Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Tyee Z
PDF, PPTX
7,732 views
はじぱた7章F5up
はじめてのパターン認識(7章後半) NNのバックプロパゲーション(BP)の学習則 BPの最近の傾向からディープラーニングのさわりまで
Read more
14
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 21
2
/ 21
3
/ 21
4
/ 21
Most read
5
/ 21
6
/ 21
Most read
7
/ 21
8
/ 21
Most read
9
/ 21
10
/ 21
11
/ 21
12
/ 21
13
/ 21
14
/ 21
15
/ 21
16
/ 21
17
/ 21
18
/ 21
19
/ 21
20
/ 21
21
/ 21
More Related Content
PPTX
パーセプトロン型学習規則
by
Shuhei Sowa
PDF
はじパタ6章前半
by
T T
PDF
はじめてのパターン認識 第6章 後半
by
Prunus 1350
PDF
はじめてのパターン認識 第5章 k最近傍法(k_nn法)
by
Motoya Wakiyama
PDF
はじめてのパターン認識 第8章 サポートベクトルマシン
by
Motoya Wakiyama
PDF
Prml4.4 ラプラス近似~ベイズロジスティック回帰
by
Yuki Matsubara
PDF
PRML輪読#3
by
matsuolab
PDF
PRML 6.1章 カーネル法と双対表現
by
hagino 3000
パーセプトロン型学習規則
by
Shuhei Sowa
はじパタ6章前半
by
T T
はじめてのパターン認識 第6章 後半
by
Prunus 1350
はじめてのパターン認識 第5章 k最近傍法(k_nn法)
by
Motoya Wakiyama
はじめてのパターン認識 第8章 サポートベクトルマシン
by
Motoya Wakiyama
Prml4.4 ラプラス近似~ベイズロジスティック回帰
by
Yuki Matsubara
PRML輪読#3
by
matsuolab
PRML 6.1章 カーネル法と双対表現
by
hagino 3000
What's hot
PDF
はじめてのパターン認識輪読会 10章後半
by
koba cky
PDF
パターン認識と機械学習 13章 系列データ
by
emonosuke
PDF
20130716 はじパタ3章前半 ベイズの識別規則
by
koba cky
PDF
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
PDF
はじパタ 10章 クラスタリング 前半
by
Katsushi Yamashita
PDF
PRML 2.4
by
kazunori sakai
PDF
PRML輪読#7
by
matsuolab
PDF
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PDF
PRML輪読#4
by
matsuolab
PDF
直交領域探索
by
okuraofvegetable
PDF
統計的学習の基礎6章前半 #カステラ本
by
Akifumi Eguchi
PDF
PRML輪読#5
by
matsuolab
PDF
はじめてのパターン認識 第1章
by
Prunus 1350
PDF
Prml 2.3
by
Yuuki Saitoh
PDF
PRML 5章 PP.227-PP.247
by
Tomoki Hayashi
PDF
PRML輪読#6
by
matsuolab
PDF
PRML上巻勉強会 at 東京大学 資料 第1章後半
by
Ohsawa Goodfellow
PDF
プログラミングコンテストでのデータ構造
by
Takuya Akiba
はじめてのパターン認識輪読会 10章後半
by
koba cky
パターン認識と機械学習 13章 系列データ
by
emonosuke
20130716 はじパタ3章前半 ベイズの識別規則
by
koba cky
PRMLの線形回帰モデル(線形基底関数モデル)
by
Yasunori Ozaki
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4
by
Takeshi Sakaki
はじパタ 10章 クラスタリング 前半
by
Katsushi Yamashita
PRML 2.4
by
kazunori sakai
PRML輪読#7
by
matsuolab
混合モデルとEMアルゴリズム(PRML第9章)
by
Takao Yamanaka
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PRML輪読#4
by
matsuolab
直交領域探索
by
okuraofvegetable
統計的学習の基礎6章前半 #カステラ本
by
Akifumi Eguchi
PRML輪読#5
by
matsuolab
はじめてのパターン認識 第1章
by
Prunus 1350
Prml 2.3
by
Yuuki Saitoh
PRML 5章 PP.227-PP.247
by
Tomoki Hayashi
PRML輪読#6
by
matsuolab
PRML上巻勉強会 at 東京大学 資料 第1章後半
by
Ohsawa Goodfellow
プログラミングコンテストでのデータ構造
by
Takuya Akiba
Viewers also liked
PPTX
