Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Teruyuki Sakaue
PDF, PPTX
7,393 views
[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2
[DSO] Machine Learning Seminar Vol.1 SKUE
Science
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 54
2
/ 54
3
/ 54
4
/ 54
5
/ 54
6
/ 54
7
/ 54
8
/ 54
9
/ 54
10
/ 54
11
/ 54
12
/ 54
13
/ 54
14
/ 54
15
/ 54
16
/ 54
17
/ 54
18
/ 54
19
/ 54
20
/ 54
21
/ 54
22
/ 54
23
/ 54
24
/ 54
25
/ 54
26
/ 54
27
/ 54
28
/ 54
29
/ 54
30
/ 54
31
/ 54
32
/ 54
33
/ 54
34
/ 54
35
/ 54
36
/ 54
37
/ 54
38
/ 54
39
/ 54
40
/ 54
41
/ 54
42
/ 54
43
/ 54
44
/ 54
45
/ 54
46
/ 54
47
/ 54
48
/ 54
49
/ 54
50
/ 54
51
/ 54
52
/ 54
53
/ 54
54
/ 54
More Related Content
PDF
最近のRのランダムフォレストパッケージ -ranger/Rborist-
by
Shintaro Fukushima
PDF
はじぱた7章F5up
by
Tyee Z
PDF
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
by
Tatsuya Tojima
PDF
[DSO] Machine Learning Seminar Vol.2 Chapter 3
by
Teruyuki Sakaue
PDF
RBM、Deep Learningと学習(全脳アーキテクチャ若手の会 第3回DL勉強会発表資料)
by
Takuma Yagi
PDF
Rで学ぶロバスト推定
by
Shintaro Fukushima
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
PDF
Practical recommendations for gradient-based training of deep architectures
by
Koji Matsuda
最近のRのランダムフォレストパッケージ -ranger/Rborist-
by
Shintaro Fukushima
はじぱた7章F5up
by
Tyee Z
Tokyo.R 41 サポートベクターマシンで眼鏡っ娘分類システム構築
by
Tatsuya Tojima
[DSO] Machine Learning Seminar Vol.2 Chapter 3
by
Teruyuki Sakaue
RBM、Deep Learningと学習(全脳アーキテクチャ若手の会 第3回DL勉強会発表資料)
by
Takuma Yagi
Rで学ぶロバスト推定
by
Shintaro Fukushima
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
Practical recommendations for gradient-based training of deep architectures
by
Koji Matsuda
What's hot
PDF
確率的深層学習における中間層の改良と高性能学習法の提案
by
__106__
PDF
mxnetで頑張る深層学習
by
Takashi Kitano
PDF
機械学習を用いた予測モデル構築・評価
by
Shintaro Fukushima
PDF
PRML Chapter 14
by
Masahito Ohue
PDF
Rで学ぶデータマイニングI 第8章〜第13章
by
Prunus 1350
PDF
Chainer の Trainer 解説と NStepLSTM について
by
Retrieva inc.
PDF
ディープボルツマンマシン入門
by
Saya Katafuchi
PPTX
Feature Selection with R / in JP
by
Sercan Ahi
PPTX
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
PDF
NumPy闇入門
by
Ryosuke Okuta
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PDF
パターン認識 第10章 決定木
by
Miyoshi Yuya
PPTX
第14章集団学習
by
Kei Furihata
PDF
More modern gpu
by
Preferred Networks
PPTX
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
PDF
数式をnumpyに落としこむコツ
by
Shuyo Nakatani
PDF
深層学習 勉強会第5回 ボルツマンマシン
by
Yuta Sugii
PDF
A Machine Learning Framework for Programming by Example
by
Koji Matsuda
PDF
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter
by
sleepy_yoshi
PDF
DL Hacks輪読 Semi-supervised Learning with Deep Generative Models
by
Yusuke Iwasawa
確率的深層学習における中間層の改良と高性能学習法の提案
by
__106__
mxnetで頑張る深層学習
by
Takashi Kitano
機械学習を用いた予測モデル構築・評価
by
Shintaro Fukushima
PRML Chapter 14
by
Masahito Ohue
Rで学ぶデータマイニングI 第8章〜第13章
by
Prunus 1350
Chainer の Trainer 解説と NStepLSTM について
by
Retrieva inc.
ディープボルツマンマシン入門
by
Saya Katafuchi
Feature Selection with R / in JP
by
Sercan Ahi
[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...
by
Deep Learning JP
NumPy闇入門
by
Ryosuke Okuta
不均衡データのクラス分類
by
Shintaro Fukushima
パターン認識 第10章 決定木
by
Miyoshi Yuya
第14章集団学習
by
Kei Furihata
More modern gpu
by
Preferred Networks
猫でも分かるVariational AutoEncoder
by
Sho Tatsuno
数式をnumpyに落としこむコツ
by
Shuyo Nakatani
深層学習 勉強会第5回 ボルツマンマシン
by
Yuta Sugii
A Machine Learning Framework for Programming by Example
by
Koji Matsuda
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter
by
sleepy_yoshi
DL Hacks輪読 Semi-supervised Learning with Deep Generative Models
by
Yusuke Iwasawa
Similar to [DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2
PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
PPTX
Machine Learning Fundamentals IEEE
by
Antonio Tejero de Pablos
PDF
bigdata2012ml okanohara
by
Preferred Networks
PPTX
MLaPP輪講 Chapter 1
by
ryuhmd
PPTX
TECHTALK 20230131 ビジネスユーザー向け機械学習入門 第1回~機械学習の概要と、ビジネス課題と機械学習問題の定義
by
QlikPresalesJapan
PDF
機械学習の理論と実践
by
Preferred Networks
PDF
[DL輪読会]Deep Learning 第5章 機械学習の基礎
by
Deep Learning JP
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PPTX
機械学習の基礎
by
Ken Kumagai
PDF
わかりやすいパターン認識_3章
by
weda654
PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
PDF
PRML輪読#1
by
matsuolab
PPTX
[輪講] 第1章
by
Takenobu Sasatani
PDF
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
PDF
機械学習
by
Hikaru Takemura
PDF
20160329.dnn講演
by
Hayaru SHOUNO
PDF
それっぽく感じる機械学習
by
Yuki Igarashi
PDF
機械学習の全般について
by
Masato Nakai
PDF
PRML_from5.1to5.3.1
by
禎晃 山崎
PPTX
Deep learning basics described
by
Naoki Watanabe
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
Machine Learning Fundamentals IEEE
by
Antonio Tejero de Pablos
bigdata2012ml okanohara
by
Preferred Networks
MLaPP輪講 Chapter 1
by
ryuhmd
TECHTALK 20230131 ビジネスユーザー向け機械学習入門 第1回~機械学習の概要と、ビジネス課題と機械学習問題の定義
by
QlikPresalesJapan
機械学習の理論と実践
by
Preferred Networks
[DL輪読会]Deep Learning 第5章 機械学習の基礎
by
Deep Learning JP
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
機械学習の基礎
by
Ken Kumagai
わかりやすいパターン認識_3章
by
weda654
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
PRML輪読#1
by
matsuolab
[輪講] 第1章
by
Takenobu Sasatani
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
機械学習
by
Hikaru Takemura
20160329.dnn講演
by
Hayaru SHOUNO
それっぽく感じる機械学習
by
Yuki Igarashi
機械学習の全般について
by
Masato Nakai
PRML_from5.1to5.3.1
by
禎晃 山崎
Deep learning basics described
by
Naoki Watanabe
More from Teruyuki Sakaue
PDF
データ分析ランチセッション#24 OSSのAutoML~TPOTについて
by
Teruyuki Sakaue
PDF
機械学習による積極的失業〜オウンドメディアの訪問予測
by
Teruyuki Sakaue
PDF
Marketing×Python/Rで頑張れる事例16本ノック
by
Teruyuki Sakaue
PDF
[第6回]データ分析ランチセッション - Camphrでモダンな自然言語処理
by
Teruyuki Sakaue
PDF
実務と論文で学ぶジョブレコメンデーション最前線2022
by
Teruyuki Sakaue
PDF
[丸ノ内アナリティクスバンビーノ#23]データドリブン施策によるサービス品質向上の取り組み
by
Teruyuki Sakaue
PDF
警察庁オープンデータで交通事故の世界にDeepDive!
by
Teruyuki Sakaue
PDF
[DSO] Machine Learning Seminar Vol.8 Chapter 9
by
Teruyuki Sakaue
PDF
[第11回]データ分析ランチセッション - モダンな機械学習データパイプラインKedroを触ってみる
by
Teruyuki Sakaue
PDF
[Music×Analytics]プロの音に近づくための研究と練習
by
Teruyuki Sakaue
PDF
流行りの分散表現を用いた文書分類について Netadashi Meetup 7
by
Teruyuki Sakaue
PDF
HRビジネスにおけるデータサイエンスの適用 @ BIT VALLEY -INSIDE- Vol.1
by
Teruyuki Sakaue
PDF
[第1回]データ分析ランチセッション ~ Qiita Advent Calendar2019から得た情報10選
by
Teruyuki Sakaue
PDF
地理データを集め、可視化し分析することが簡単にできるプログラミング言語について @ BIT VALLEY -INSIDE- Vol.16
by
Teruyuki Sakaue
データ分析ランチセッション#24 OSSのAutoML~TPOTについて
by
Teruyuki Sakaue
機械学習による積極的失業〜オウンドメディアの訪問予測
by
Teruyuki Sakaue
Marketing×Python/Rで頑張れる事例16本ノック
by
Teruyuki Sakaue
[第6回]データ分析ランチセッション - Camphrでモダンな自然言語処理
by
Teruyuki Sakaue
実務と論文で学ぶジョブレコメンデーション最前線2022
by
Teruyuki Sakaue
[丸ノ内アナリティクスバンビーノ#23]データドリブン施策によるサービス品質向上の取り組み
by
Teruyuki Sakaue
警察庁オープンデータで交通事故の世界にDeepDive!
by
Teruyuki Sakaue
[DSO] Machine Learning Seminar Vol.8 Chapter 9
by
Teruyuki Sakaue
[第11回]データ分析ランチセッション - モダンな機械学習データパイプラインKedroを触ってみる
by
Teruyuki Sakaue
[Music×Analytics]プロの音に近づくための研究と練習
by
Teruyuki Sakaue
流行りの分散表現を用いた文書分類について Netadashi Meetup 7
by
Teruyuki Sakaue
HRビジネスにおけるデータサイエンスの適用 @ BIT VALLEY -INSIDE- Vol.1
by
Teruyuki Sakaue
[第1回]データ分析ランチセッション ~ Qiita Advent Calendar2019から得た情報10選
by
Teruyuki Sakaue
地理データを集め、可視化し分析することが簡単にできるプログラミング言語について @ BIT VALLEY -INSIDE- Vol.16
by
Teruyuki Sakaue
[DSO] Machine Learning Seminar Vol.1 Chapter 1 and 2
1.
[DSO] Machine Learning
Seminar Vol.1[DSO] Machine Learning Seminar Vol.1 2020-02-13 SKUE
2.
3.
Chapter1:「データから学習する能⼒」をコンピュータChapter1:「データから学習する能⼒」をコンピュータに与えるに与える 機械学習の⼀般概念 3種類の学習と基本⽤語 機械学習システムをうまく設計するための構成要素 データ解析と機械学習のためのPythonのインストールとセットアップ
4.
機械学習の⼀般概念機械学習の⼀般概念 機械学習はデータの意味を理解するアルゴリズムの応⽤と科学とされてい る。蓄積されたデータから意味を⾒出し知識に変えることができる。 機械学習は⼈⼯知能の⼀分野として発展し、データを分析してルールを導き 出すなどを⼈⼿を介さずに⾏えるようにした。
5.
3種類の学習と基本⽤語3種類の学習と基本⽤語 機械学習は⼤きく分けて3種類ある 教師あり学習 教師なし学習 強化学習
6.
