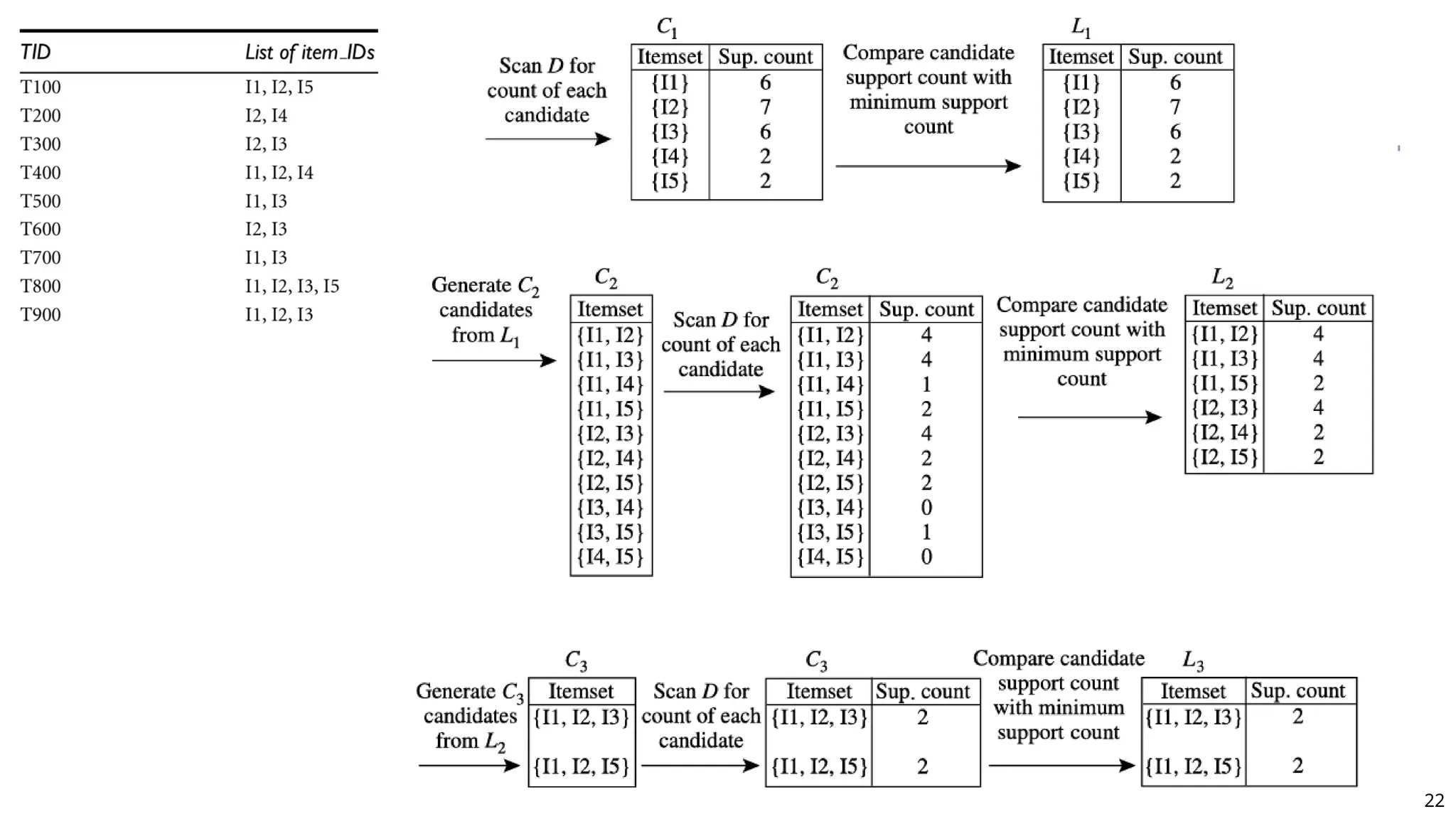
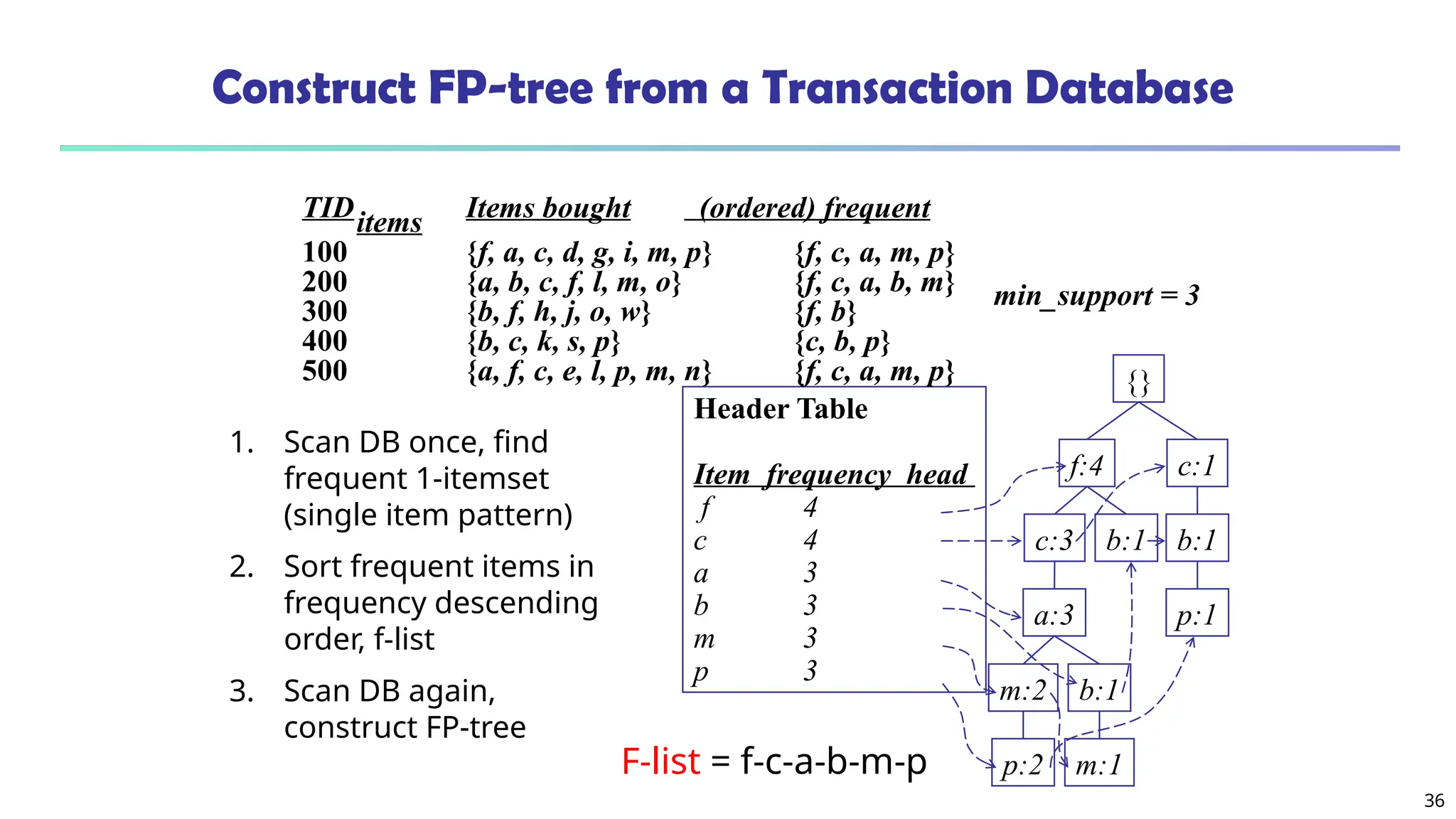
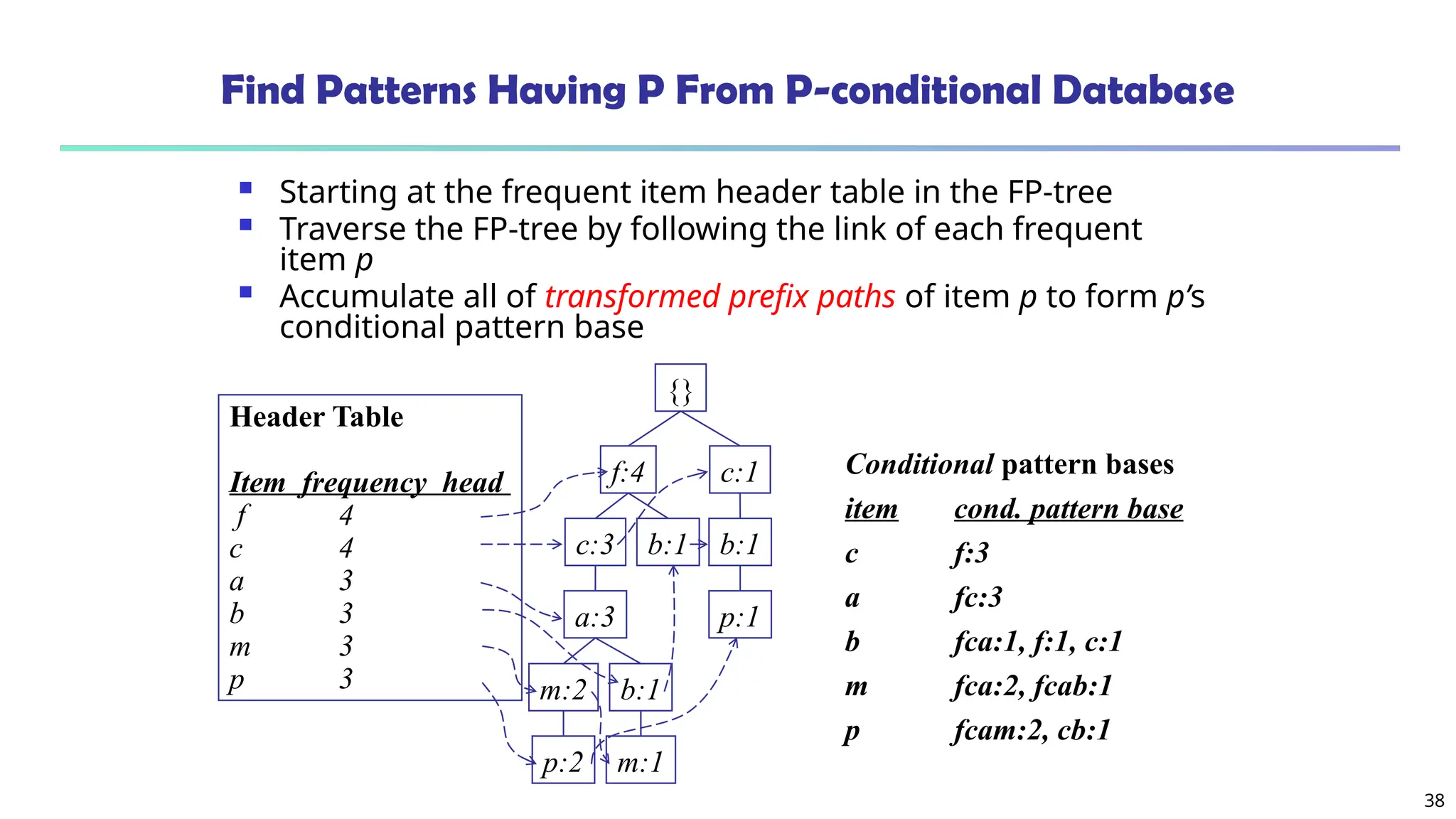
The document discusses frequent pattern mining, focusing on the identification of patterns in data sets that occur frequently, which can be applied in diverse fields such as market basket analysis and web log analysis. It outlines various methods for mining frequent patterns, including the Apriori algorithm and FPGrowth, while addressing challenges such as computational complexity and candidate generation. The content emphasizes the importance of frequent patterns in data mining and their foundational role in various analytic tasks.