ぼくの実装した最弱のディープラーニング
by
なおき きしだ
PPTX
単純パーセプトロン
by
T2C_
PDF
無限と計算可能性と対角線論法
by
Ryosuke Nakamura
PDF
20150803.山口大学集中講義
by
Hayaru SHOUNO
PDF
20150803.山口大学講演
by
Hayaru SHOUNO
PDF
TokyoNLP#5 パーセプトロンで楽しい仲間がぽぽぽぽ~ん
by
sleepy_yoshi
PDF
はじめてでもわかるベイズ分類器 -基礎からMahout実装まで-
by
Naoki Yanai
PDF
決定木学習
by
Mitsuo Shimohata
ぼくの実装した最弱のディープラーニング
by
なおき きしだ
単純パーセプトロン
by
T2C_
無限と計算可能性と対角線論法
by
Ryosuke Nakamura
20150803.山口大学集中講義
by
Hayaru SHOUNO
20150803.山口大学講演
by
Hayaru SHOUNO
TokyoNLP#5 パーセプトロンで楽しい仲間がぽぽぽぽ~ん
by
sleepy_yoshi
はじめてでもわかるベイズ分類器 -基礎からMahout実装まで-
by
Naoki Yanai
決定木学習
by
Mitsuo Shimohata
Similar to はじぱた7章F5up
PPTX
Back propagation
by
T2C_
PDF
機械学習と深層学習の数理
by
Ryo Nakamura
PDF
わかりやすいパターン認識_3章
by
weda654
PPTX
PRML Chapter 5
by
Masahito Ohue
PDF
PRML復々習レーン#10 7.1.3-7.1.5
by
sleepy_yoshi
PDF
Casual learning machine learning with_excel_no6
by
KazuhiroSato8
PDF
深層学習(講談社)のまとめ 第3章
by
okku apot
PDF
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
PDF
03_深層学習
by
CHIHIROGO
PDF
FOBOS
by
Hidekazu Oiwa
PDF
東京都市大学 データ解析入門 10 ニューラルネットワークと深層学習 1
by
hirokazutanaka
PPTX
深層学習による自然言語処理勉強会2章前半
by
Jiro Nishitoba
PDF
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
PPTX
W8PRML5.1-5.3
by
Masahito Ohue
PDF
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
PDF
PRML復々習レーン#7 前回までのあらすじ
by
sleepy_yoshi
PDF
Deeplearning3
by
ssuserf94232
PDF
ゼロから作るDeepLearning 5章 輪読
by
KCS Keio Computer Society
PDF
SGDによるDeepLearningの学習
by
Masashi (Jangsa) Kawaguchi
PDF
クラシックな機械学習の入門 7. オンライン学習
by
Hiroshi Nakagawa
Back propagation
by
T2C_
機械学習と深層学習の数理
by
Ryo Nakamura
わかりやすいパターン認識_3章
by
weda654
PRML Chapter 5
by
Masahito Ohue
PRML復々習レーン#10 7.1.3-7.1.5
by
sleepy_yoshi
Casual learning machine learning with_excel_no6
by
KazuhiroSato8
深層学習(講談社)のまとめ 第3章
by
okku apot
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
03_深層学習
by
CHIHIROGO
FOBOS
by
Hidekazu Oiwa
東京都市大学 データ解析入門 10 ニューラルネットワークと深層学習 1
by
hirokazutanaka
深層学習による自然言語処理勉強会2章前半
by
Jiro Nishitoba
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
W8PRML5.1-5.3
by
Masahito Ohue
20150310 第1回 ディープラーニング勉強会
by
哲朗 島田
PRML復々習レーン#7 前回までのあらすじ
by
sleepy_yoshi
Deeplearning3
by
ssuserf94232
ゼロから作るDeepLearning 5章 輪読
by
KCS Keio Computer Society
SGDによるDeepLearningの学習
by
Masashi (Jangsa) Kawaguchi
クラシックな機械学習の入門 7. オンライン学習
by
Hiroshi Nakagawa
はじぱた7章F5up
1.
第7章 パーセプトロン型学習規則 P96 @zaoriku0
2.
目次 7・1 パーセプトロン -パーセプトロンの学習規則 -学習の難しさの尺度 -パーセプトロンの収束定理 7・2 誤差逆伝搬法 -多層パーセプトロン -誤差逆伝搬法の学習規則 7・3
誤差逆伝搬法の学習特性 -初期値依存性 -隠れ素子の数 -過学習と正則化 -学習回路の尤度
3.