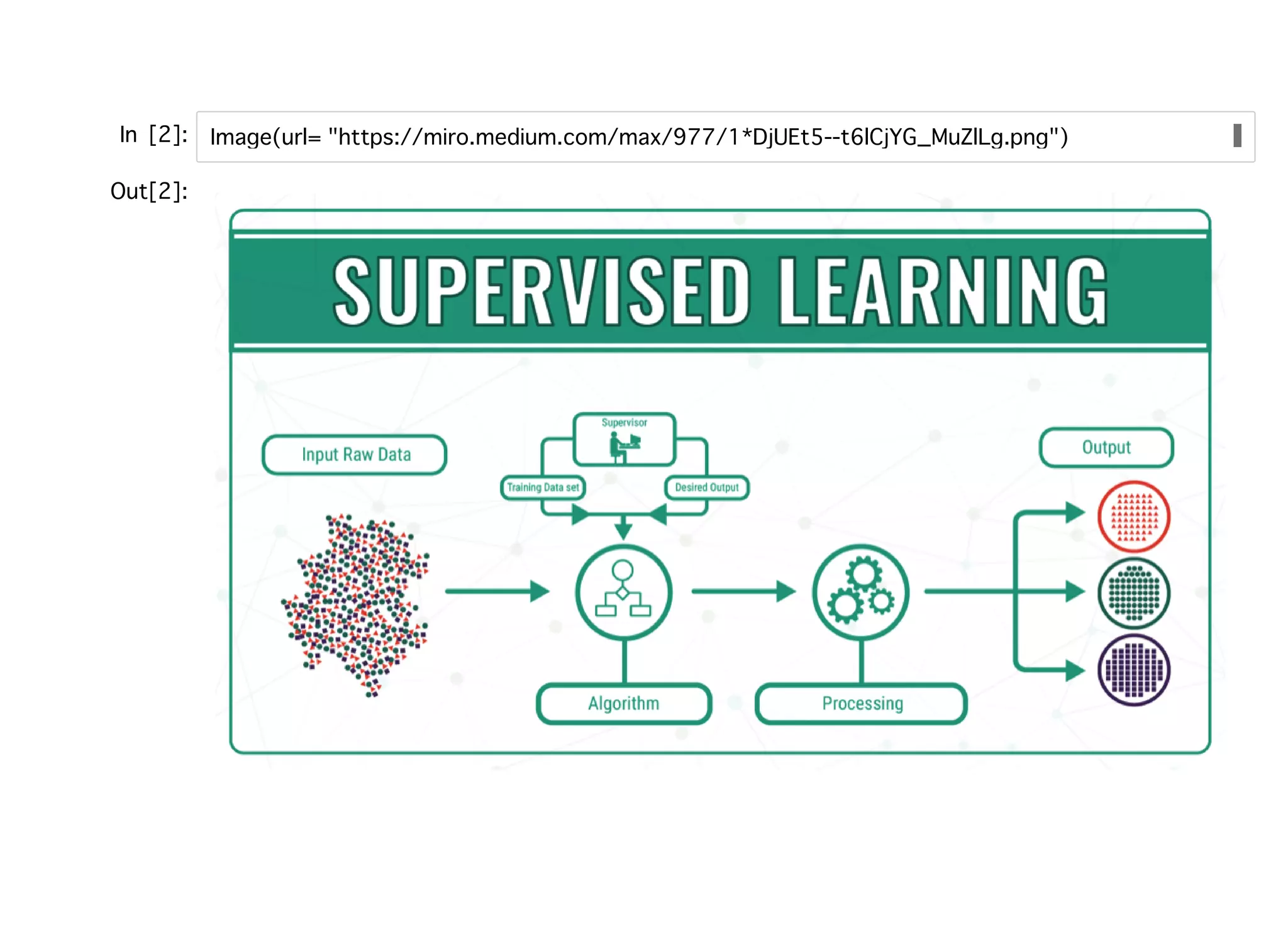
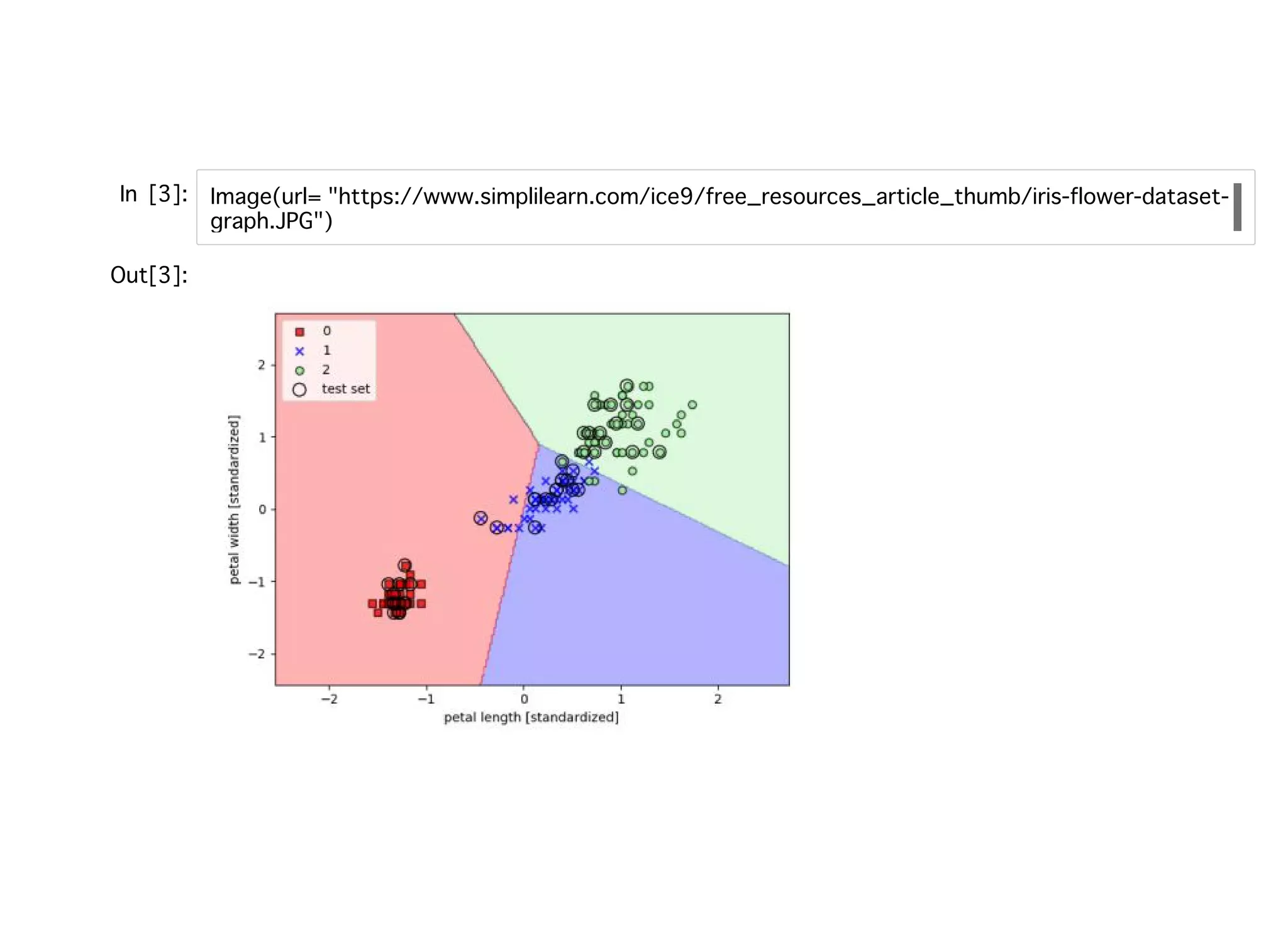
教師あり学習教師あり学習 ラベル付けされたトレーニングデータからモデルを学習し、未知のデータを予測でき るようにすることを⽬標とした機械学習。⽬的関数として真のラベルとの誤差⼆乗和 などを取り、それらの最適化を⾏う。 分類(バイナリ、マルチクラス):離散値が教師データ。 回帰:連続値が教師データ。
7.
8.
9.
10.
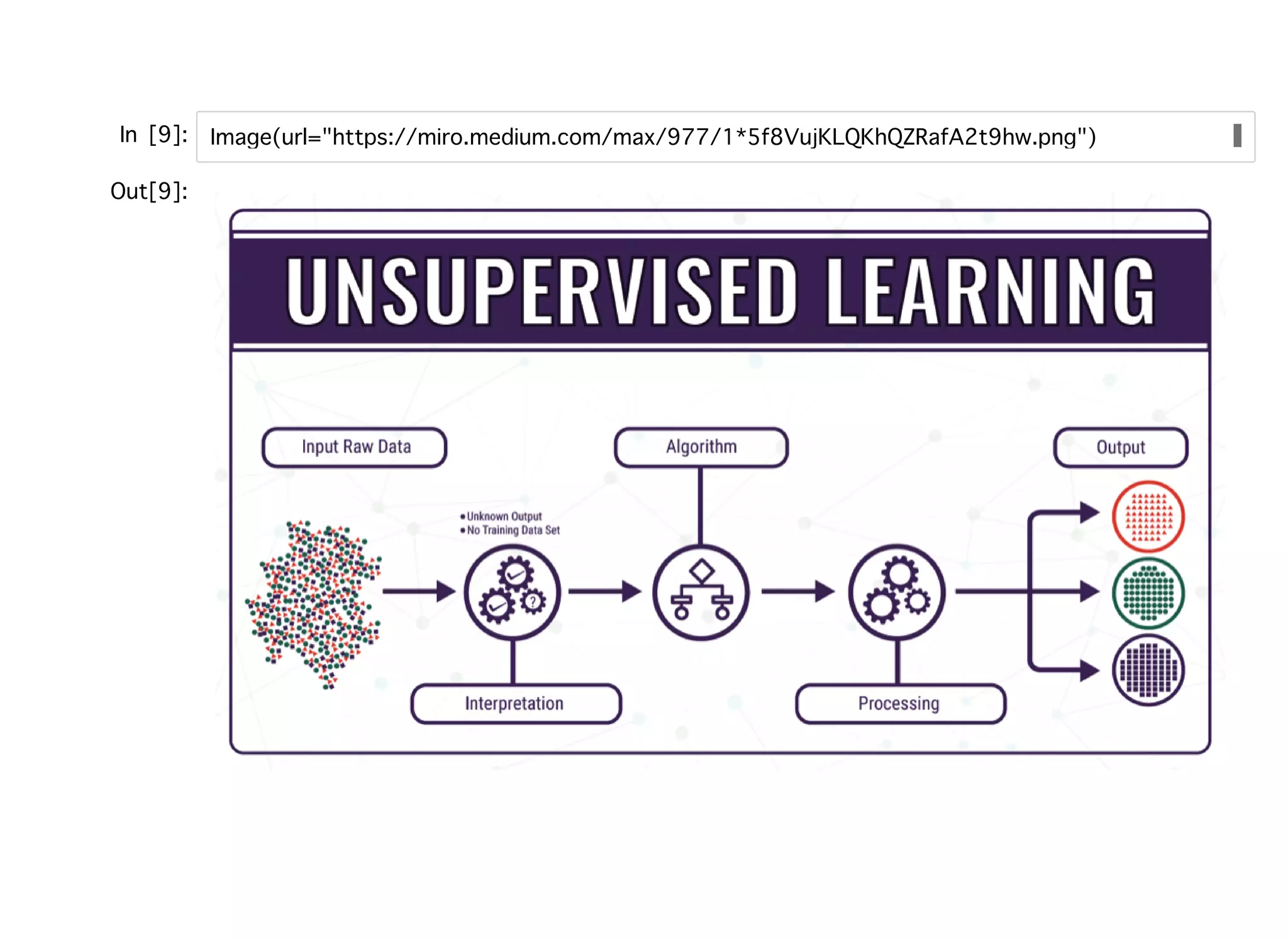
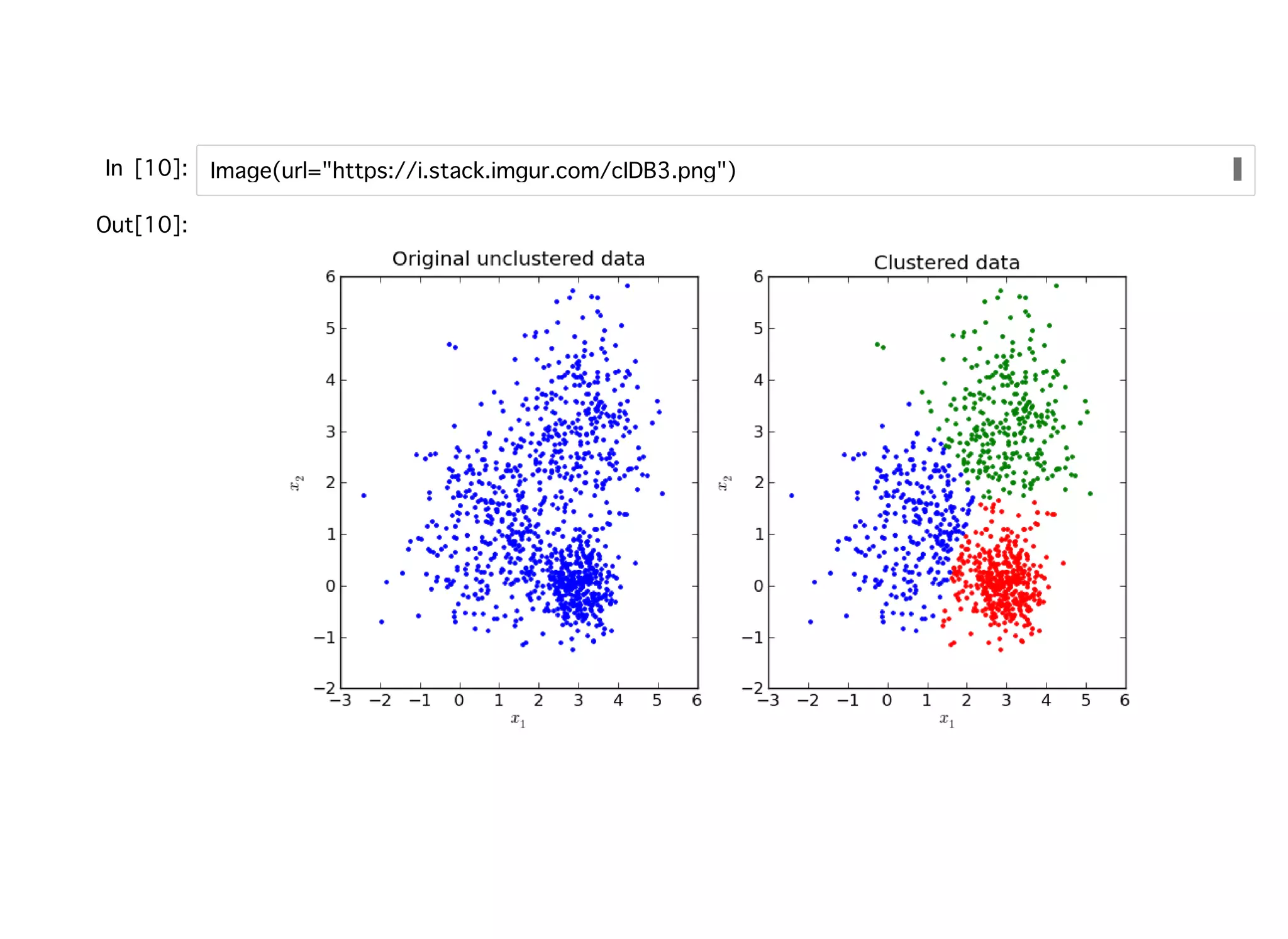
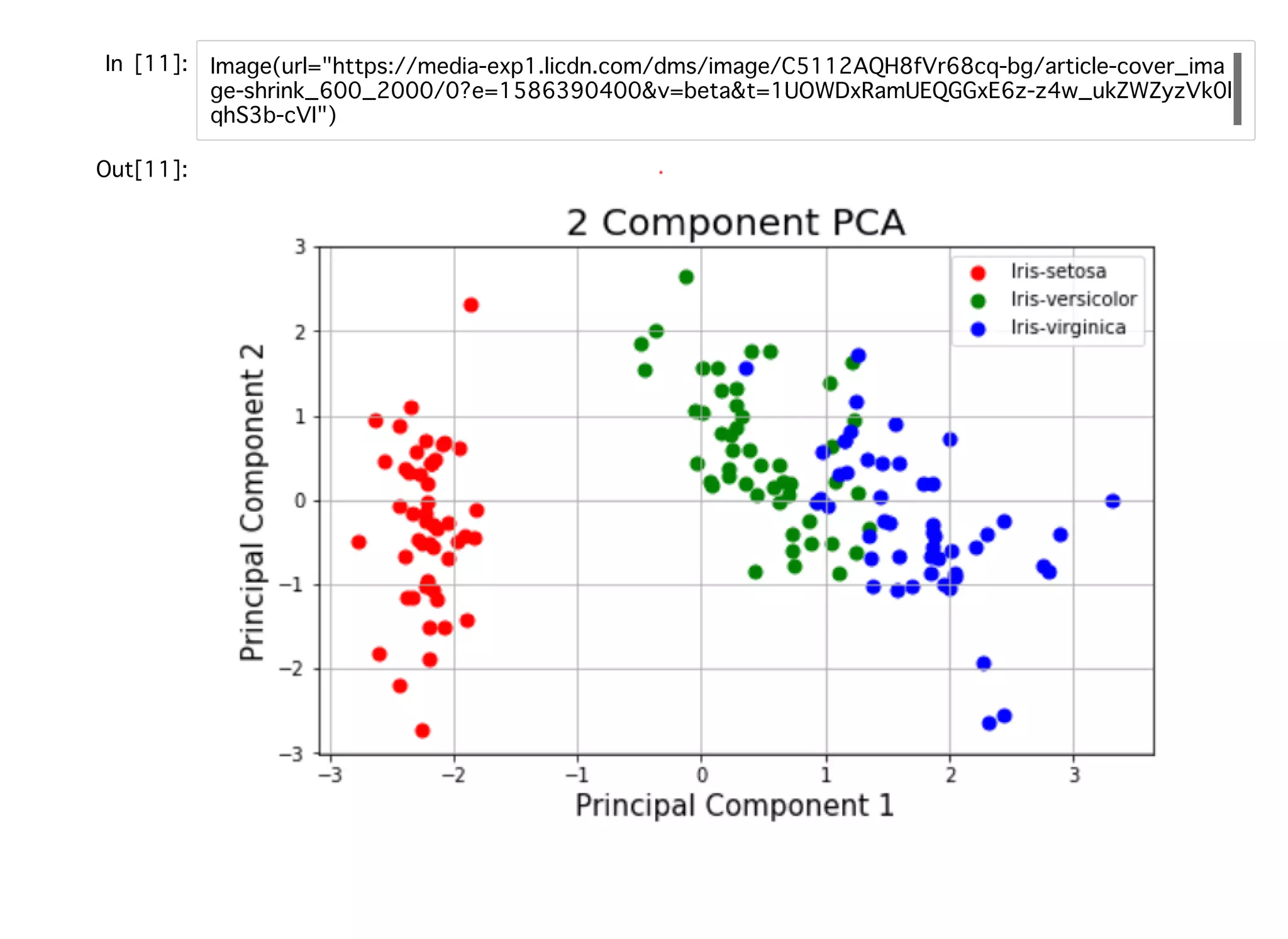
教師なし学習教師なし学習 ラベル付けされていないデータをもとにデータの構造を抽出するための機械学習。 クラスタリング:階層クラスタリング、⾮階層クラスタリング(k-means) 次元圧縮:PCA
11.
12.
13.
14.
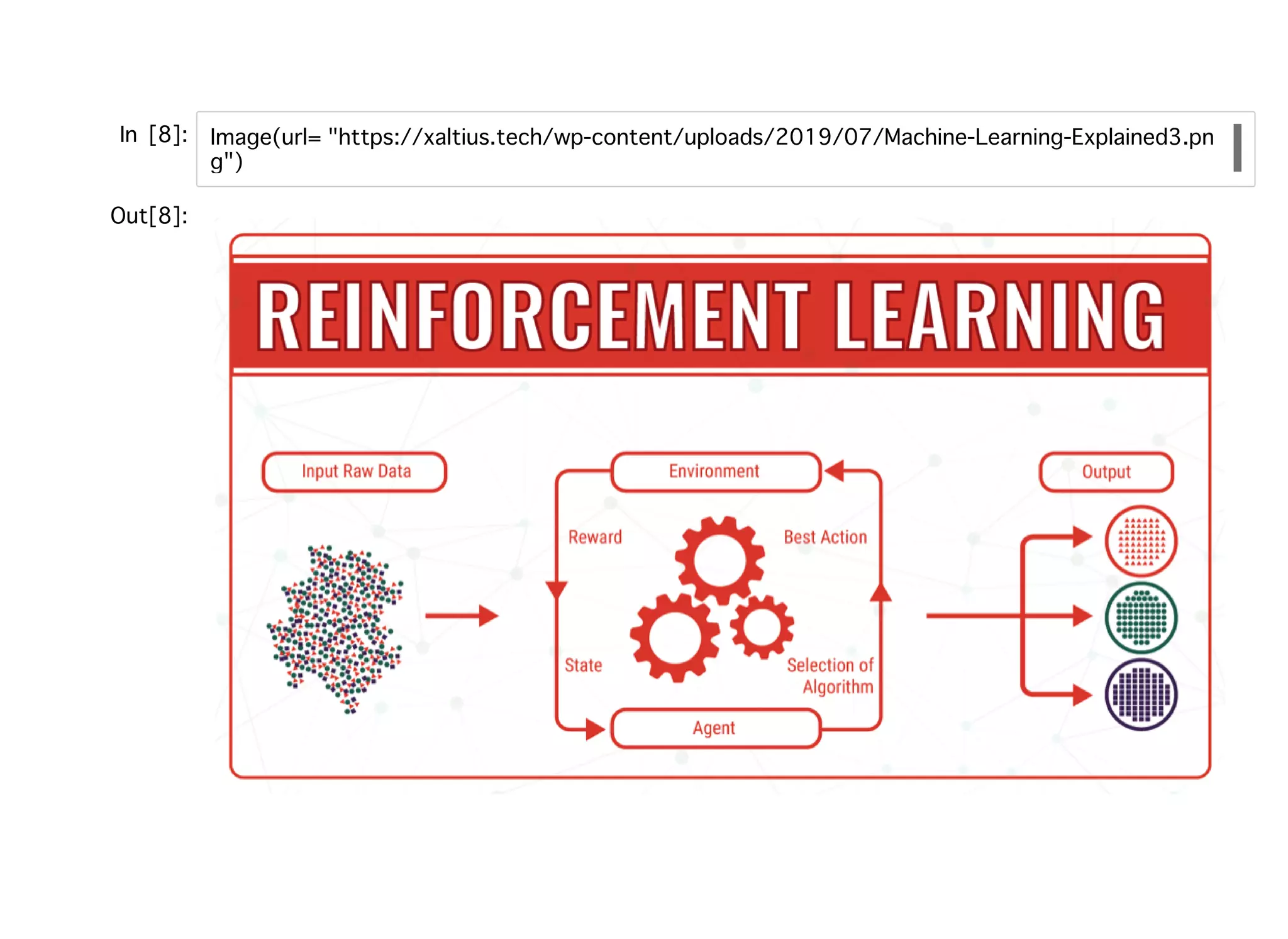