![3
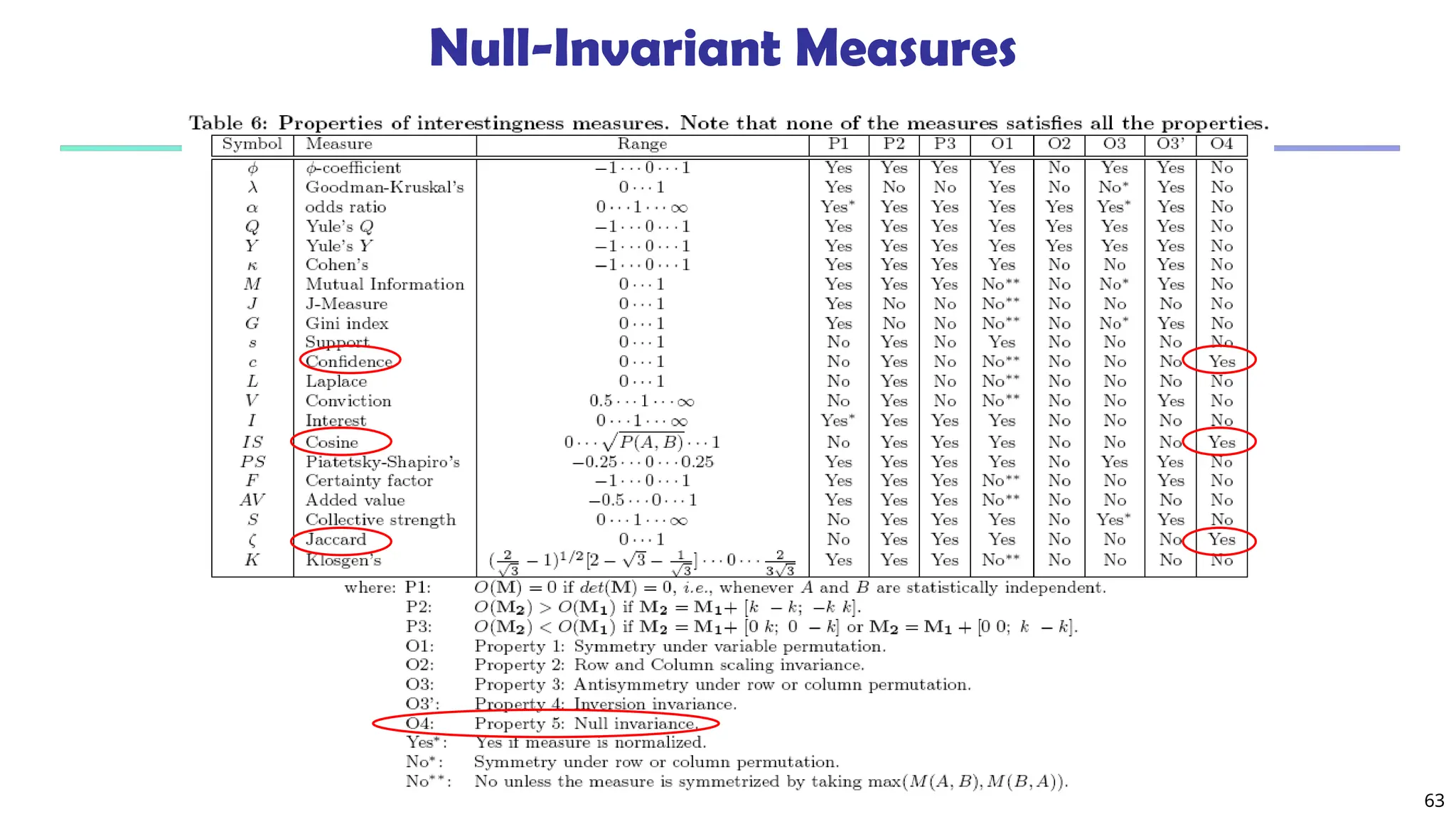
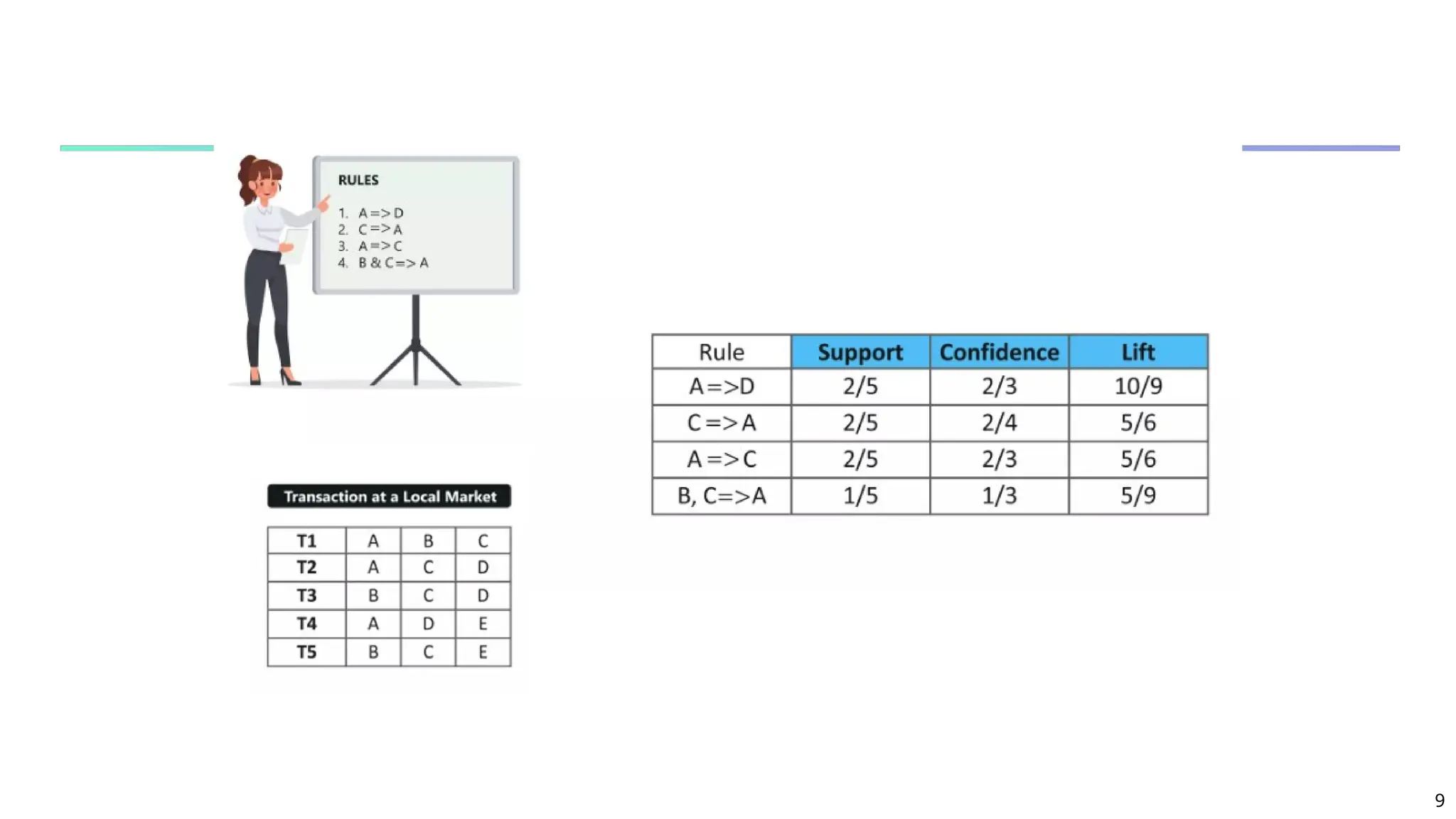
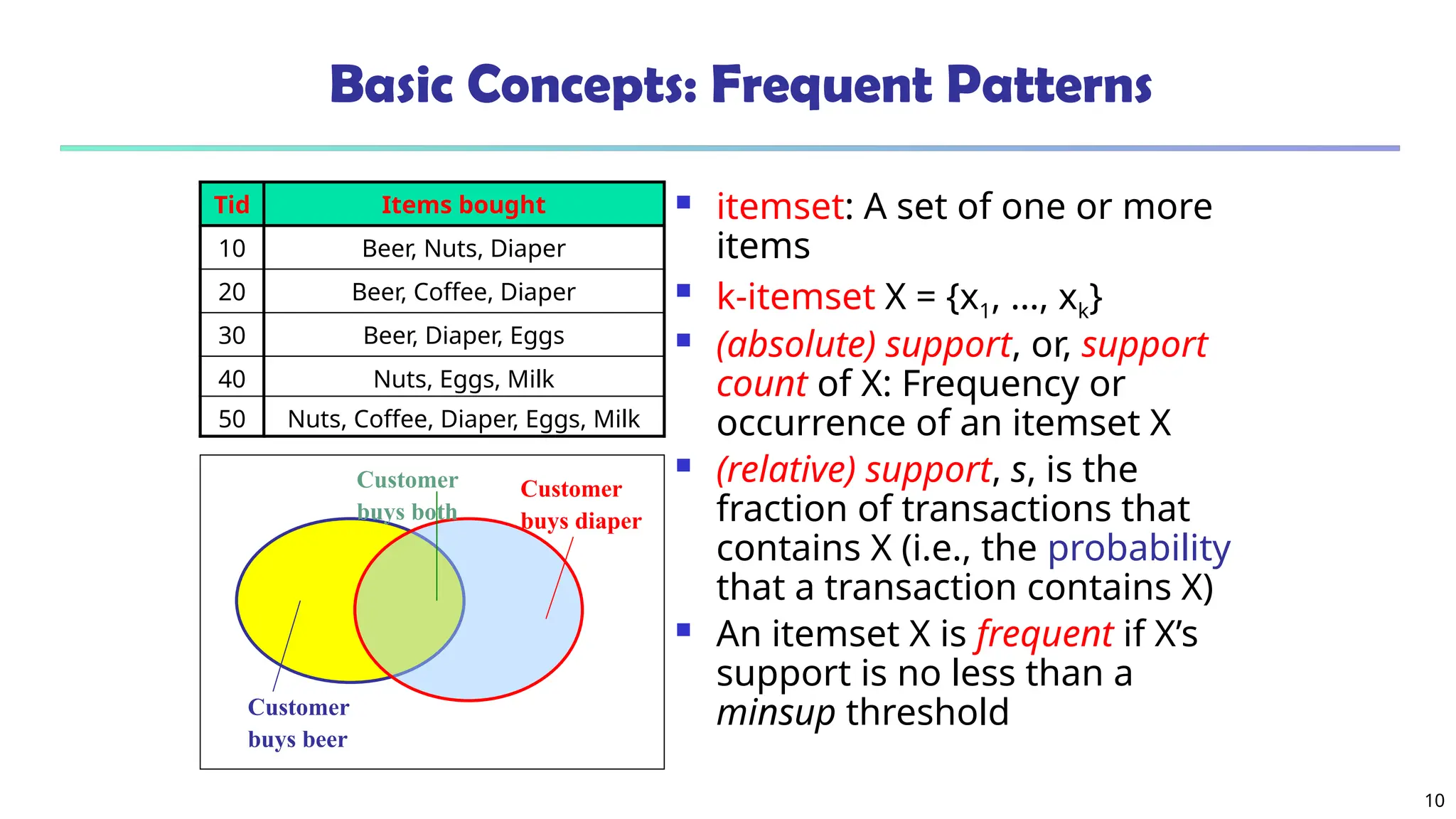
What Is Frequent Pattern Analysis?
Frequent pattern: a pattern (a set of items, subsequences,
substructures, etc.) that occurs frequently in a data set
First proposed by Agrawal, Imielinski, and Swami [AIS93] in the
context of frequent itemsets and association rule mining
Motivation: Finding inherent regularities in data
What products were often purchased together?— Beer and
diapers?!
