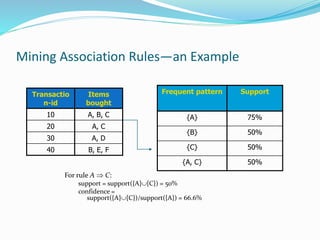
This document discusses association rule mining and frequent pattern mining. It defines association rule mining as finding frequent patterns, associations, correlations, or causal structures among items in transactional databases. An example is provided to illustrate support and confidence for an association rule. Several algorithms are summarized for scalably mining association rules from large transactional databases, including Apriori, Partition, sampling, and FP-growth. FP-growth avoids candidate generation by building an FP-tree structure.