強化学習強化学習 エージェントが環境とのやり取りを通じて報酬の最⼤化をする学習⽅法。 教師あり学習は正例や負例を当てることを⽬的関数として学習していたが、 強化学習では報酬という⽬的関数をおいてそれの最適化を⾏う。 ゲームにおける報酬は「勝ち負け」 Webサービスにおける報酬は「コンバージョン」 ⾃動運転における報酬は「安⼼⾛⾏(⾮定量的)」
15.
16.
基本⽤語基本⽤語 特徴量:分析対象のデータセットからラベルを除いたもの。(属性、計測値 など) 線形代数(特徴量全体は⾏列、各々の特徴量はベクトル) サンプル:機械学習で扱うデータセットのこと。インスタンスとも観測とも 呼ぶ。 ラベル:教師データのこと。ターゲットとも呼ぶ。
17.
機械学習システムを構築するためのロードマップ機械学習システムを構築するためのロードマップ 1.前処理:トレーニングデータセットとテストデータセットを作る⼯程。 特徴抽出やスケーリング 特徴選択 次元削減 サンプリング 2.学習:アルゴリズムの⼯程。 機械学習のモデル選択:モデルは数え切れないほどある。 交差検証(クロスバリデーション):交差検証のやり⽅も様々あ る。 性能指標:指標も様々。 ハイパーパラメータ最適化:最適化の⽅法も様々。 3.評価 テストデータセットを使った最終モデルの評価(⼆度漬け禁⽌) kaggleで⾔うとPrivate Score⽤のデータセットに該当。 4.予測 新しいデータにモデルを適⽤して予測する。それを任意のアプリケ ーションで⽤いる。
18.