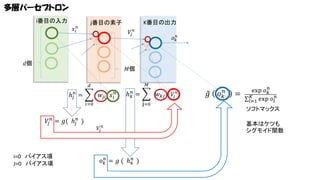
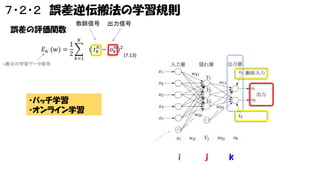
多層パーセプトロン i番目の入力 𝑥𝑖 𝑛 j番目の素子 K番目の出力 𝑉𝑗 𝑛 𝑑個 𝑜 𝑘𝑛 𝑀個 𝑀 𝑑 ℎ
𝑗𝑛 = 𝑤 𝑗𝑖 𝑥 𝑖 𝑛 𝑛 𝑘 ℎ = j=0 𝑖=0 𝑉𝑗 𝑛 = 𝑔( ℎ 𝑗𝑛 ) i=0 バイアス項 J=0 バイアス項 𝑤 𝑘𝑗 𝑉𝑗 𝑛 𝑜 𝑘𝑛 = 𝑔 ( ℎ 𝑘𝑛 ) 𝑉𝑗 𝑛 𝑔 𝑜 𝑘𝑛 = exp 𝑜 𝑘𝑛 𝑛 𝐾 𝑙=1 exp 𝑜 𝑙 ソフトマックス 基本はケツも シグモイド関数
4.
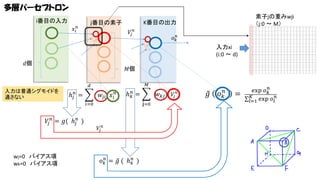
多層パーセプトロン i番目の入力 𝑥𝑖 𝑛 j番目の素子 素子jの重みwji (j:0 ~ M) K番目の出力 𝑉𝑗
𝑛 𝑜 𝑘𝑛 入力xi (i:0 ~ d) 𝑑個 𝑀個 𝑀 𝑑 入力は普通シグモイドを 通さない ℎ 𝑗𝑛 = 𝑤 𝑗𝑖 𝑥 𝑖 𝑛 𝑛 𝑘 ℎ = j=0 𝑖=0 𝑉𝑗 𝑛 = 𝑔( ℎ 𝑗𝑛 ) wj=0 バイアス項 wk=0 バイアス項 𝑤 𝑘𝑗 𝑉𝑗 𝑛 𝑜 𝑘𝑛 = 𝑔 ( ℎ 𝑘𝑛 ) 𝑉𝑗 𝑛 𝑔 𝑜 𝑘𝑛 = exp 𝑜 𝑘𝑛 𝑛 𝐾 𝑙=1 exp 𝑜 𝑙
5.
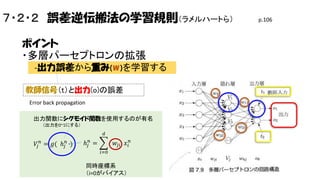
7・2・2 誤差逆伝搬法の学習規則(ラメルハートら) ポイント ・多層パーセプトロンの拡張 w を学習する -出力誤差から 教師信号(t)と出力(o)の誤差 Error
back propagation 出力関数にシグモイド関数を使用するのが有名 (出力を0~1にする) 𝑑 𝑉𝑗 𝑛 = 𝑔( ℎ 𝑗𝑛 ) ℎ 𝑗𝑛 = 𝑤 𝑗𝑖 𝑥 𝑖 𝑛 𝑖=0 同時座標系 (i=0がバイアス) p.106
6.
7・2・2 誤差逆伝搬法の学習規則 誤差の評価関数 1 𝐸 𝑛
(𝑤) = 2 教師信号 出力信号 𝐾 ( 𝑡 𝑘𝑛 − 𝑜 𝑘𝑛 )2 𝑘=1 (7.13) n番目の学習データ使用 ・バッチ学習 ・オンライン学習 i j k
7.
