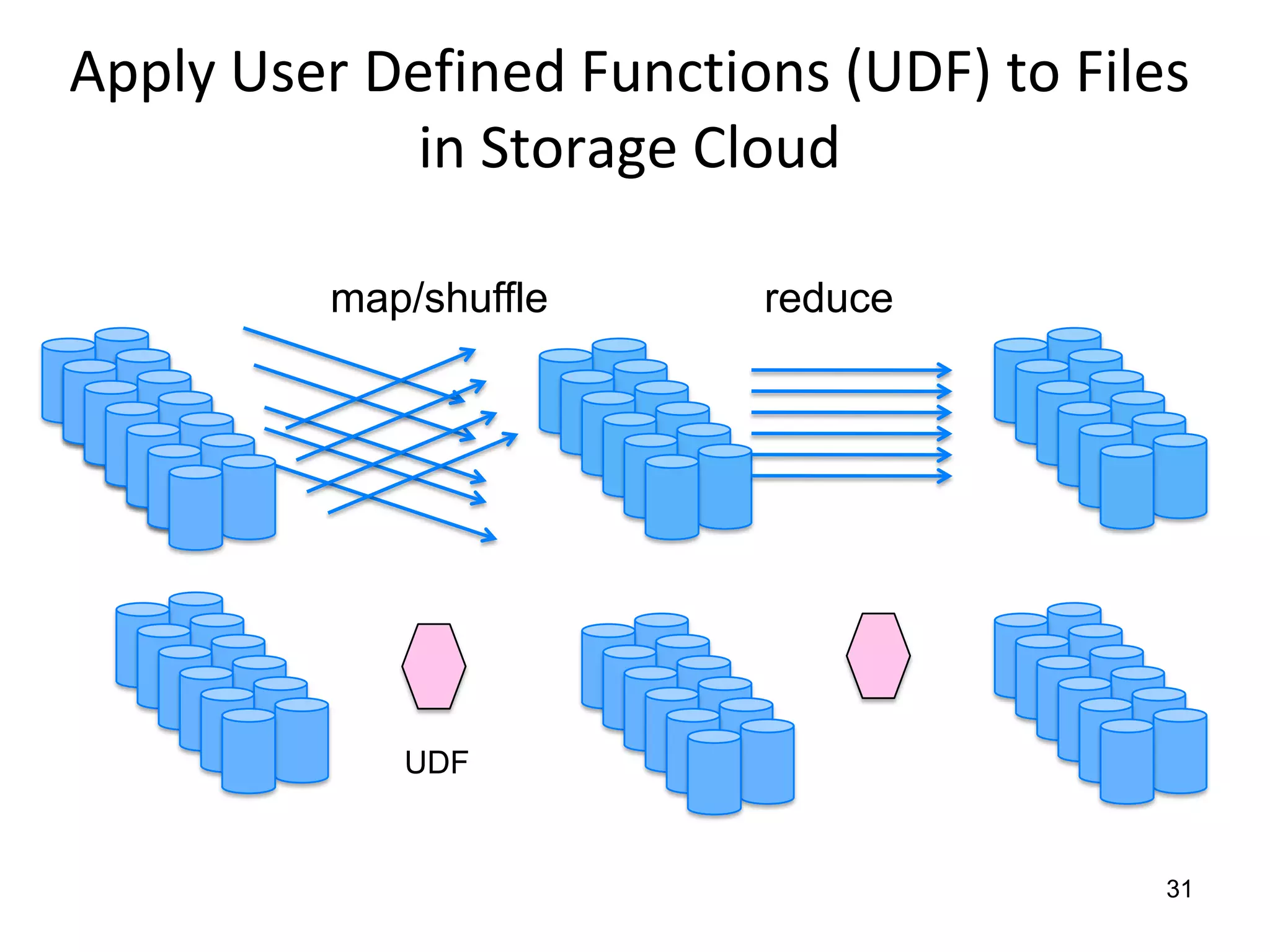
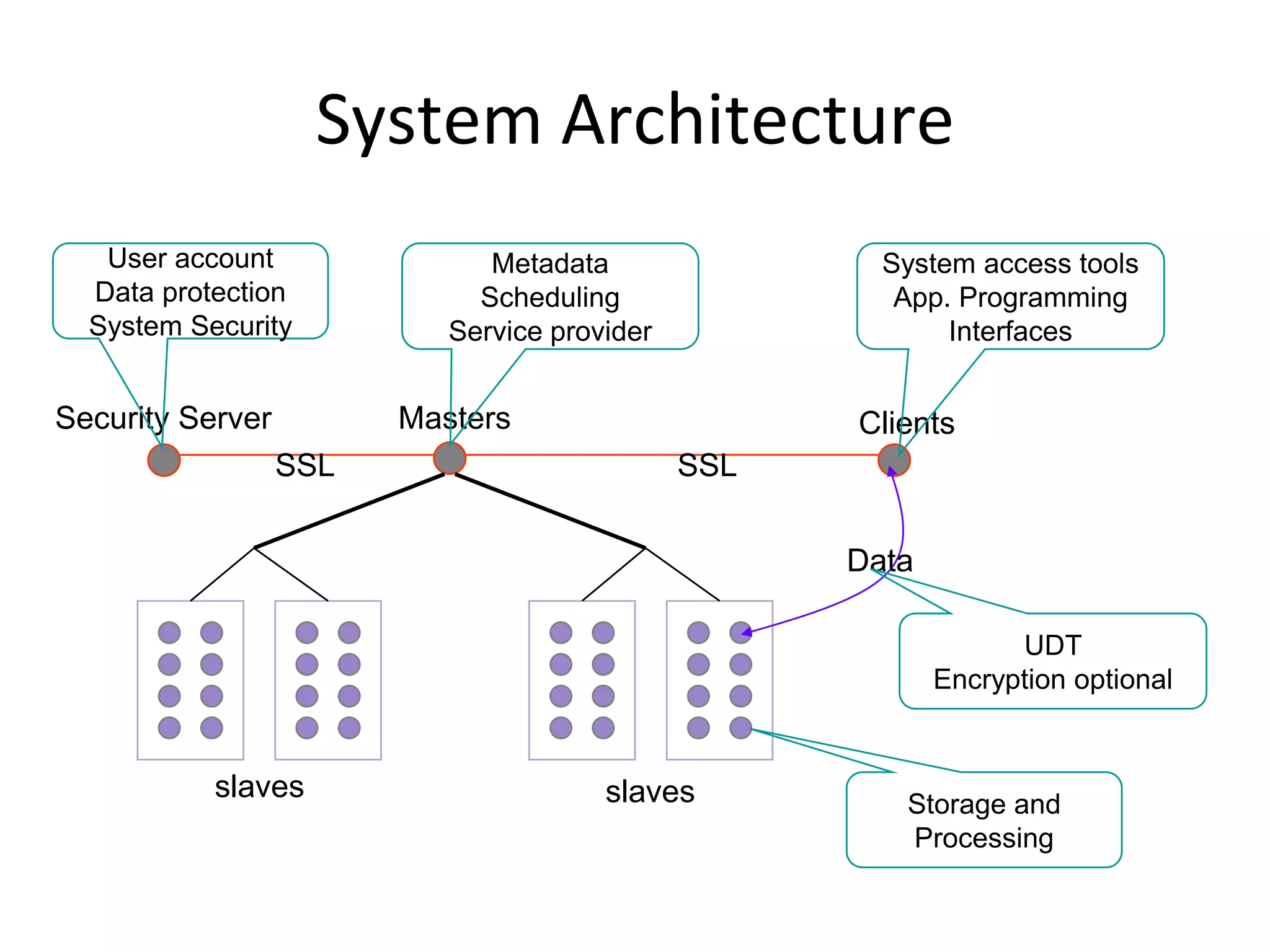
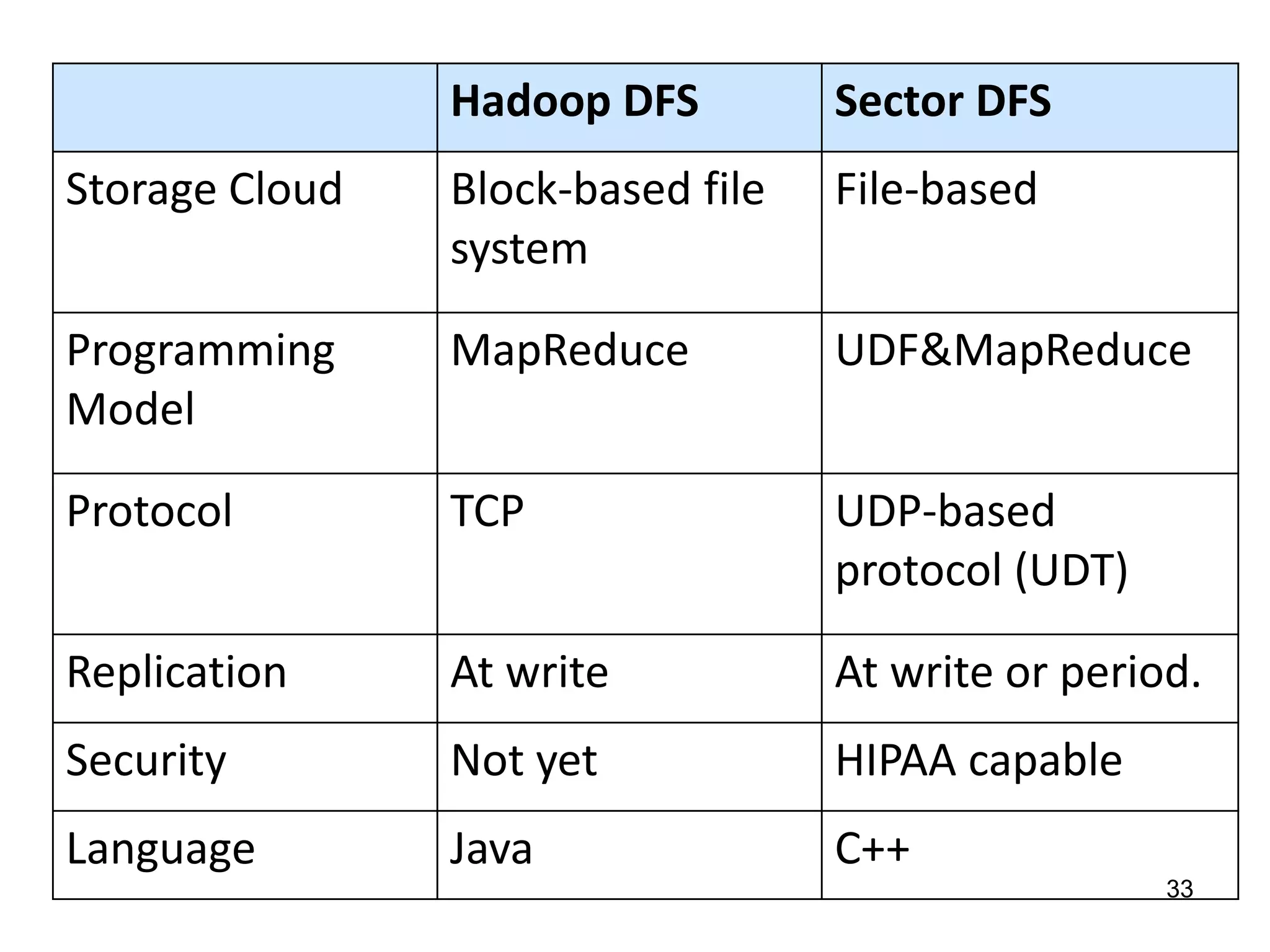