データ解析と機械学習のためのPythonのインストールとセットアッデータ解析と機械学習のためのPythonのインストールとセットアッププ 教科書ではAnacondaがおすすめされているが、Google Colabで良いと思われ る。 データサイエンス系のパッケージ NumPy pandas matplotlib SciPy scikit-learn
19.
Chapter2:分類問題- 単純な機械学習アルゴリズムのトChapter2:分類問題- 単純な機械学習アルゴリズムのトレーニングレーニング パーセプトロン ADALINE 勾配降下法 勾配降下法とスケーリング 確率的勾配降下法
20.
パーセプトロンパーセプトロン ⼈⼯ニューロン パーセプトロンの学習規則 Pythonでの実装
21.
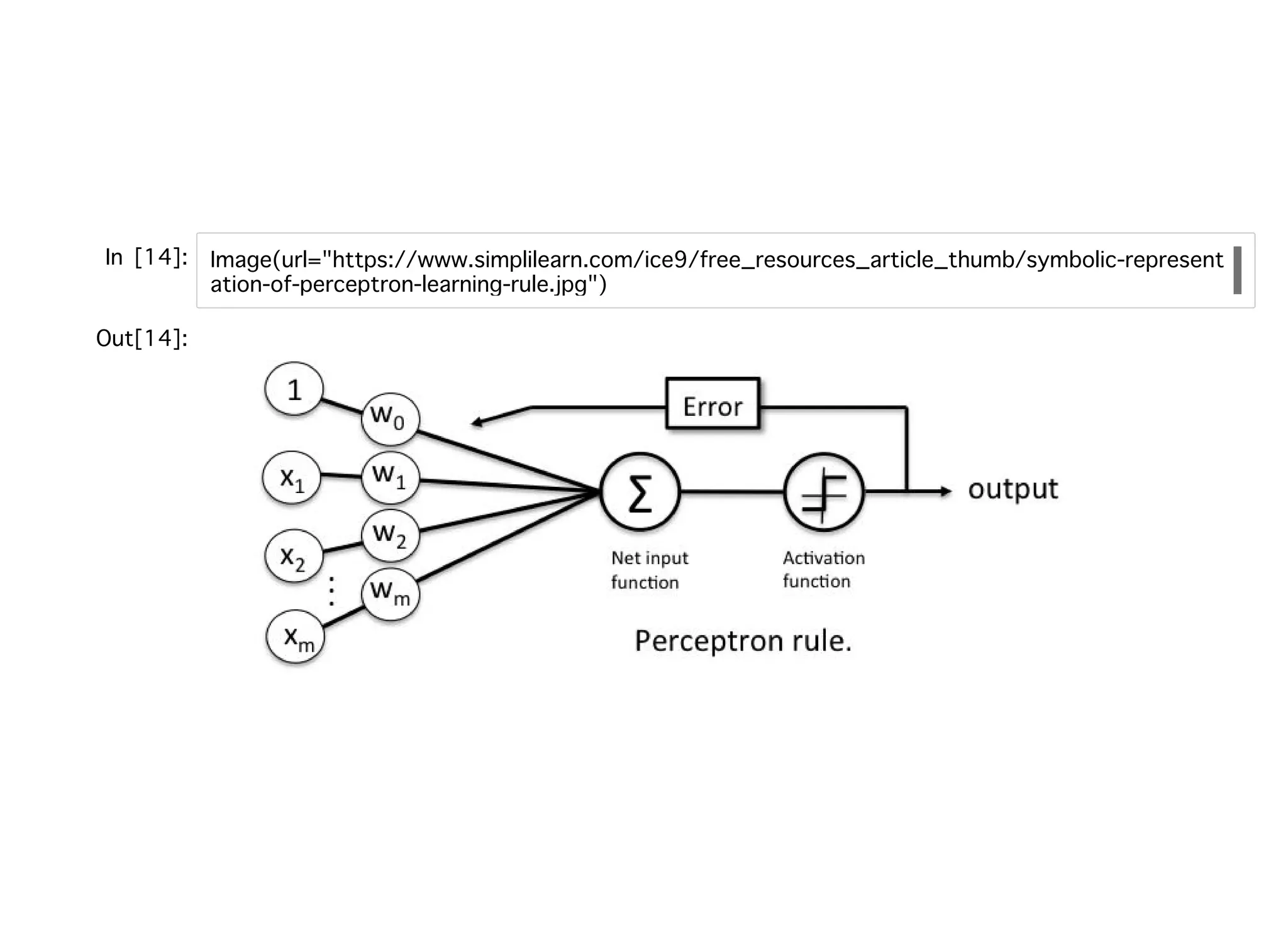
⼈⼯ニューロン⼈⼯ニューロン zを総⼊⼒、xを⼊⼒値、wを重みベクトルとする。 以下の単位ステップ関数を定義する。 これを決定関数と呼ぶ。 まら、閾値を左辺に移動し、インデックス0の重みを として改めてパーセプトロンを定義すると。 で表すことができる。この負の閾値、 のことをバイアスユニットと呼ぶ。 z = x
= + ⋯ +w T w1 x1 wm xm ϕ(z) = { 1 z ≧ θ −1 z < θ なお、θ は閾値となっている。 = −θw0 = 1x0 z = x = + + ⋯ +w T w0 x0 w1 x1 wm xm ϕ(z) = { 1 z ≧ 0 −1 z < 0 = −θw0
22.
パーセプトロンの学習規則パーセプトロンの学習規則 1.重みを0または値の⼩さい乱数で初期化する。 2.トレーニングサンプルごとに以下の⼿順を実⾏する。 2-1.出⼒値を計算する(単位ステップ関数による予測) 2-2.重みを更新する における重みの更新は に従って⾏われる。ηは学習率で0.0〜1.0以下の定数がおかれる。yの真の値と予測値 との間で差異があれば重みを更新するという仕組みになっている。 これらはベクトルなので、各々の要素がこの更新式によって同時に更新されることと なる。 z = x
= + ⋯ +w T w1 x1 wm xm := + Δwj wj wj Δ = η( − )wj y (i) ŷ (i) x (i) j
23.
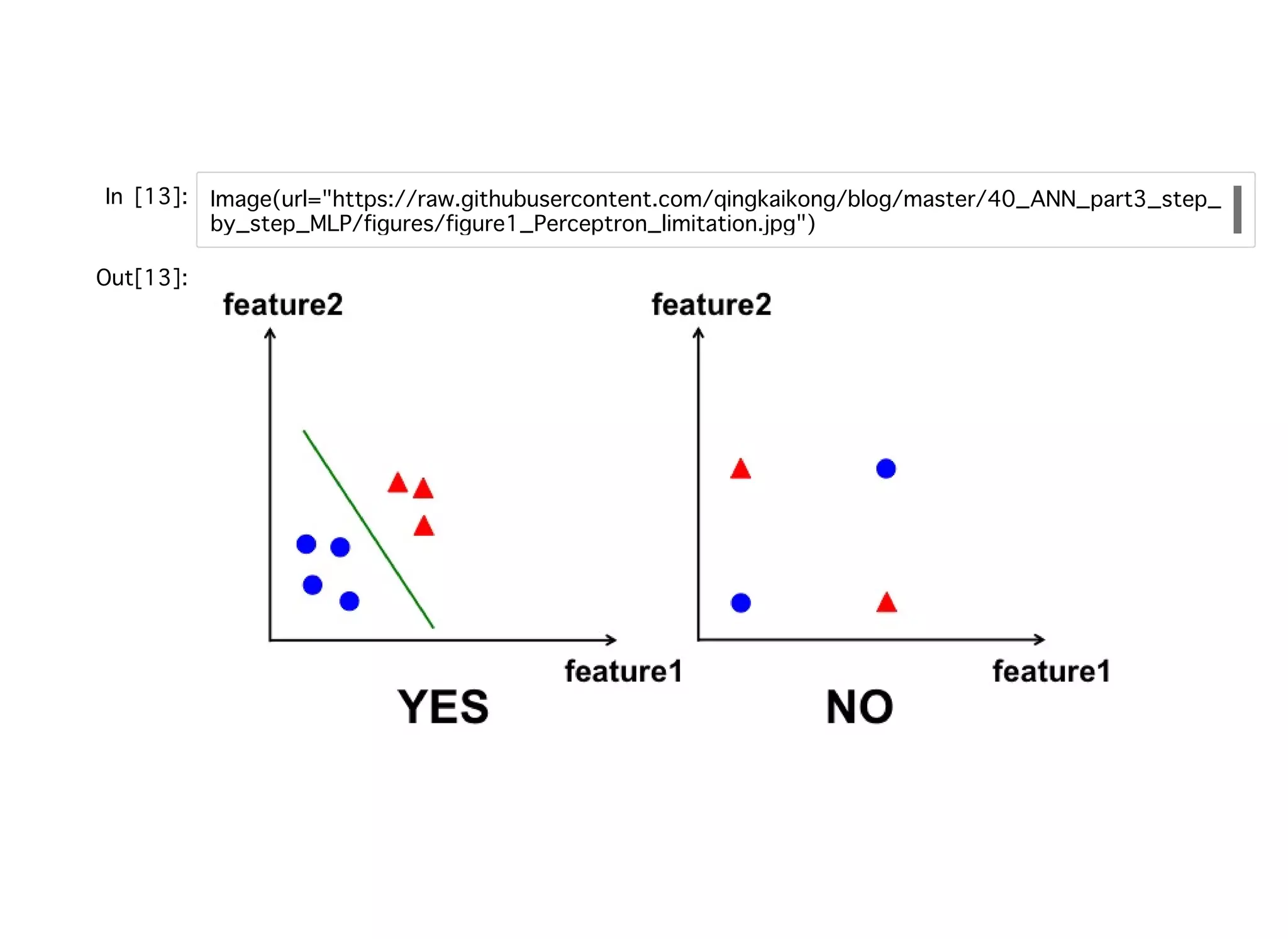
パーセプトロンの学習規則の思考実験パーセプトロンの学習規則の思考実験 正しくラベルを予測した場合 予測が間違っていた場合(その1):xが⼩さいケース(η=1) 予測が間違っていた場合(その2):xが⼤きいケース(η=1) このように誤分類したとして、xの値や学習率によって⼤きく重みの更新がなされるこ とになる。なお、パーセプトロンが収束するケースは、2つのクラスが線形分離可能 で学習率が⼗分に⼩さいときに限られる。 線形分離が不能な場合は、トレーニングの最⼤回数(エポック)や誤分類の最⼤数を 設定することで重み付けの更新を終了させる。 Δ = η(−1
− (−1)) = 0wj x (i) j Δ = η(1 − 1)) = 0wj x (i) j Δ = η(1 − (−1)) = η2 = 1 × 2 × 0.5 = 1wj x (i) j x (i) j Δ = η(−1 − 1)) = −η2 = −1 × 2 × 0.5 = −1wj x (i) j x (i) j Δ = η(1 − (−1)) = η2 = 1 × 2 × 2 = 4wj x (i) j x (i) j Δ = η(−1 − 1)) = −η2 = −1 × 2 × 2 = −4wj x (i) j x (i) j
24.
25.
Pythonでの実装Pythonでの実装
26.
27.
定義 生成 際 自動的
呼 出 関数 再利用 際 必要 指定 以下 見 様 値 持 関数間 利用 学習率 反復回数 乱数
28.
乱数 生成 分布 中心
平均 分布 標準偏差 出力 際 最初 意味 変数 数 返 誤差 空箱 反復回数 繰 返 場合 意味 繰 返 処理 形 変換 関数 数 繰 返 前述 更新式 重 更新 設定 別 更新 誤差 整数 足 反復 誤差 誤差 重 伴 値 返 内積 計算 単位 関数
29.