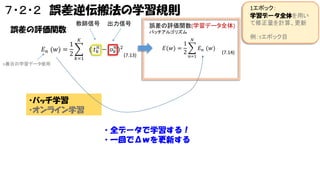
7・2・2 誤差逆伝搬法の学習規則 誤差の評価関数 1 𝐸 𝑛
(𝑤) = 2 教師信号 出力信号 誤差の評価関数(学習データ全体) バッチアルゴリズム 𝐾 ( 𝑘=1 𝑡 𝑘𝑛 − 𝑜 𝑘𝑛 )2 𝐸(𝑤) = (7.13) 1 2 例:τエポック目 𝑁 𝐸 𝑛 (𝑤) 𝑛=1 n番目の学習データ使用 ・バッチ学習 ・オンライン学習 ・全データで学習する! ・一回でΔwを更新する 1エポック: 学習データ全体を用い て修正量を計算、更新 (7.14)
8.
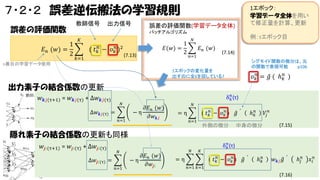
7・2・2 誤差逆伝搬法の学習規則 誤差の評価関数 1 𝐸 𝑛
(𝑤) = 2 教師信号 出力信号 1エポック: 学習データ全体を用い て修正量を計算、更新 誤差の評価関数(学習データ全体) バッチアルゴリズム 𝐾 ( 𝑡 𝑘𝑛 − 𝑜 𝑘𝑛 )2 𝑘=1 𝐸(𝑤) = (7.13) 1 2 例:τエポック目 𝑁 𝐸 𝑛 (𝑤) 𝑛=1 (7.14) シグモイド関数の微分は、元 の関数で表現可能 p106 n番目の学習データ使用 1エポックの変化量を 出すのに全Eを回している? 𝑜 𝑘𝑛 = 𝑔 ( ℎ 𝑘𝑛 ) 出力素子の結合係数の更新 𝑤 𝒌𝑗(τ+1) = 𝑤 𝒌𝑗(τ) + Δ𝑤 𝒌𝑗(τ) 𝑁 Δ𝑤 𝒌𝑗(τ) = 𝑛=1 𝑛 δ 𝑘 (τ) 𝜕𝐸 𝑛 (𝑤) −η 𝜕𝑤 𝒌𝑗 𝑁 𝑉𝑗 𝑛 ( 𝑡 𝑘𝑛 − 𝑜 𝑘𝑛 ) 𝑛=1 𝑔 外側の微分 =η ℎ 𝑘𝑛 中身の微分 (7.15) 隠れ素子の結合係数の更新も同様 𝑤 𝒋𝑖(τ+1) = 𝑤 𝒋𝑖 (τ) + Δ𝑤 𝒋𝑖(τ) 𝑁 Δ𝑤 𝒋𝑖(τ) = −η 𝑛=1 𝜕𝐸 𝑛 (𝑤) 𝜕𝑤 𝒋𝑖 𝑁 𝐾 𝑛 δ 𝑘 (τ) ( 𝑡 𝑘𝑛 − 𝑜 𝑘𝑛 ) =η 𝑔 ℎ 𝑘𝑛 𝑤 𝒌𝑗 𝑔 𝑛=1 𝑘=1 (7.16) ℎ 𝑗𝑛 𝑥 𝑖𝑛
9.
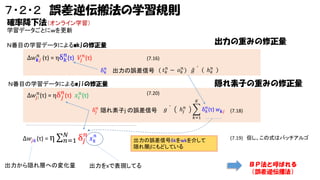
7・2・2 誤差逆伝搬法の学習規則 確率降下法(SGD?)(オンライン学習) 最急降下法、サンプルをランダムに取って学習 学習データごとにwを逐次更新 出力の重みの修正量 N番目の学習データによるwkjの修正量 𝑛 𝑛 Δ𝑤 𝒌𝑗
(τ) = ηδ 𝑘 (τ) 𝑉𝑗 𝑛 (τ) (7.16) 𝑛 δ 𝑘 出力の誤差信号 ( 𝑡 𝑘𝑛 − 𝑜 𝑘𝑛 ) N番目の学習データによるwjiの修正量 Δ𝑤 𝑗 𝑛𝑖 (τ) = ηδ 𝑗𝑛 (τ) 𝑥 𝑖 𝑛 (τ) ℎ 𝑘𝑛 𝑔 隠れ素子の重みの修正量 (7.20) δ 𝑗𝑛 隠れ素子j の誤差信号 𝐾 𝑔 ℎ 𝑗𝑛 𝑛 δ 𝑘 (τ) 𝑤 𝒌𝑗 (7.18) 𝑘=1 -数十~100程度の訓練データから勾配求めることが多いらしい -バッチとオンラインの性能差? バッチはメモリ食う! マルチコアのマルチスレッドで分散して計算するとよい。 ミニバッチ法:SGD (AI学会誌vol.28)
10.