What are the subsequent purchases after buying a PC?
What kinds of DNA are sensitive to this new drug?
Can we automatically classify web documents?
Applications
Basket data analysis
https://www.youtube.com/watch?v=3bMNqemjhsc&t=7s , cross-
marketing, catalog design, sale campaign analysis, Web log (click](https://image.slidesharecdn.com/module2-250130160923-971aff74/75/Association-Rule-Mining-Correlation-Clustering-3-2048.jpg)















![27
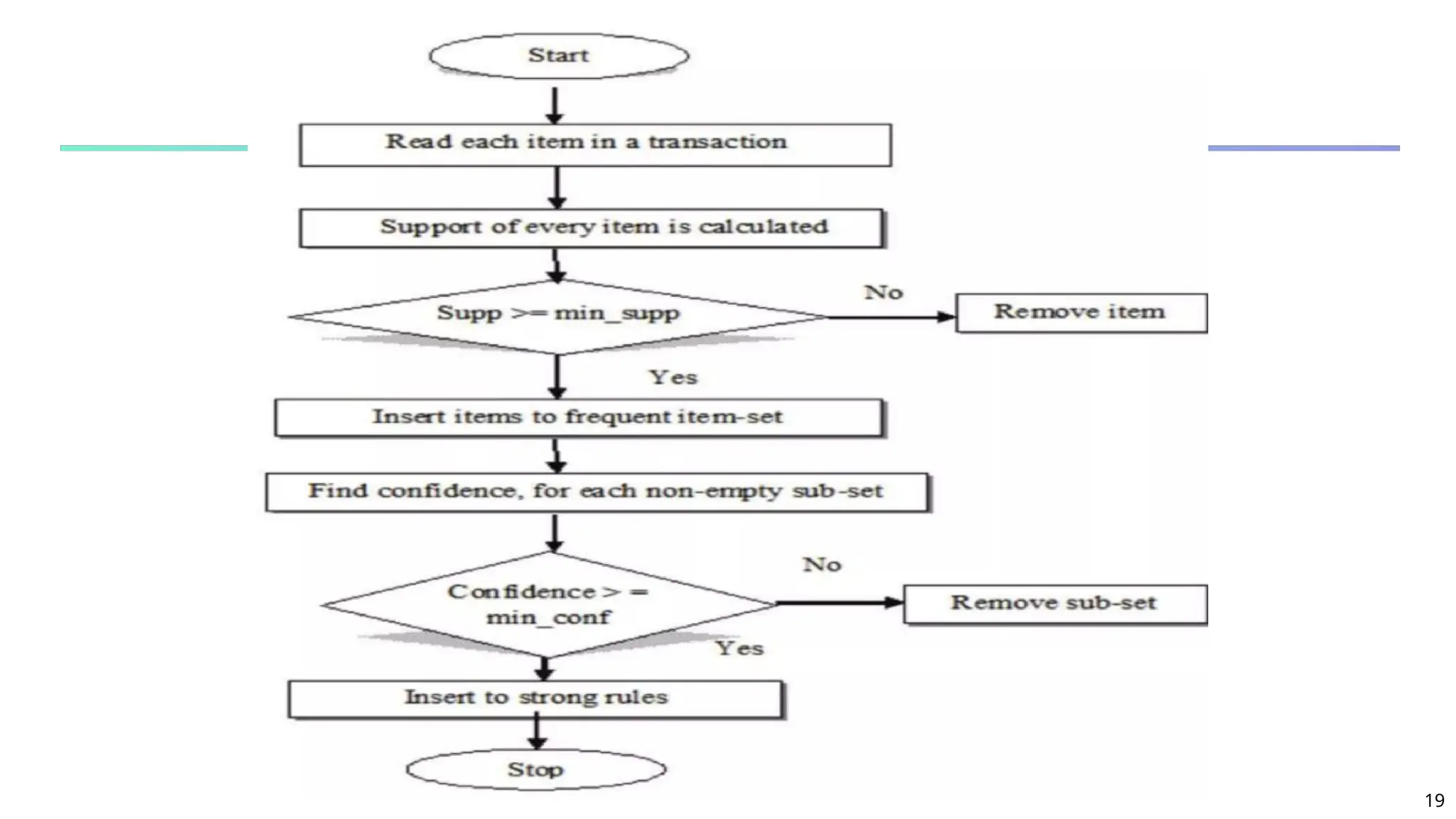
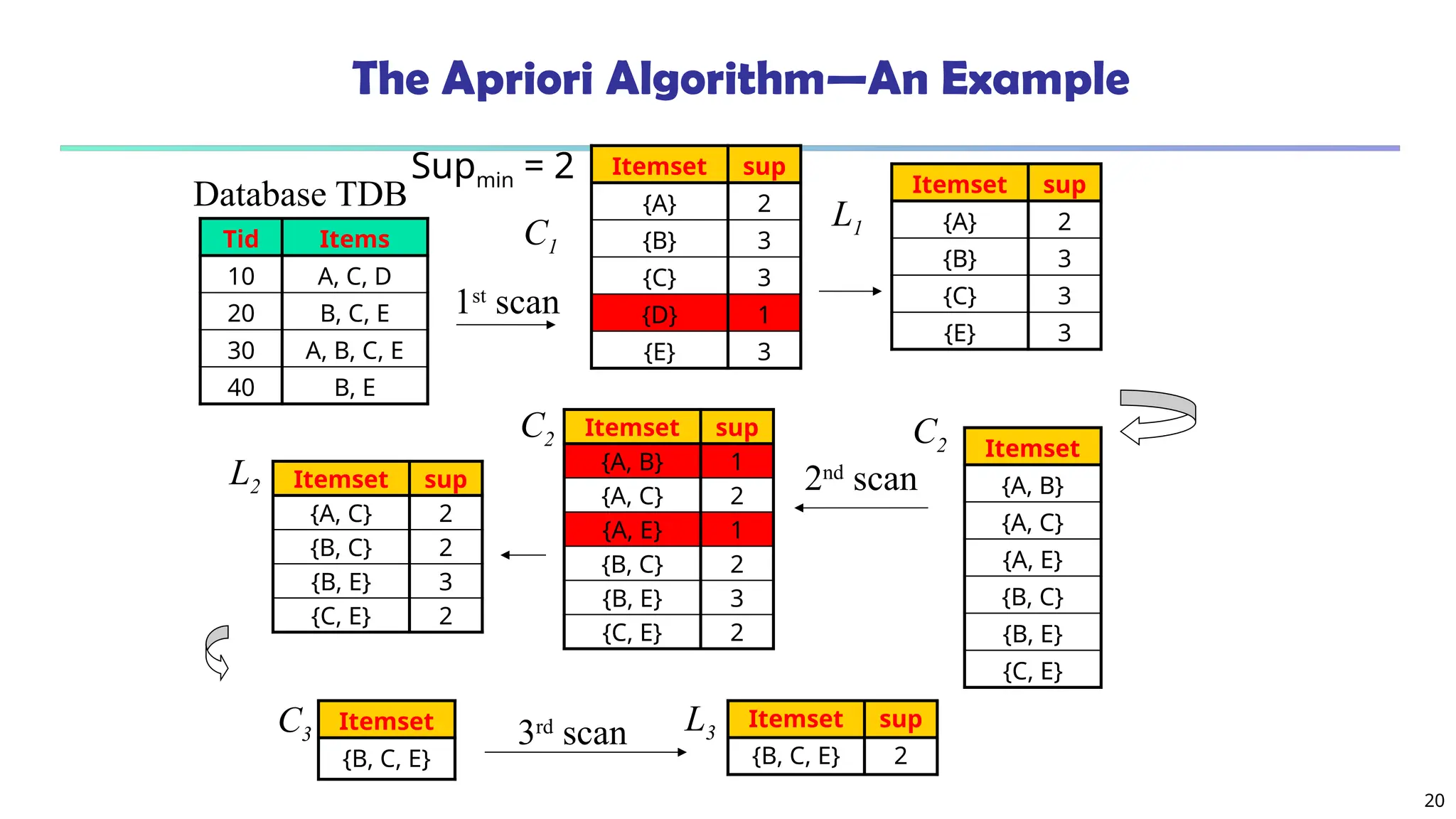
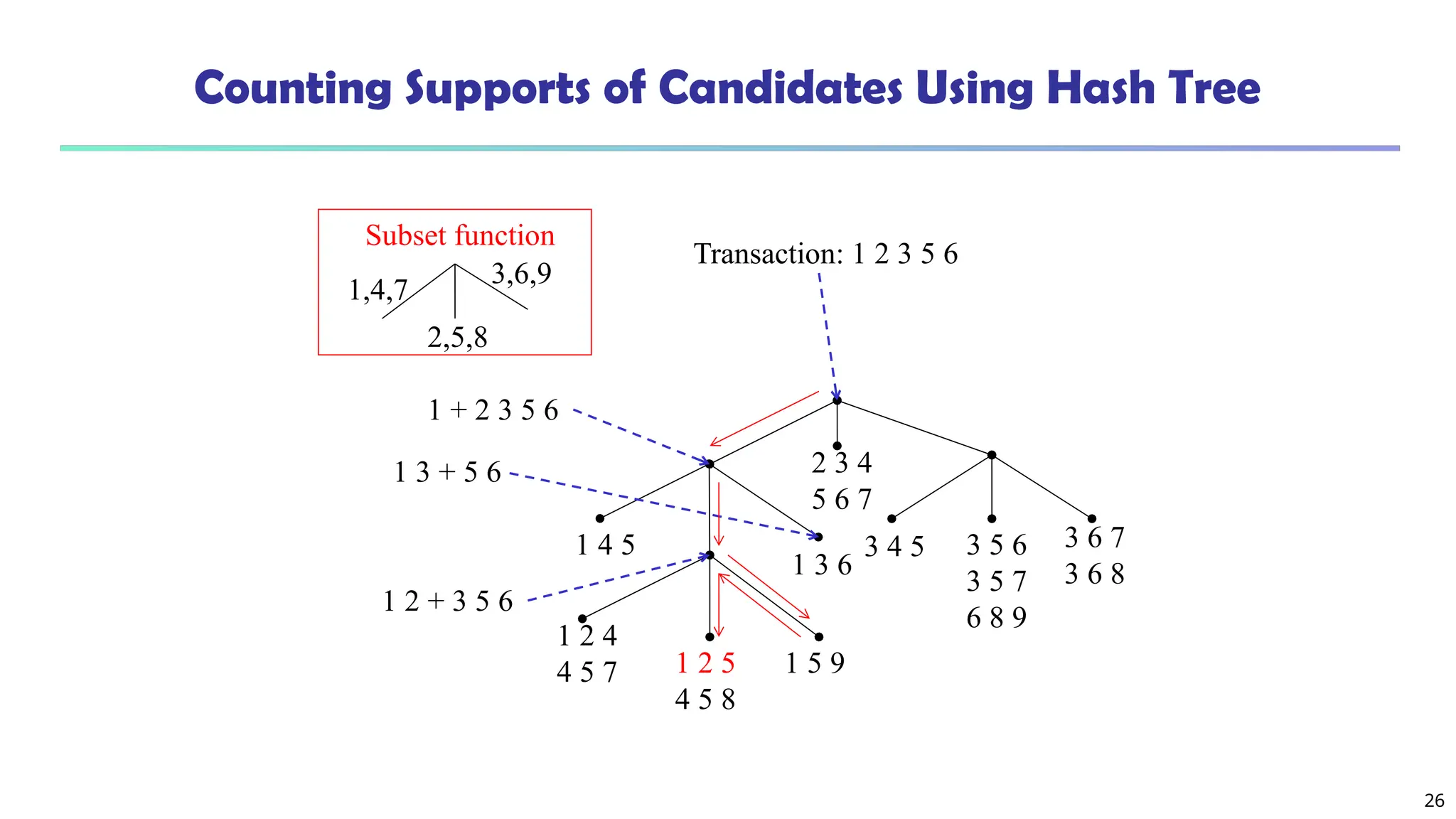