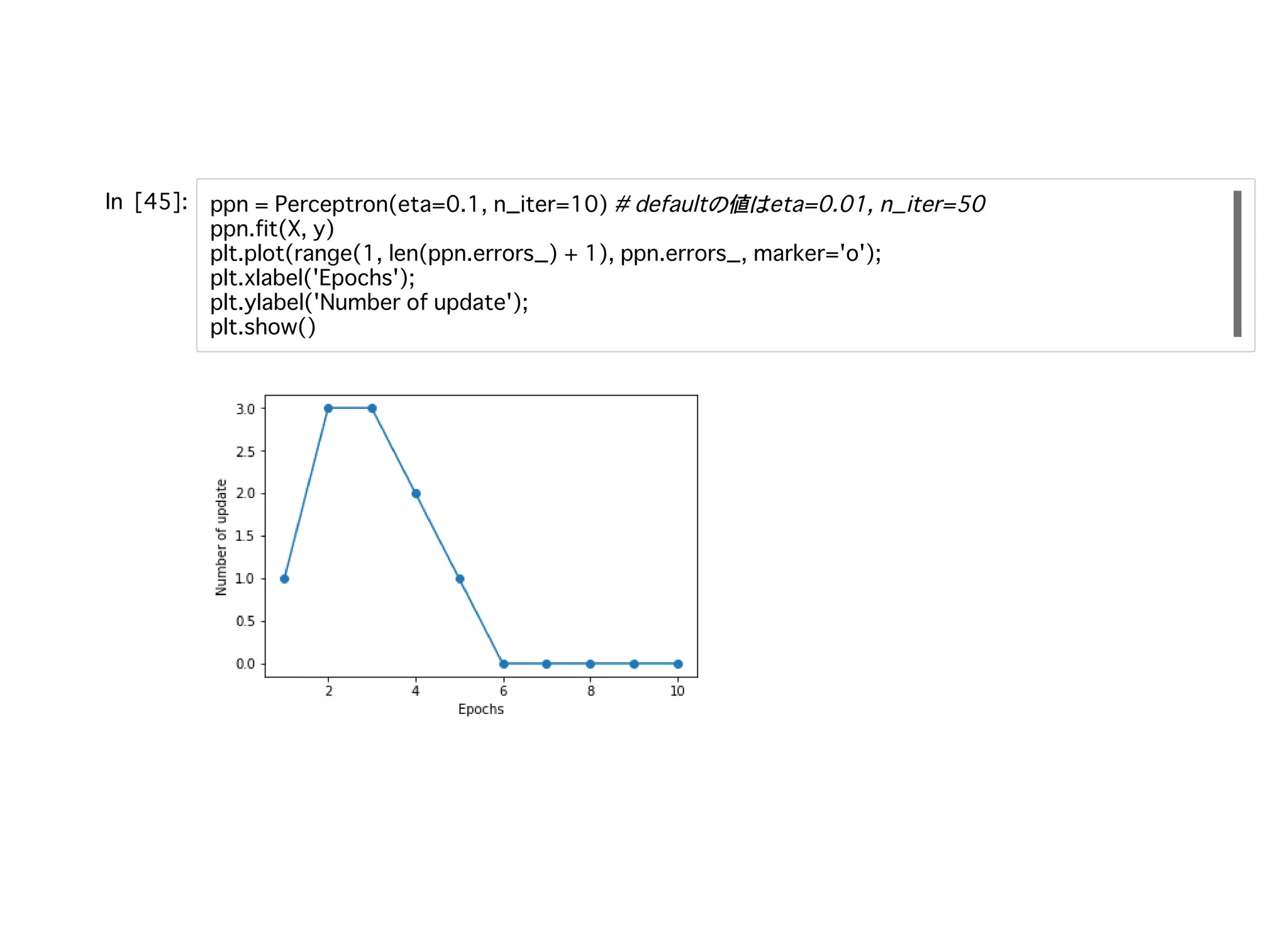
パーセプトロンモデルのトレーニングパーセプトロンモデルのトレーニング
30.
0 1 2
3 4 145 6.7 3.0 5.2 2.3 Iris-virginica 146 6.3 2.5 5.0 1.9 Iris-virginica 147 6.5 3.0 5.2 2.0 Iris-virginica 148 6.2 3.4 5.4 2.3 Iris-virginica 149 5.9 3.0 5.1 1.8 Iris-virginica
31.
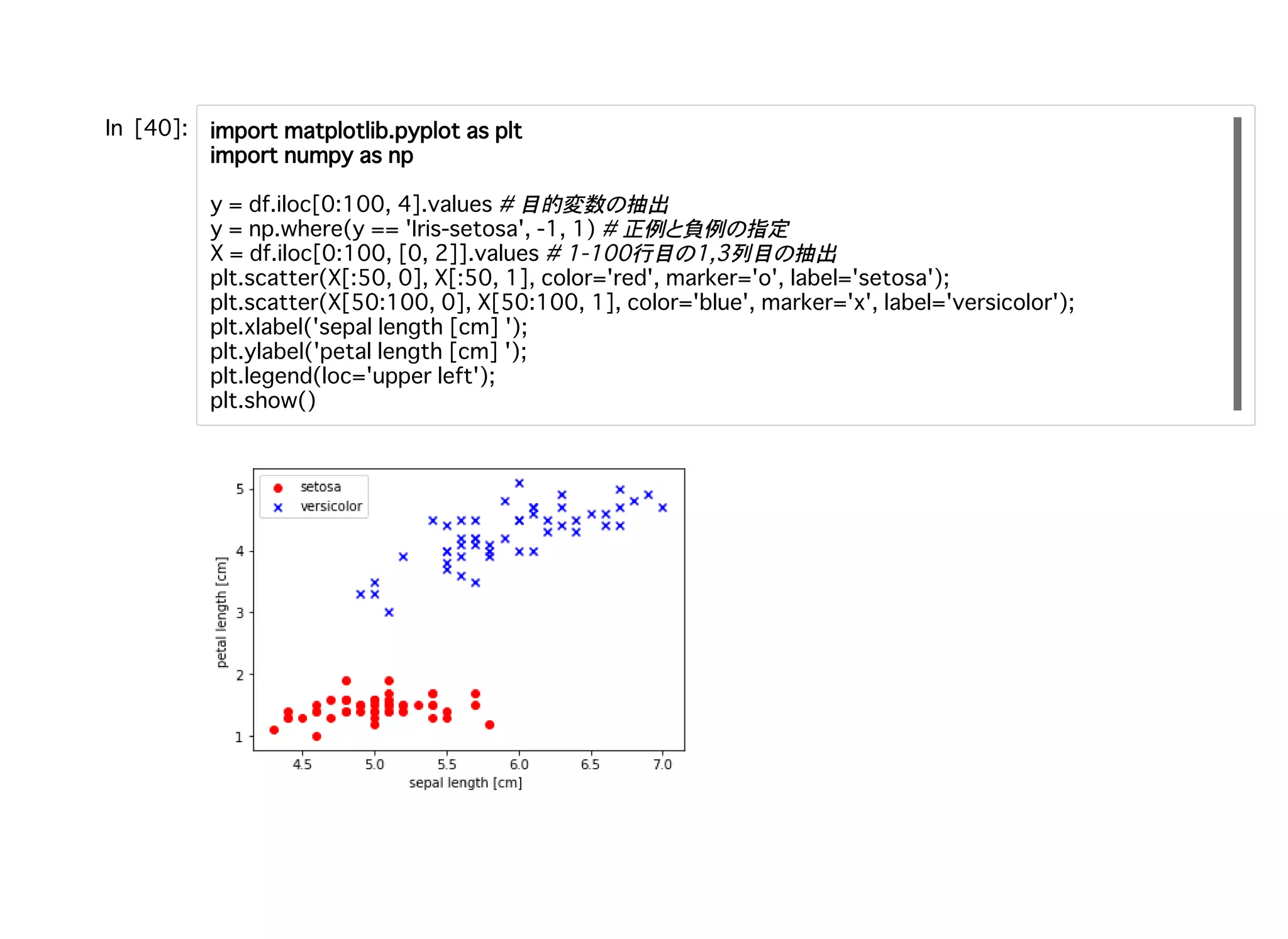
目的変数 抽出 正例 負例
指定 行目 列目 抽出
32.
値
33.
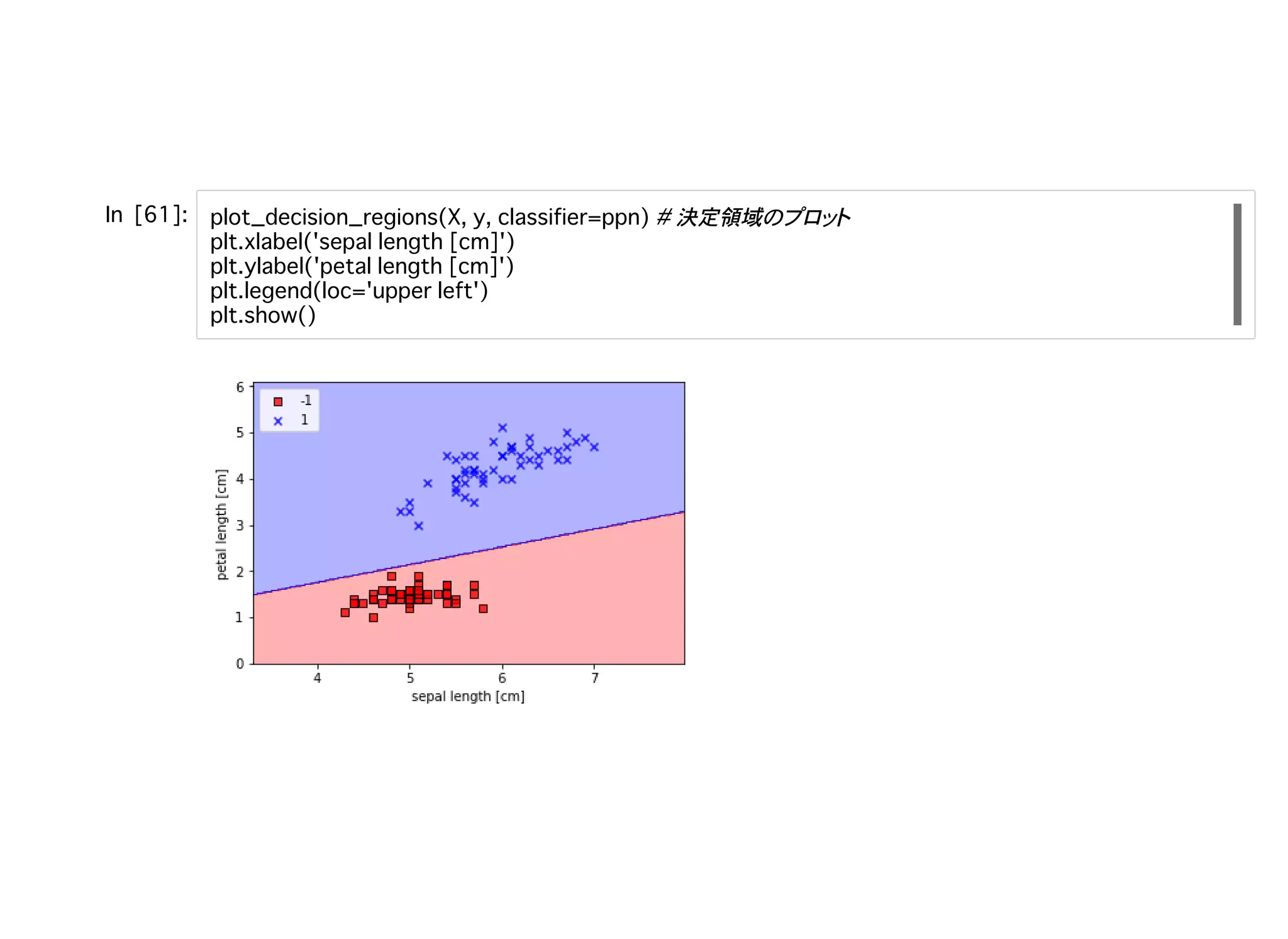
決定領域
34.