7・2・2 誤差逆伝搬法の学習規則 確率降下法(オンライン学習) 学習データごとにwを更新 出力の重みの修正量 N番目の学習データによるwkjの修正量 𝑛 𝑛 Δ𝑤 𝒌𝑗
(τ) = ηδ 𝑘 (τ) 𝑉𝑗 𝑛 (τ) (7.16) 𝑛 δ 𝑘 出力の誤差信号 ( 𝑡 𝑘𝑛 − 𝑜 𝑘𝑛 ) ℎ 𝑘𝑛 𝑔 隠れ素子の重みの修正量 N番目の学習データによるwjiの修正量 Δ𝑤 𝑗 𝑛𝑖 (τ) = ηδ 𝑗𝑛 (τ) 𝑥 𝑖 𝑛 (τ) (7.20) 𝐾 δ 𝑗𝑛 隠れ素子j の誤差信号 𝑔 ℎ 𝑗𝑛 𝑛 δ 𝑘 (τ) 𝑤 𝒌𝑗 (7.18) 𝑘=1 Δ𝑤 𝑗𝑘 (τ) = η 𝑁 δ 𝑗𝑛 𝑥 𝑘𝑛 𝑛=1 出力から隠れ層への変化量 出力の誤差信号δkをwkを介して 隠れ層jにもどしている 出力をxで表現してる (7.19) 但し、この式はバッチアルゴ BP法と呼ばれる (誤差逆伝播法)
11.
実行例7.1 手書き数字データの学習 p57、p107下 入力:16x16+1(256+1) 隠れ層:10+1 出力:10個 学習データ:各数字650個 テストデータ:他の650個 平均誤識別率:3.1% 5の誤り:44個 入力:8x8x8+1(512+1) 隠れ層:12+1(最適) 出力:10個 学習データ:各数字650個 テストデータ:他の650個 認識率:99%超え 5の誤り:6個
12.
7・3 誤差逆伝搬法の学習特性(学習) 7.3.1 初期依存性 どうつくればいいかの研究もある p.108 ・最適解に行くかどうかは、wの初期値で決まる ・最急降下法、共役勾配法 よくないケース 最急降下法 共役勾配法 http://d.hatena.ne.jp/Zellij/20120712/p1
13.
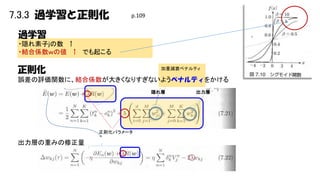
7.3.3 過学習と正則化 p.109 過学習 ・隠れ素子jの数 ↑ ・結合係数wの値
↑ でも起こる 正則化 加重減衰ペナルティ 誤差の評価関数に、結合係数が大きくなりすぎないようペナルティをかける 隠れ層 正則化パラメータ 出力層の重みの修正量 出力層
14.
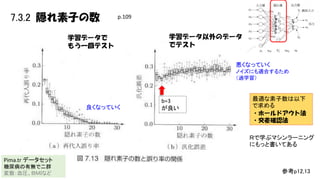
7.3.2 隠れ素子の数 p.109 学習データで もう一回テスト 学習データ以外のデータ でテスト 悪くなっていく ノイズにも適合するため (過学習) 良くなっていく b=3 が良い 最適な素子数は以下 で求める ・ホールドアウト法 ・交差確認法 Rで学ぶマシンラーニング にもっと書いてある Pima.tr データセット 糖尿病の有無で二群 変数:血圧、BMIなど 参考p12,13
15.
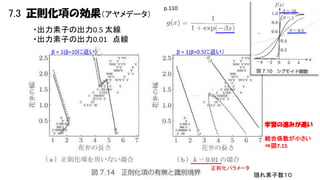
7.3 正則化項の効果(アヤメデータ) p.110 ・出力素子の出力0.5 太線 ・出力素子の出力0.01
点線 β = 1(β=10に近い) β = 1(β=0.5に近い) 学習の進みが遅い 結合係数が小さい ⇒図7.15 正則化パラメータ 隠れ素子数10
16.