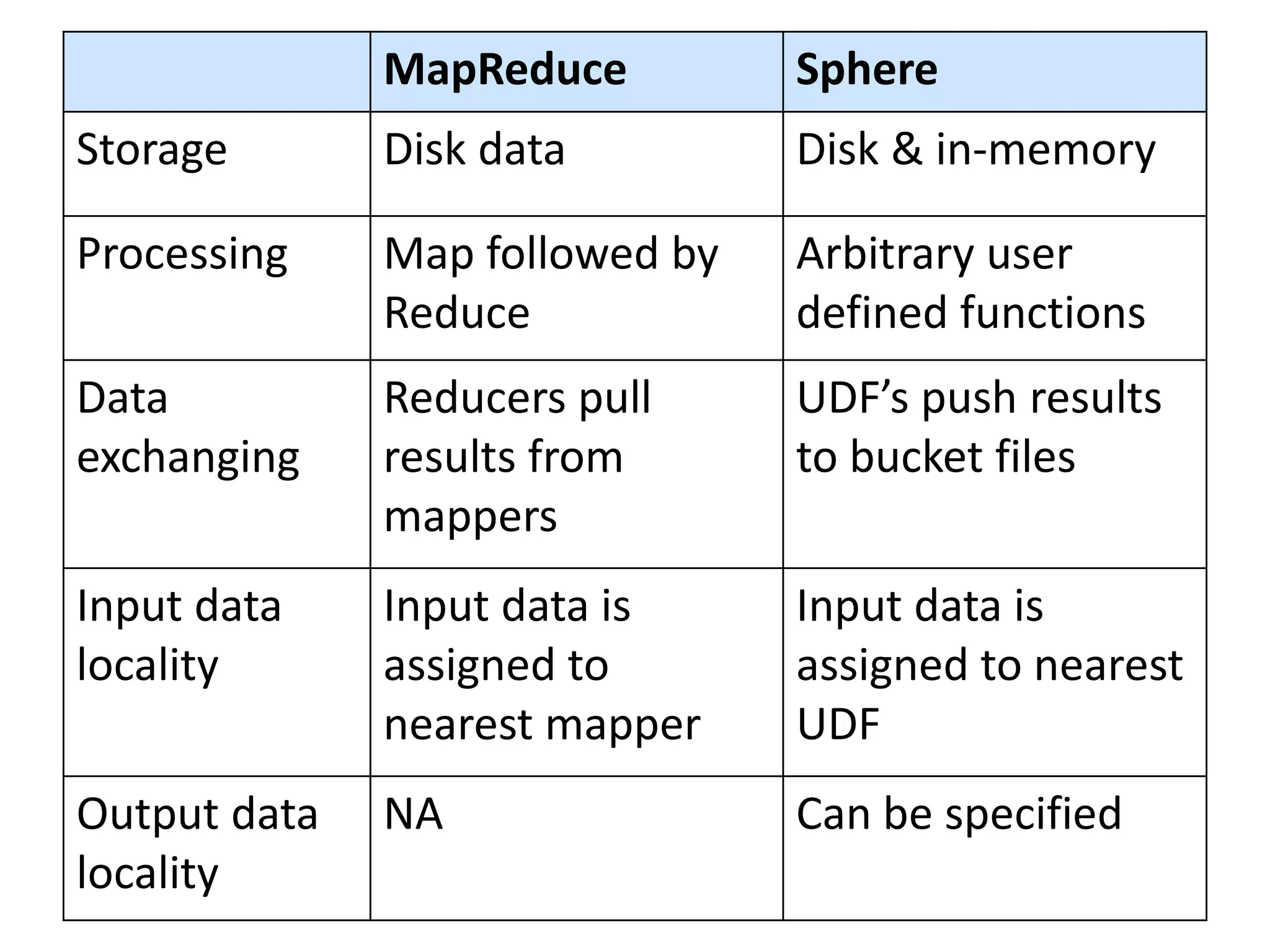
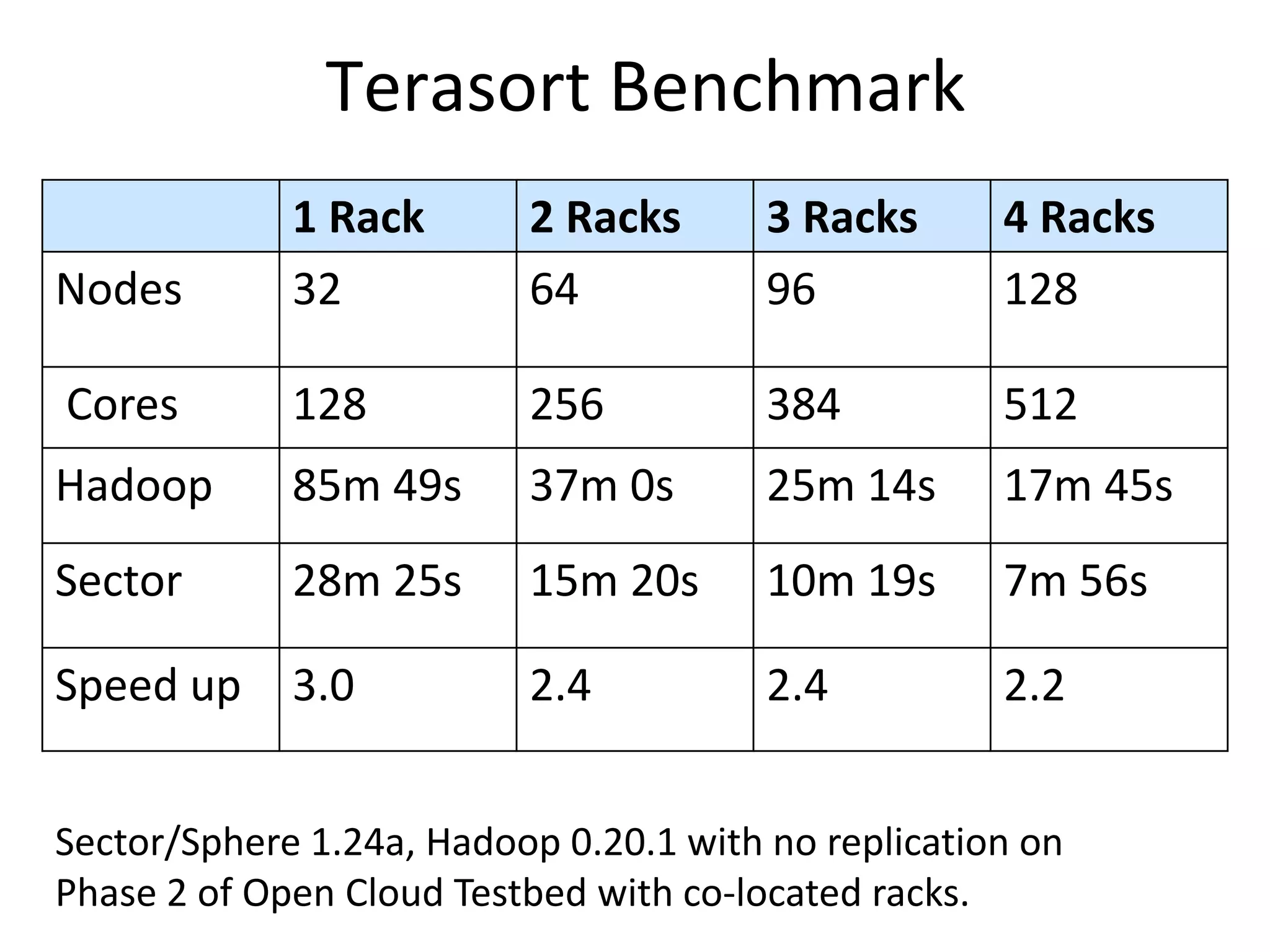
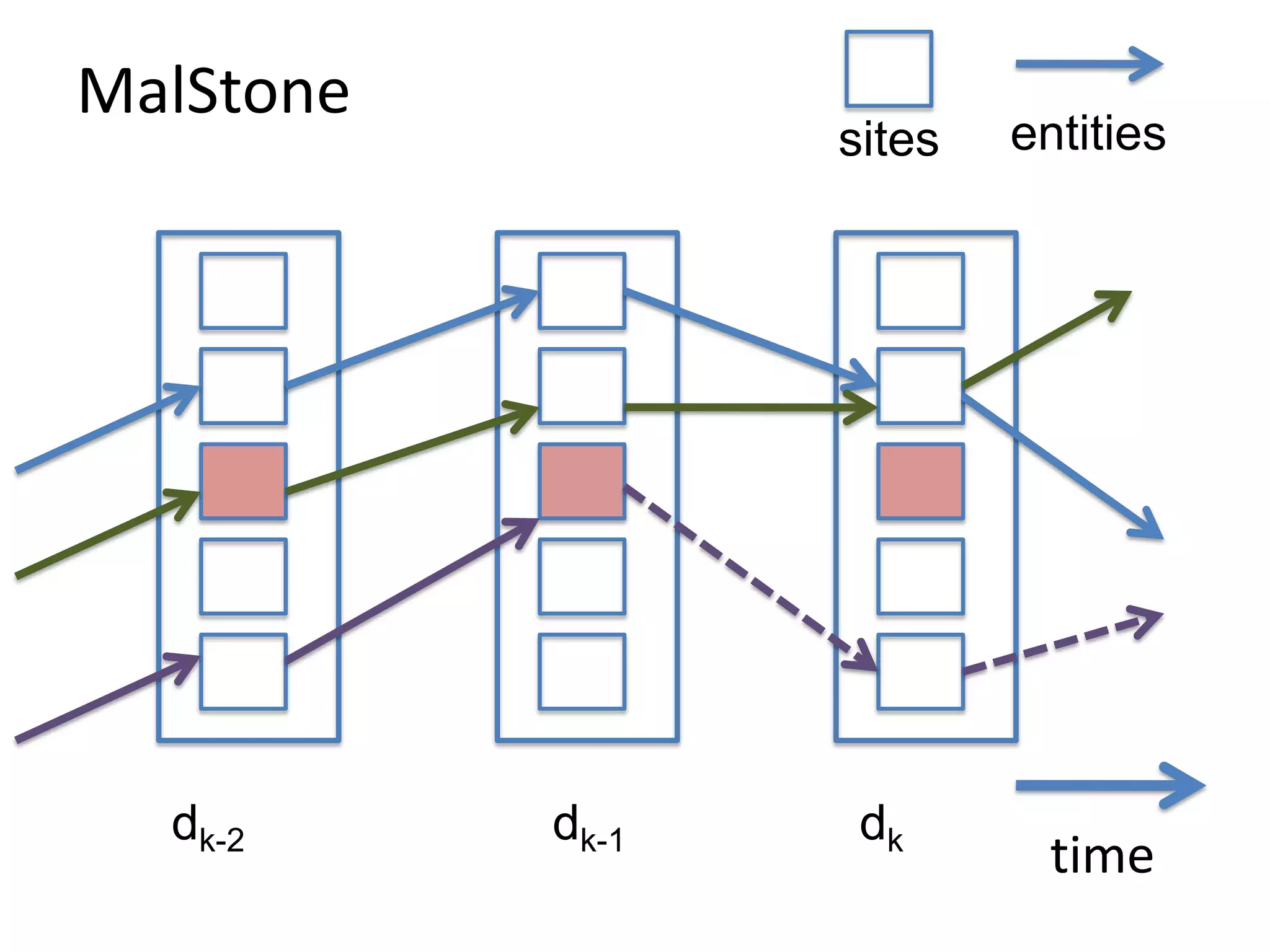