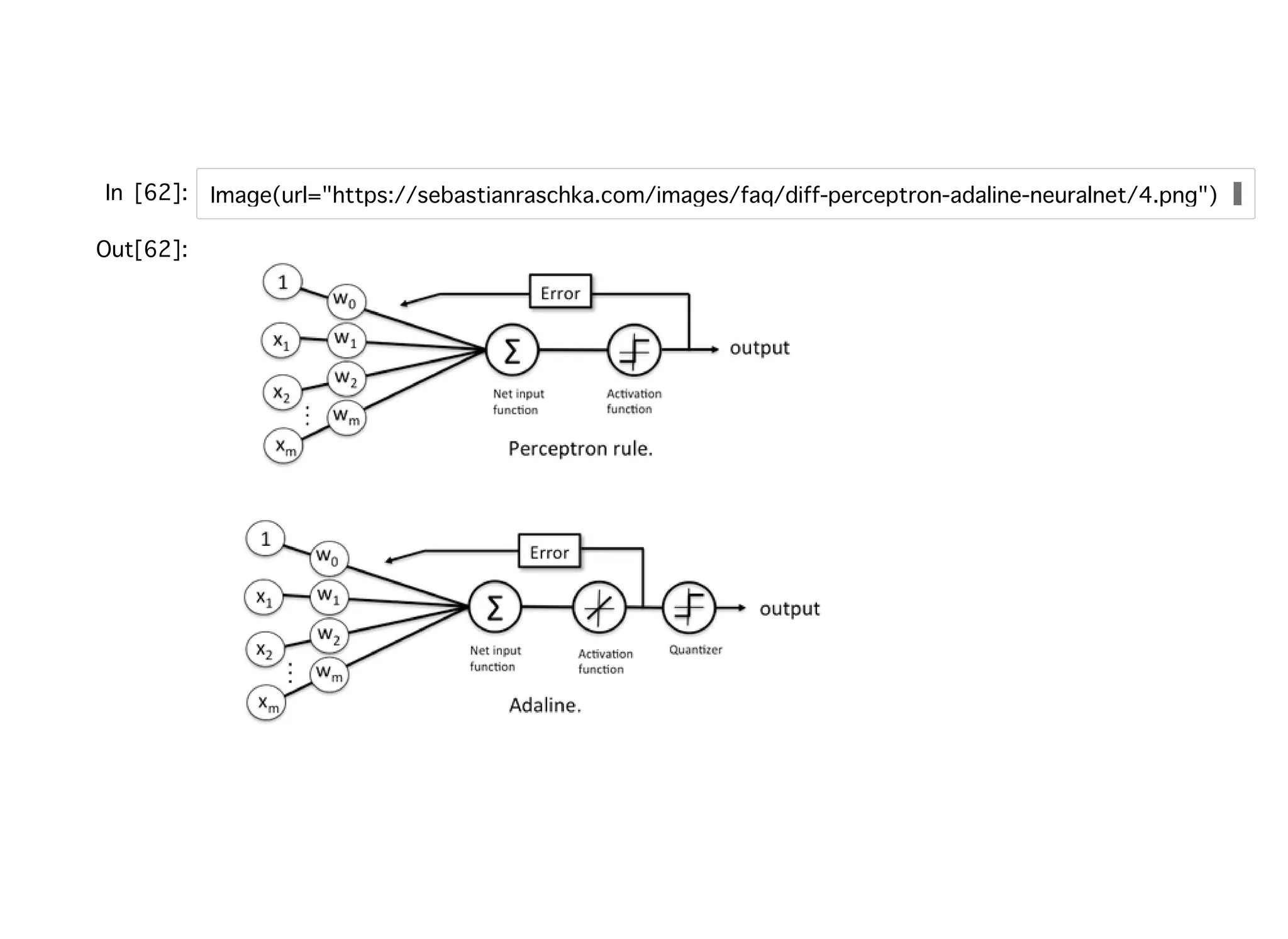
ADALINEADALINE 単層ニューラルネットワーク。 パーセプトロンの改良版。重みの更新⽅法がパーセプトロンと異なり、線形 活性化関数に基づいてなされる。 ただし最終的な予測にはパーセプトロンと同様に閾値関数を⽤いている。 パーセプトロンとの違いとして誤差の計算が線形活性化関数の出⼒値と真の ラベルとなっている点があげられる。 ADALINEの学習規則はWidrow-Hoff則と呼ばれる。 ⼆乗損失の最⼩化を最急降下法で解くことを指す。
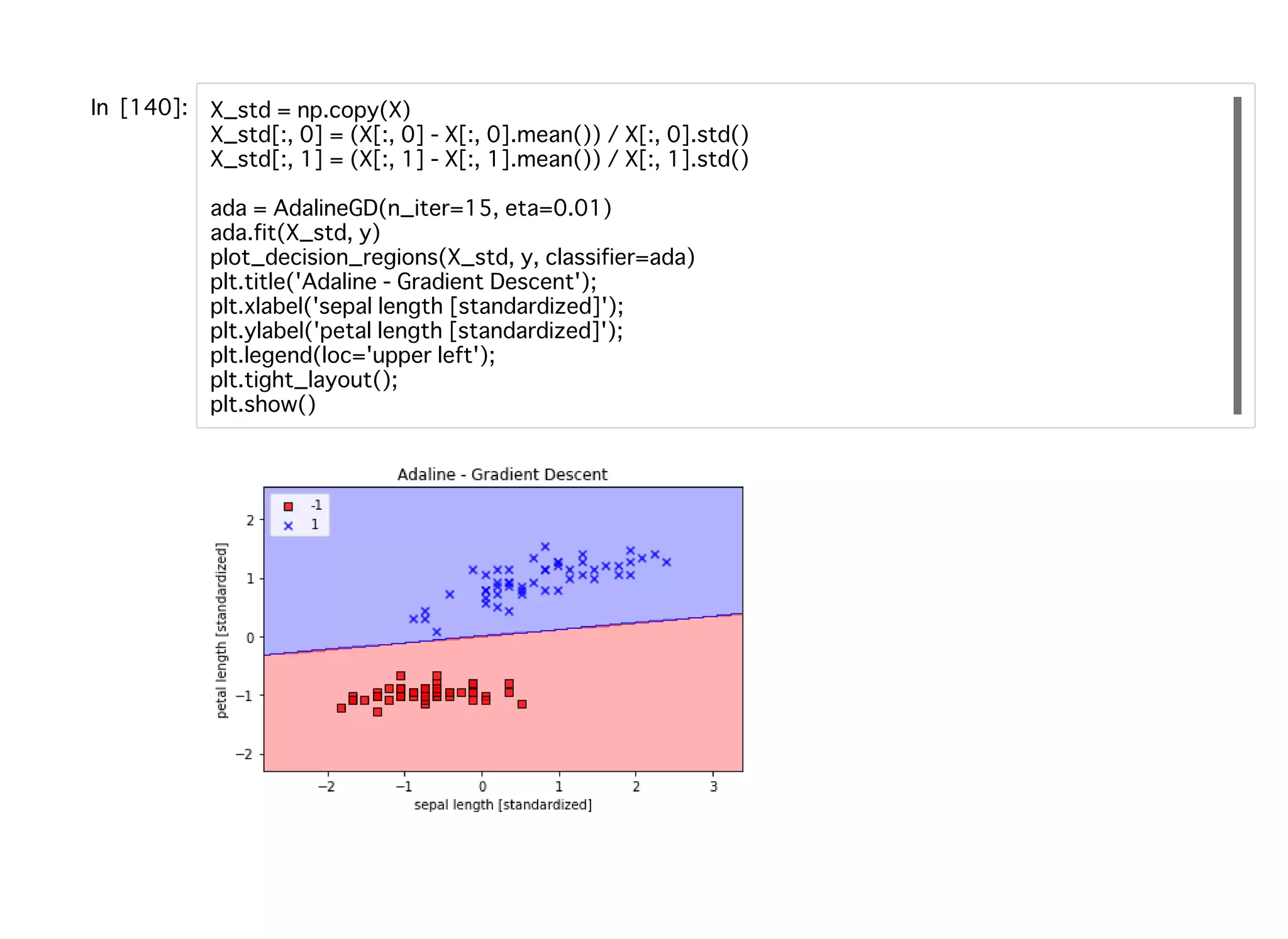
35.
36.
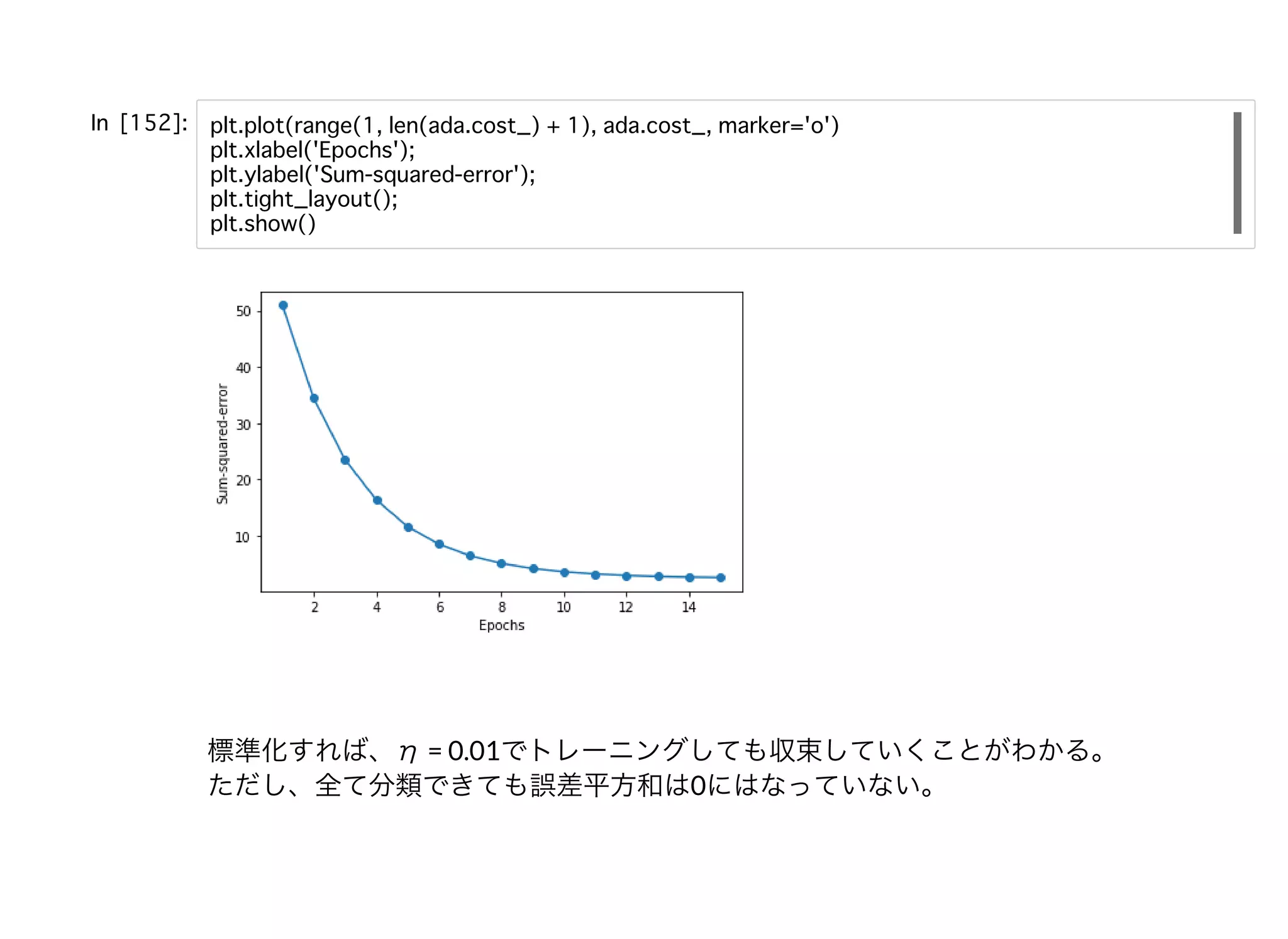
勾配降下法勾配降下法 機械学習の学習過程において⽬的関数を最適化するための⼿法の⼀つ。 今回のADALINEの場合は重みの学習に以下のコスト関数(誤差平⽅和)を⽤いる。 この関数は凸関数であり、微分可能であることから、勾配降下法を⽤いて最⼩化する ことができる。 この⽬的関数における重みの更新は で⾏われる。勾配の負値、つまり反対向きにパラメータを更新することに注⽬された い。∇J(w)の各要素については よって、更新式は以下のように表される。 J(W ) =
( − ϕ( ) 1 2 ∑ i y (i) z (i) ) 2 w := w + Δw Δw = −η∇J(w) = − ( − ϕ( )) ∂J ∂wj ∑ i y (i) z (i) x (i) j Δ = −η = η ( − ϕ( ))wj ∂J ∂wj ∑ i y (i) z (i) x (i) j
37.