Candidate Generation: An SQL Implementation
SQL Implementation of candidate generation
Suppose the items in Lk-1 are listed in an order
Step 1: self-joining Lk-1
insert into Ck
select p.item1, p.item2, …, p.itemk-1, q.itemk-1
from Lk-1 p, Lk-1 q
where p.item1=q.item1, …, p.itemk-2=q.itemk-2, p.itemk-1 < q.itemk-1
Step 2: pruning
forall itemsets c in Ck do
forall (k-1)-subsets s of c do
if (s is not in Lk-1) then delete c from Ck
Use object-relational extensions like UDFs, BLOBs, and Table functions for
efficient implementation [See: S. Sarawagi, S. Thomas, and R. Agrawal.
Integrating association rule mining with relational database systems:
Alternatives and implications. SIGMOD’98]](https://image.slidesharecdn.com/module2-250130160923-971aff74/75/Association-Rule-Mining-Correlation-Clustering-27-2048.jpg)























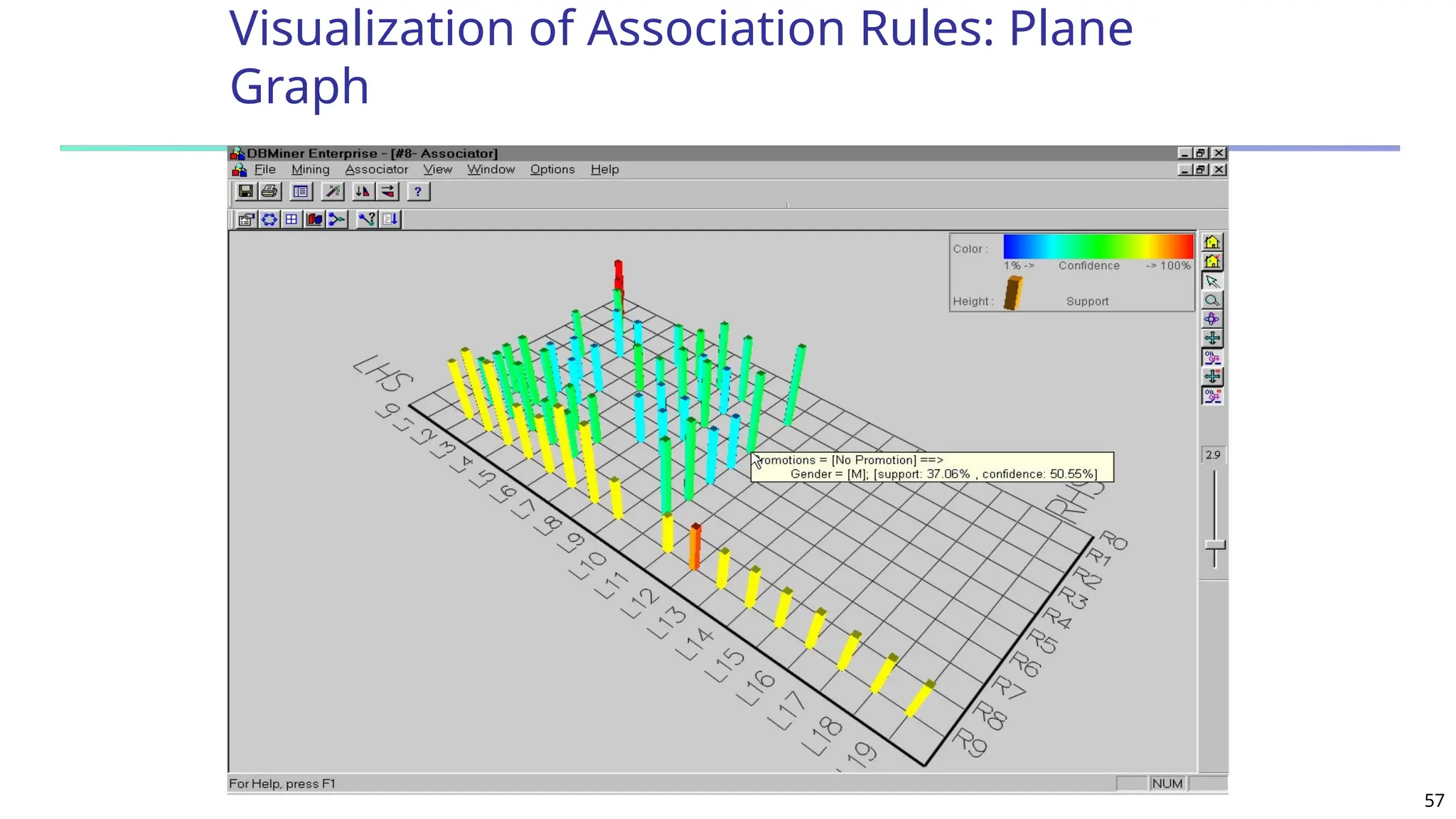
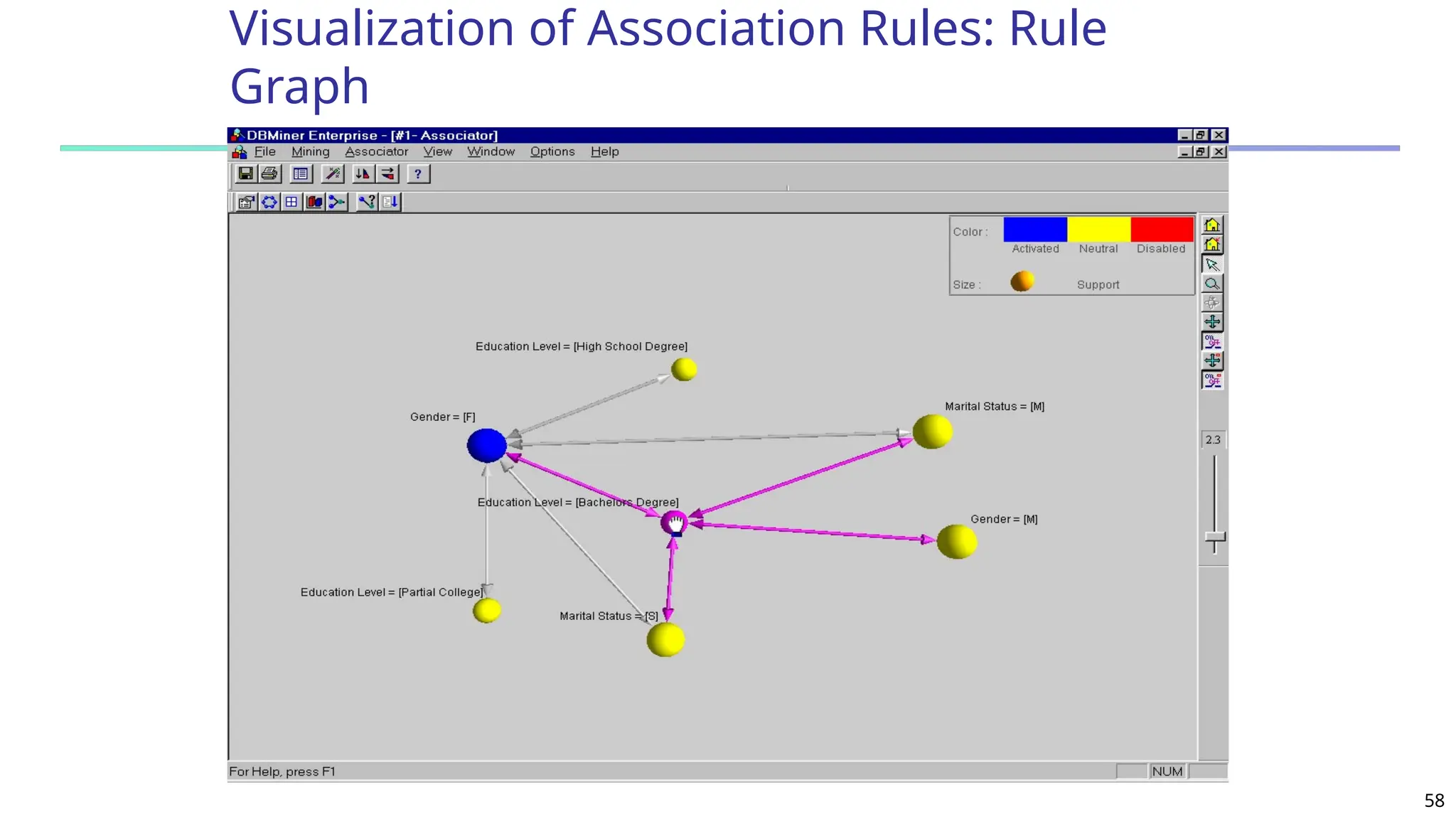
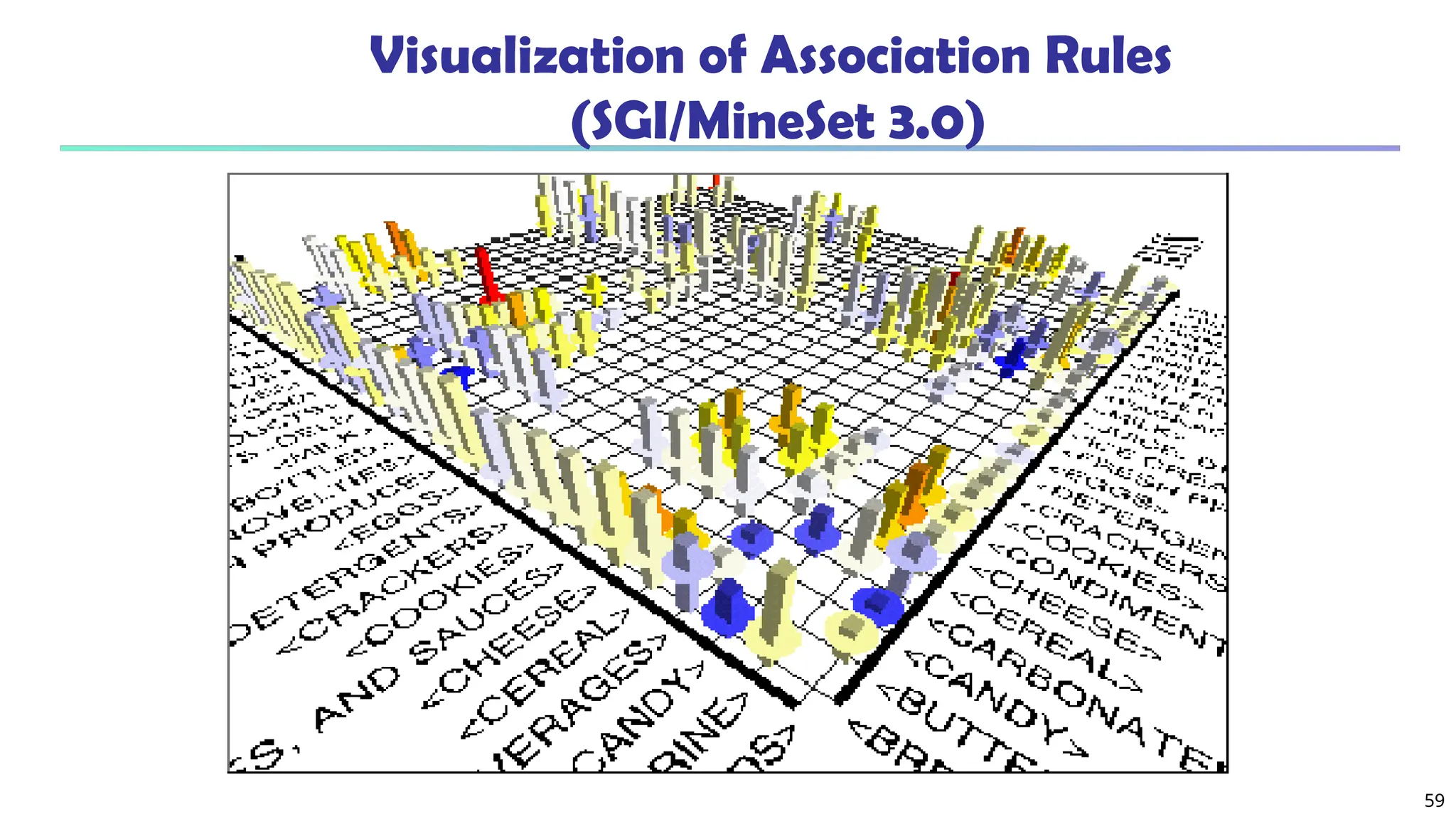

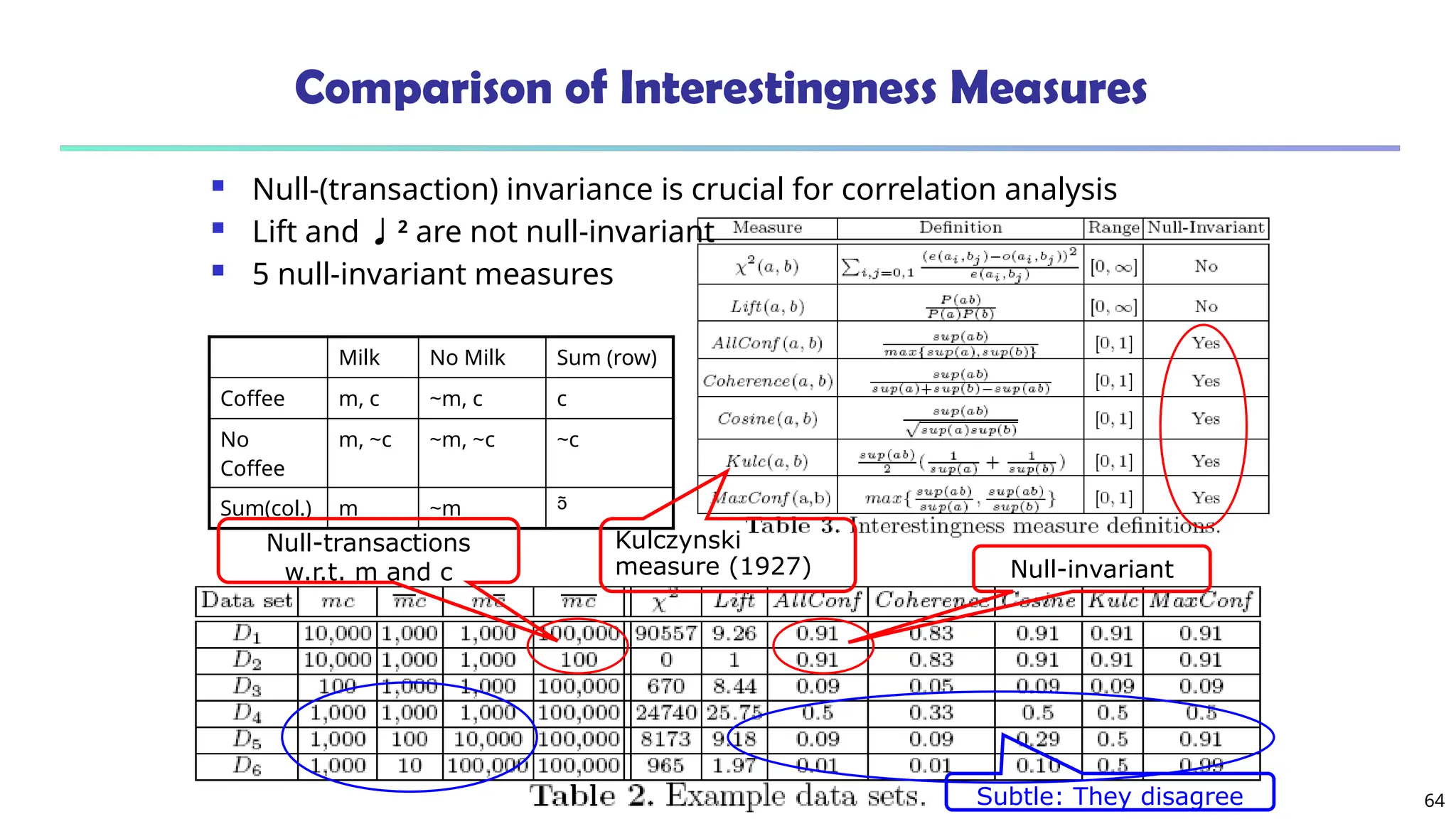
![61
Interestingness Measure: Correlations (Lift)