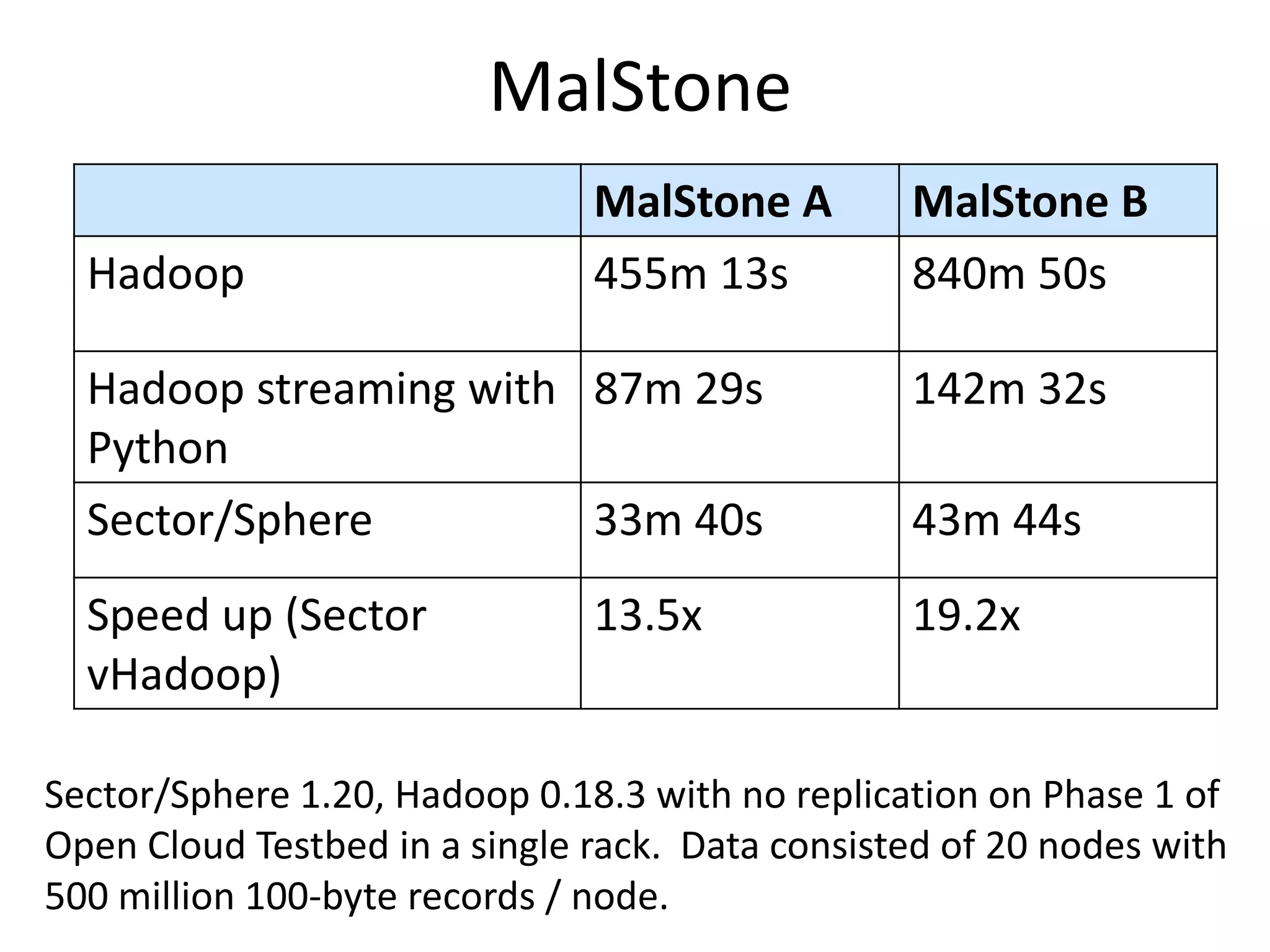
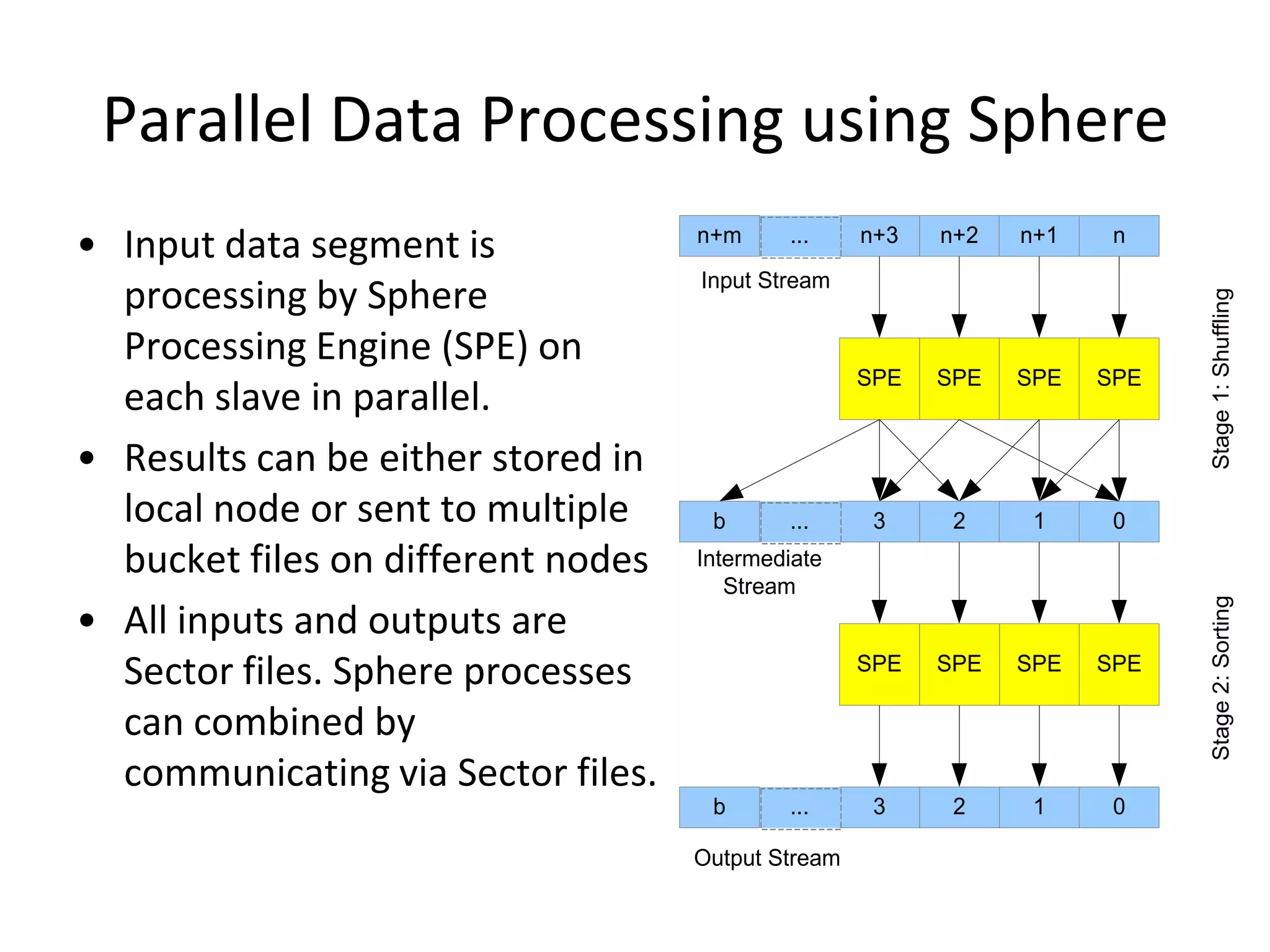
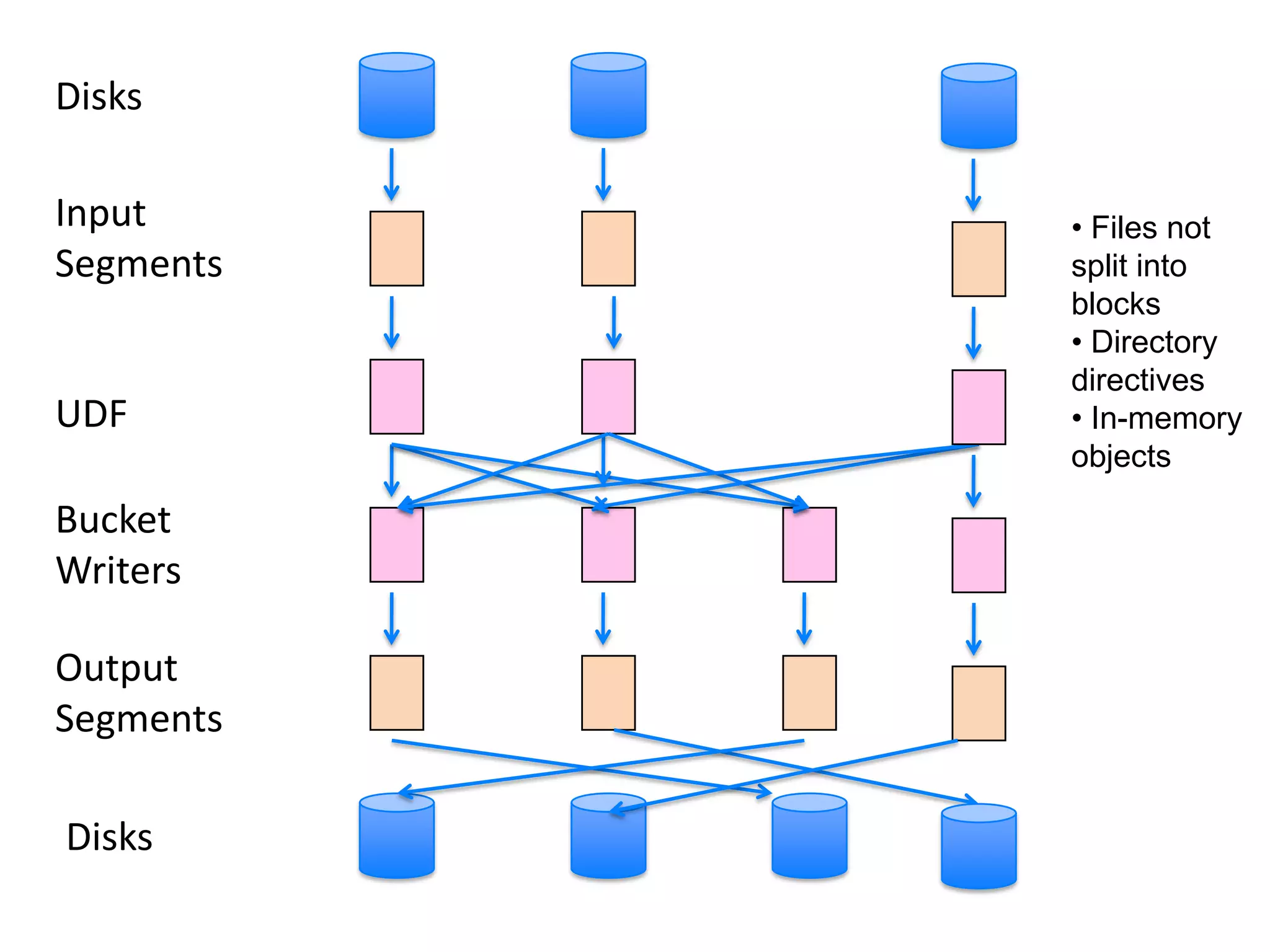










The document discusses the distinctions between small and large data, emphasizing the scale and computational resources of data center computing. It provides insights into big data frameworks like Google's MapReduce, Bigtable, and various NoSQL systems, while introducing the Sector architecture for simplifying data-intensive computing. Additionally, it highlights several applications of the Sector platform for handling large datasets in fields such as astronomy and genomics.























































