Pythonでの実装Pythonでの実装
38.
39.
活性化関数 誤差 重 更新 更新式
従 別 重 更新 誤差二乗和 割 収束 判 断 使 内積 計算 線形活性化関数 今回 何 意味 持 次章以降 回帰 説明 比較 単位 関数
40.
41.
42.
スケーリングスケーリング 標準化 各特徴量の平均をずらして中⼼が0になるようにして、各特徴量の標 準偏差を1にする。 μ_jはサンプルの平均で、それをすべてのトレーニングサンプルから引き、 サンプルの標準偏差σ_jで割ることで標準化を⾏うことができる。 標準化が勾配降下法による学習に役⽴つ理由 探索空間が限られ、⼤局的最⼩値を⾒つけ出すためのステップ数が 少なくて済むため。 =x ′ j −xj μj σj
43.
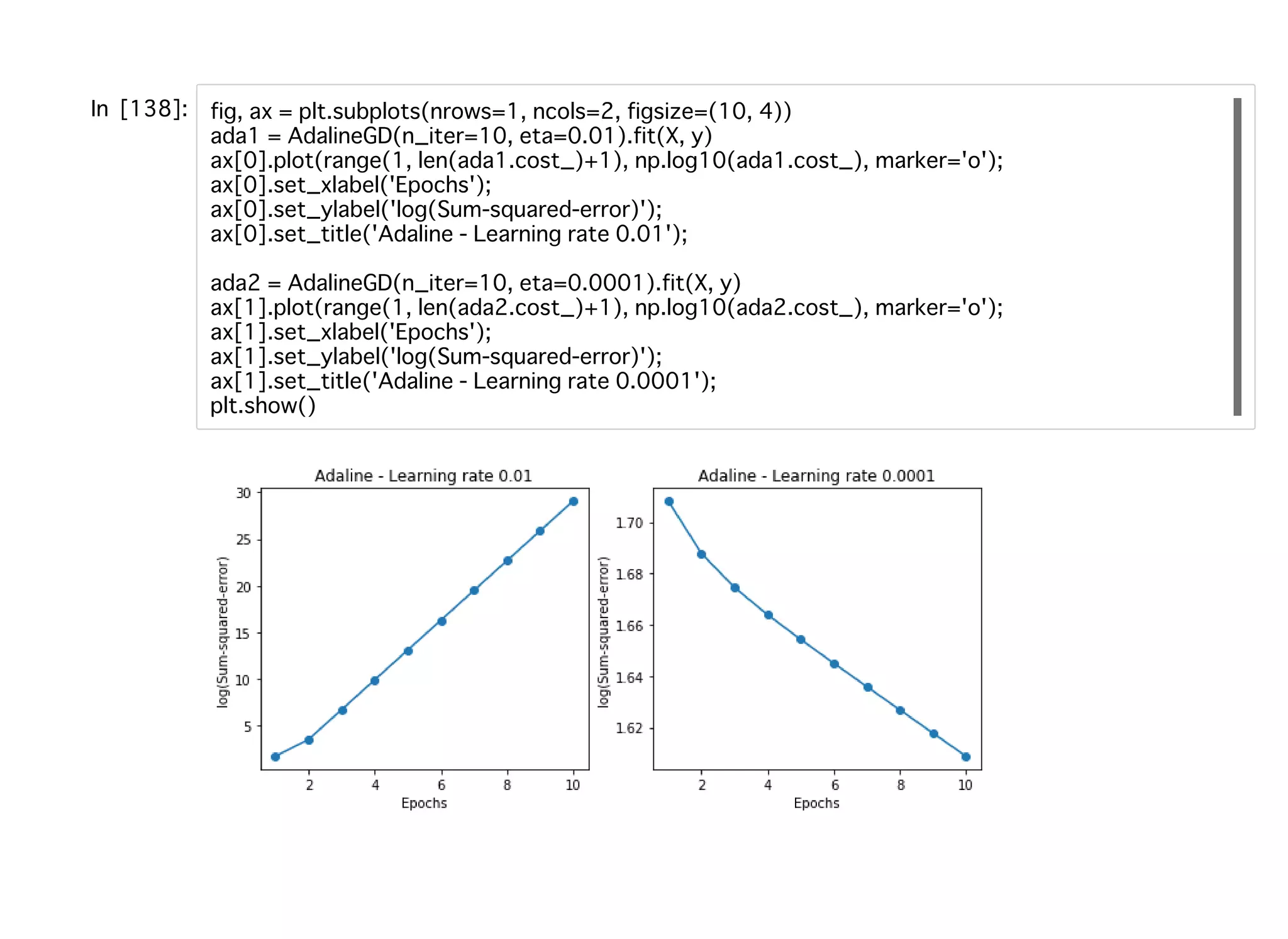
44.
標準化すれば、η= 0.01でトレーニングしても収束していくことがわかる。 ただし、全て分類できても誤差平⽅和は0にはなっていない。
45.
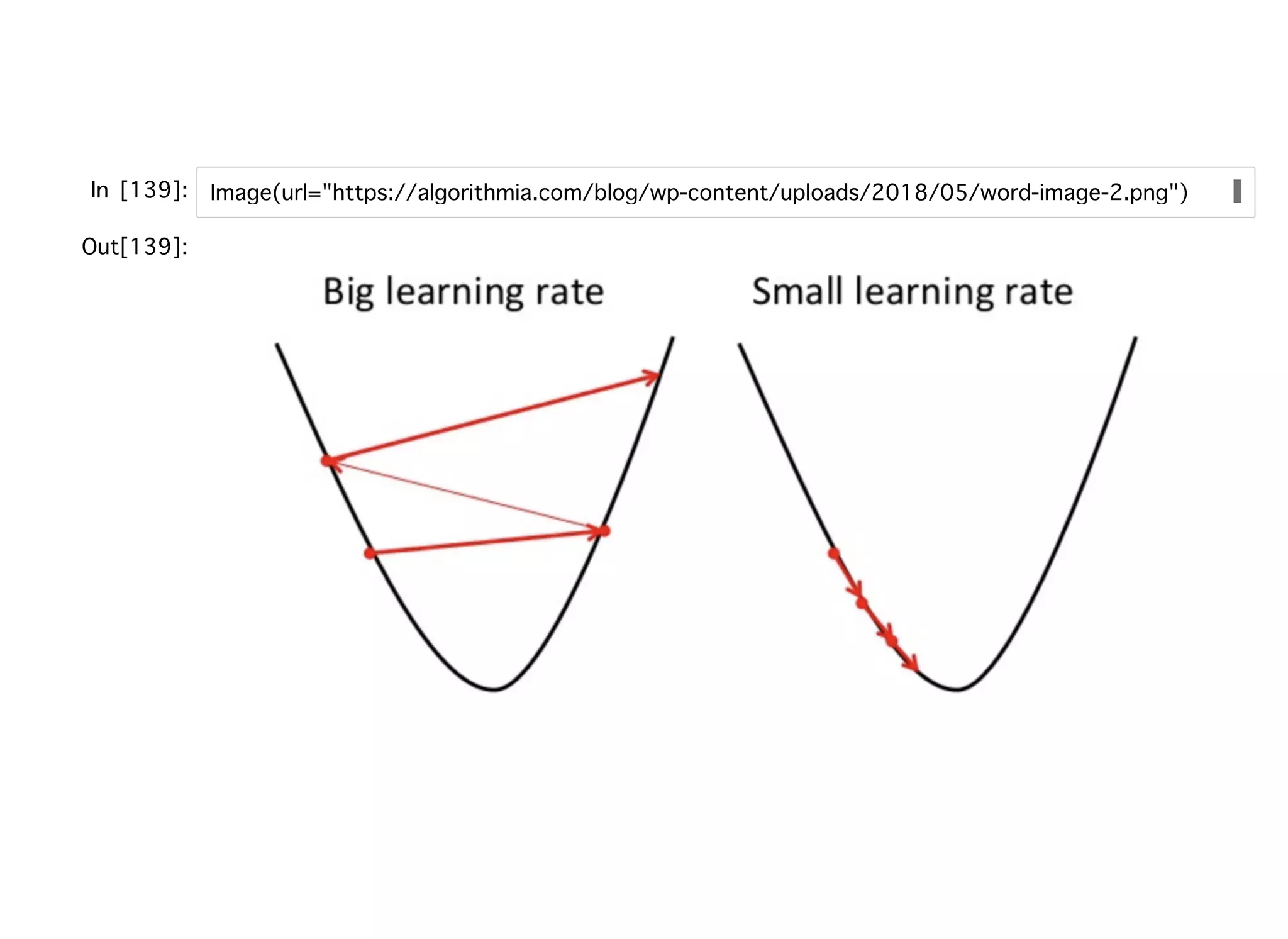
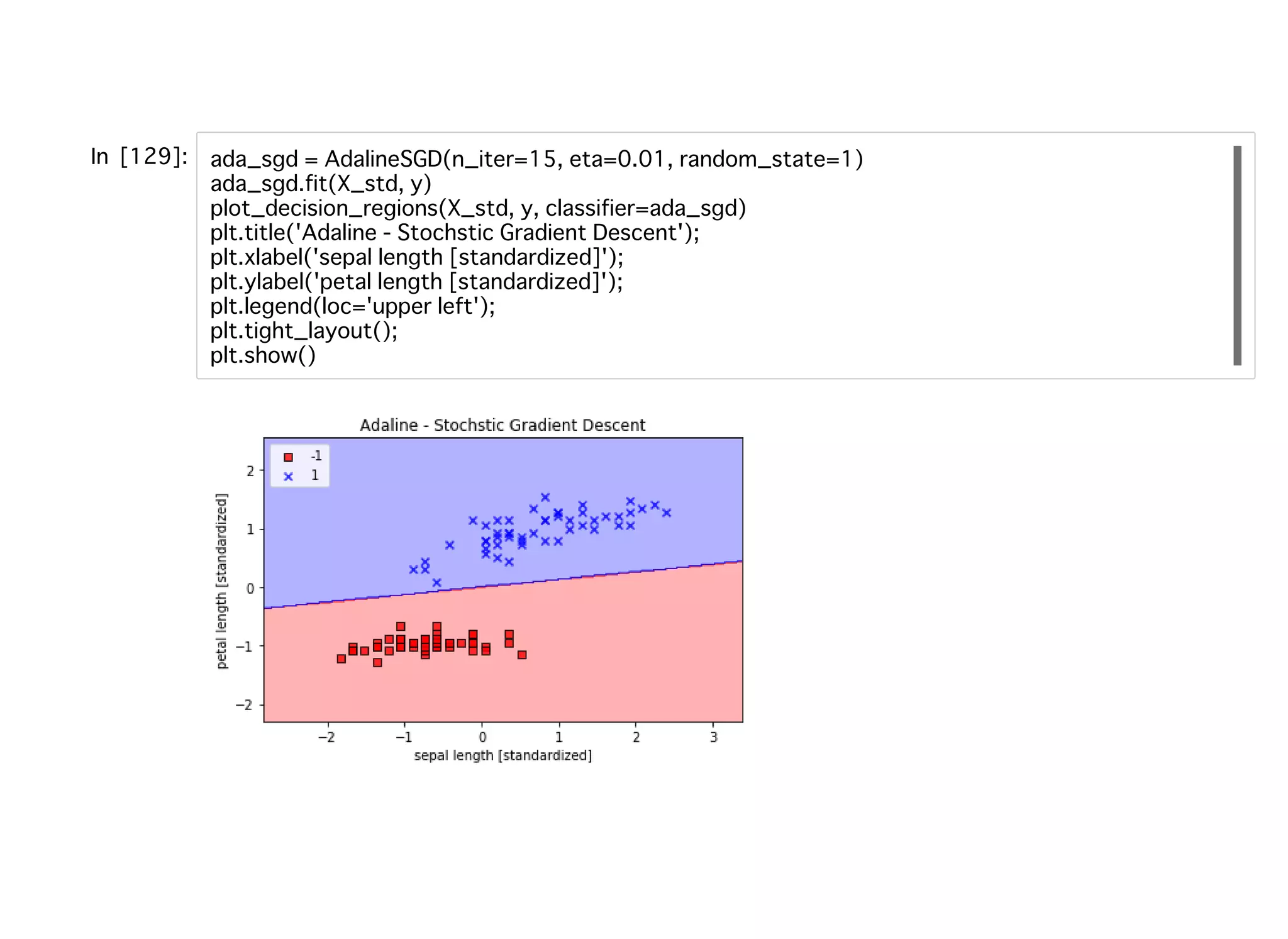
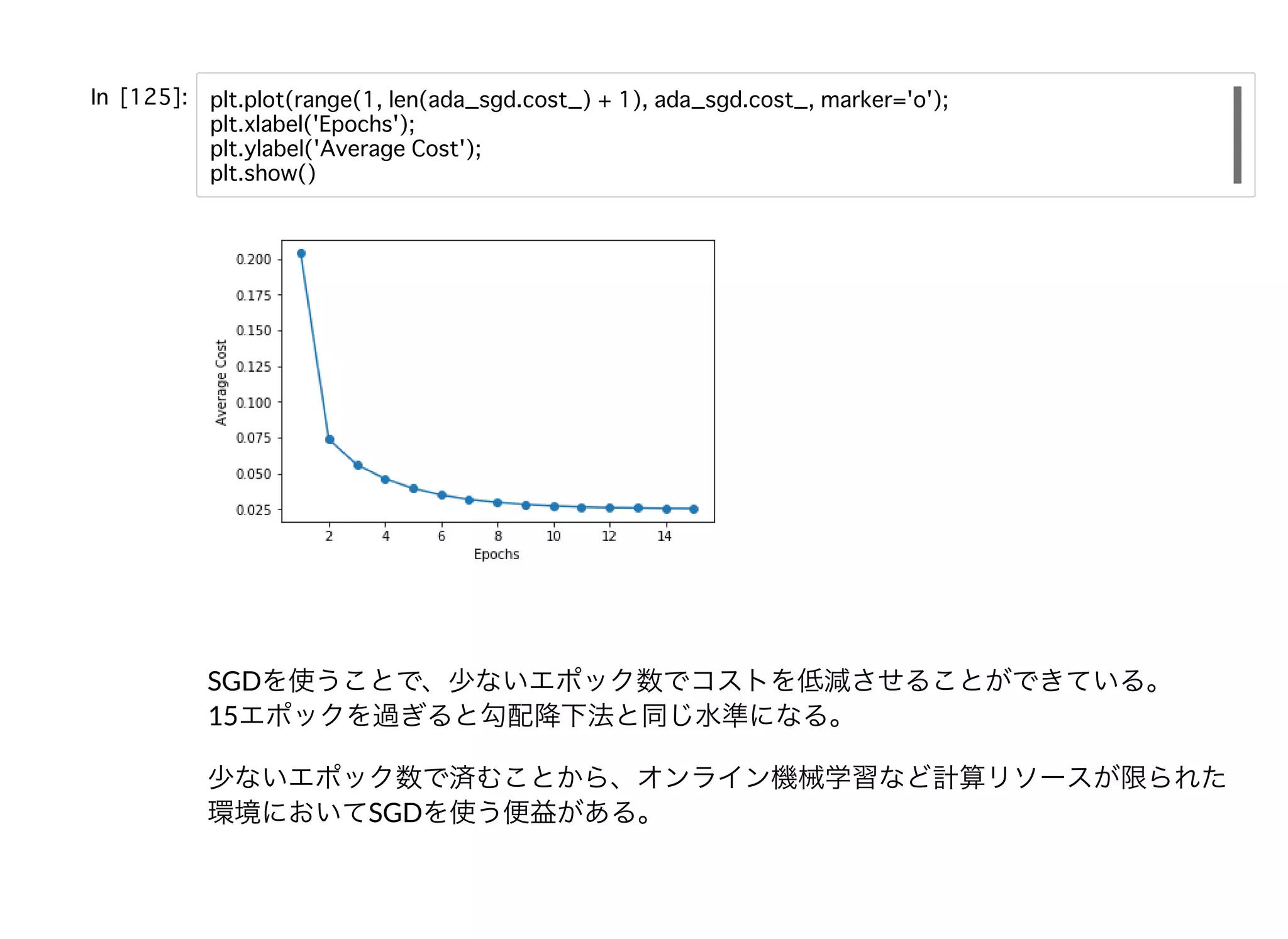
確率的勾配降下法確率的勾配降下法 勾配降下法の問題点 バッチ勾配降下法においては数百万のトレーニングサンプルがあっ たとして、そのすべてを同時に扱って重みの更新を⾏うため計算コ ストが⾼くついてしまう可能性がある。 勾配降下法を再掲する。 このsummationが問題となる。 そこで、確率的勾配降下法ではトレーニングサンプルごとに段階的に重みを更新す る。 トレーニングサンプルごとに重み更新するに際して、トレーニングサンプルをランダ ムな順序に並べ替えることが重要となる。偏りがある場合、段階的にやったとしても 重みベクトルが更新前と更新後で同じ値になる可能性がある。 Δ = −η
= η ( − ϕ( ))wj ∂J ∂wj ∑ i y (i) z (i) x (i) j η( − ϕ( ))y (i) z (i) x (i)
46.
Pythonでの実装Pythonでの実装
47.
重 初期化 空箱 関 空箱 一 更新式
従 更新 際 値 返 平均 計算 平均
48.
重 初期化 数 大
場合 繰 返 重 更新 個 場合 回 重 更新 並 替 重 初期化
49.
活性化関数 誤差 更新式 従 重
更新 別 更新 誤差二乗和 計算 割
50.
51.
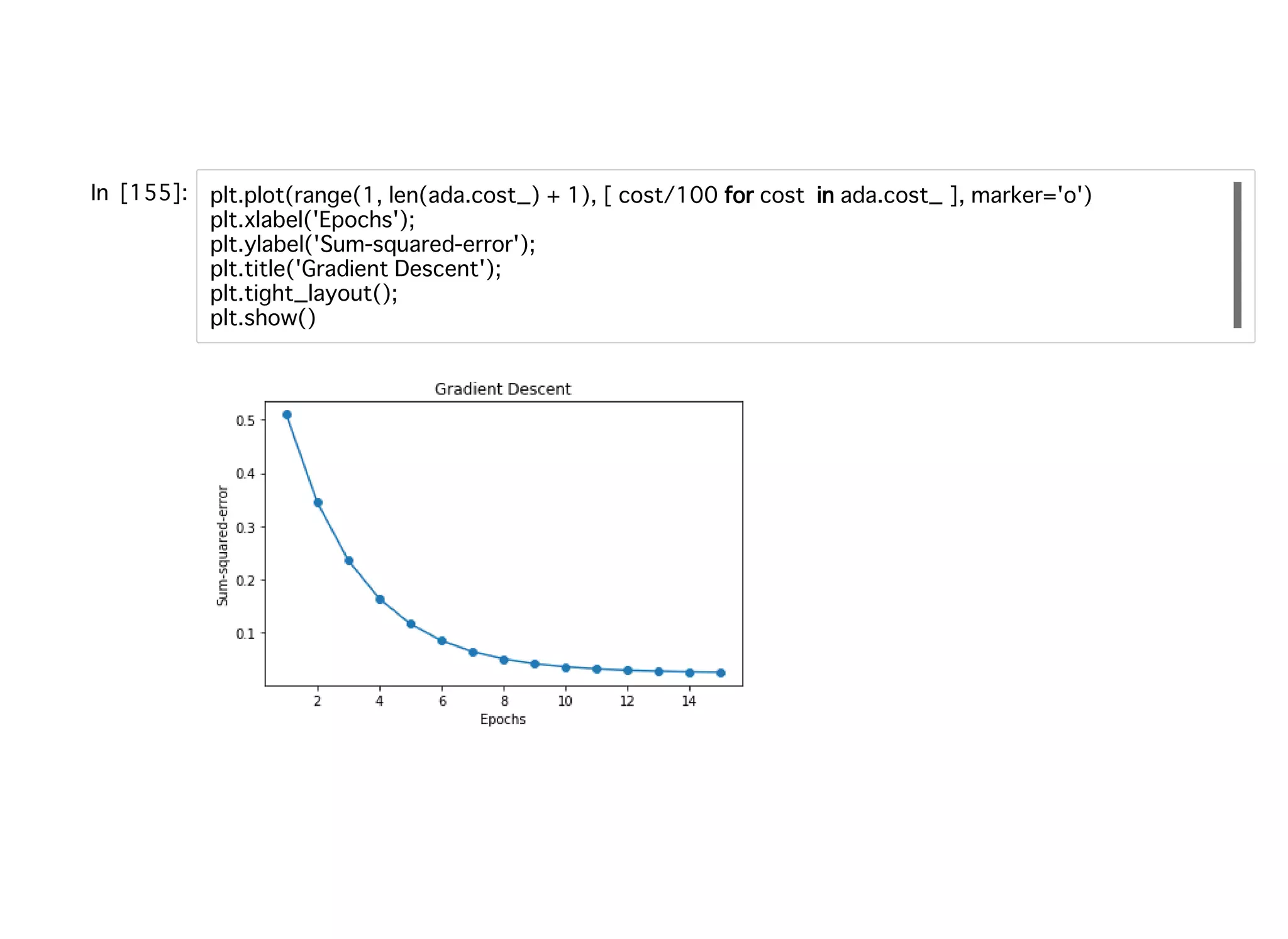
SGDを使うことで、少ないエポック数でコストを低減させることができている。 15エポックを過ぎると勾配降下法と同じ⽔準になる。 少ないエポック数で済むことから、オンライン機械学習など計算リソースが限られた 環境においてSGDを使う便益がある。
52.
53.
オンライン機械学習においてストリーミングデータを使って更新したい場合は以下の ように記述する。
54.
参考情報参考情報 http://ibisforest.org/index.php?Widrow- Hoff%E3%81%AE%E5%AD%A6%E7%BF%92%E8%A6%8F%E5%89%87 (http://ibisforest.org/index.php?Widrow- Hoff%E3%81%AE%E5%AD%A6%E7%BF%92%E8%A6%8F%E5%89%87) https://speakerdeck.com/kirikisinya/xin-zhe-renaiprmlmian-qiang-hui-at-ban- zang-men-number-3 (https://speakerdeck.com/kirikisinya/xin-zhe- renaiprmlmian-qiang-hui-at-ban-zang-men-number-3)
Download