play basketball eat cereal [40%, 66.7%] is misleading
The overall % of students eating cereal is 75% > 66.7%.
play basketball not eat cereal [20%, 33.3%] is more accurate,
although with lower support and confidence
Measure of dependent/correlated events: lift
89
.
0
5000
/
3750
*
5000
/
3000
5000
/
2000
)
,
(
C
B
lift
Basketbal
l
Not
basketball
Sum (row)
Cereal 2000 1750 3750
Not cereal 1000 250 1250
Sum(col.) 3000 2000 5000
)
(
)
(
)
(
B
P
A
P
B
A
P
lift
33
.
1
5000
/
1250
*
5000
/
3000
5000
/
1000
)
,
(
C
B
lift](https://image.slidesharecdn.com/module2-250130160923-971aff74/75/Association-Rule-Mining-Correlation-Clustering-61-2048.jpg)
![62
Are lift and 2
Good Measures of Correlation?
“Buy walnuts buy
milk [1%, 80%]” is
misleading if 85% of
customers buy milk
Support and
confidence are not
good to indicate
correlations
Over 20
interestingness
measures have been
proposed (see Tan,
Kumar, Sritastava
@KDD’02)
Which are good ones?](https://image.slidesharecdn.com/module2-250130160923-971aff74/75/Association-Rule-Mining-Correlation-Clustering-62-2048.jpg)