![[DSO] Machine Learning Seminar Vol.1[DSO] Machine Learning Seminar Vol.1
2020-02-13
SKUE](https://image.slidesharecdn.com/chapter12slides-200211153032/75/DSO-Machine-Learning-Seminar-Vol-1-Chapter-1-and-2-1-2048.jpg)




































![[DSO] Machine Learning Seminar Vol.2 Chapter 3](https://cdn.slidesharecdn.com/ss_thumbnails/chapter3slides-200226170409-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DL輪読会]Deep Learning 第5章 機械学習の基礎](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning5-180601021956-thumbnail.jpg?width=640&height=640&fit=bounds)





![[輪講] 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/random-171231020415-thumbnail.jpg?width=640&height=640&fit=bounds)










![[第6回]データ分析ランチセッション - Camphrでモダンな自然言語処理](https://cdn.slidesharecdn.com/ss_thumbnails/dsolunchsession6-200219123751-thumbnail.jpg?width=640&height=640&fit=bounds)

![[丸ノ内アナリティクスバンビーノ#23]データドリブン施策によるサービス品質向上の取り組み](https://cdn.slidesharecdn.com/ss_thumbnails/marunouchianalytics202107-210729113930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSO] Machine Learning Seminar Vol.8 Chapter 9](https://cdn.slidesharecdn.com/ss_thumbnails/chapter9slides-200927083926-thumbnail.jpg?width=640&height=640&fit=bounds)
![[第11回]データ分析ランチセッション - モダンな機械学習データパイプラインKedroを触ってみる](https://cdn.slidesharecdn.com/ss_thumbnails/lunchsession11-200325093135-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Music×Analytics]プロの音に近づくための研究と練習](https://cdn.slidesharecdn.com/ss_thumbnails/muanalt-210227062125-thumbnail.jpg?width=640&height=640&fit=bounds)


![[第1回]データ分析ランチセッション ~ Qiita Advent Calendar2019から得た情報10選](https://cdn.slidesharecdn.com/ss_thumbnails/dsolunchsession1-200110120923-thumbnail.jpg?width=640&height=640&fit=bounds)