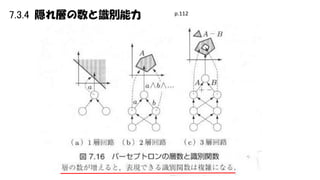
7.3.4 隠れ層の数と識別能力 p.112
17.
7.3.5 学習回路の尤度 PRML(上)p236 参考 ・尤度関数を誤差関数として使用するとよい! 出力の活性化関数と誤差関数 ⇒
解くべき問題の型で選択 活性化関数(出力関数) g() 誤差関数 E() 回帰問題 線形出力関数 二乗和誤差 2クラス分類問題 (多数の独立な) ロジスティックシグモイド関数 二乗和誤差 ソフトマックス関数(2クラス) 交差エントロピー誤差関数 多クラス分類問題 ソフトマックス関数 多クラス交差エントロピー誤差関数 クラス分類問題では、交差エントロピー誤差関数を使うほうが、 訓練が早く、同時に凡化能力が高まる。Simard et al, 2003 PLML(上) p235
18.
7.3.5 学習回路の尤度 参考 p.52,
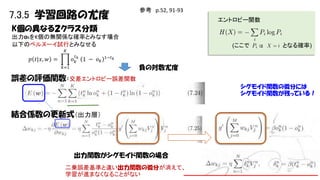
91-93 エントロピー関数 K個の異なる2クラス分類 出力okをK個の無関係な確率とみなす場合 以下のベルヌーイ試行とみなせる (ここで 𝐾 𝑡 𝑜𝑘𝑘 1 − 𝑜𝑘 𝑝 𝑡|𝑥, 𝑤 = は となる確率) 1−𝑡 𝑘 負の対数尤度 𝑘=1 誤差の評価関数:交差エントロピー誤差関数 シグモイド関数の微分には シグモイド関数が残っている! 結合係数の更新式(出力層) 出力関数がシグモイド関数の場合 二乗誤差基準と違い出力関数の微分が消えて、 学習が進まなくなることがない
19.
参考 p.52, 91-93 7.3.5
学習回路の尤度 K個の排他的な1つに割り当てる場合 (ソフトマックス関数) 出力を 𝑔 (ok) = p( tk = 1 |x)のようにする場合 𝐾 𝑝 𝑡 𝑘 = 1|𝑥 𝑡 𝑜𝑘𝑘 𝑝 𝑡 𝑘 = 1|𝑥, 𝑤 = 𝑘=1 負の対数尤度 誤差の評価関数 𝑁 𝐸 𝐾 𝑡 𝑘𝑛 log 𝑜 𝑘𝑛 𝑤 =− 𝑛=1 𝑘=1 結合係数の更新式 p93 最尤推定法 E(w)を各wで微分(=0)をして、各wを出す。 ?
20.
まとめ 特徴 出力誤差から w を学習する ・出力関数 g() ・誤差の評価関数
E() ・更新式 Δw 問題点(本にないものあり) ・局所最適化、過学習 (わりと改善している感) ->正則化 ->DropOut[Hinton 12]学習時:Nを半数消す、推論時:Nの出力2/1、複数モデルの平均 ->Maxout[Good fellow 13]複数の出力関数の内最大値を取るものを選ぶ、高性能 ・誤差の伝播が十分でない(層が深いとき) ・遅い →交差エントロピーの方が速く、凡化性能が良い →ReLU[Nair 10]h(x)=log(1+e(x)) =~ max(0,x)、 結果もよい →Maxoutも速い ・構造の形はどれくらいがいいのか(層数とかピラミッドとか) →技はあるっぽい ・生理モデルではない
21.
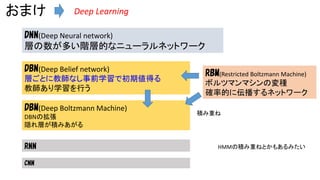
おまけ Deep Learning DNN(Deep Neural
network) 層の数が多い階層的なニューラルネットワーク DBN(Deep Belief network) 層ごとに教師なし事前学習で初期値得る 教師あり学習を行う DBM(Deep Boltzmann Machine) DBNの拡張 隠れ層が積みあがる RNN CNN RBM(Restricted Boltzmann Machine) ボルツマンマシンの変種 確率的に伝播するネットワーク 積み重ね HMMの積み重ねとかもあるみたい
Download









![まとめ
特徴
出力誤差から
w を学習する
・出力関数 g()
・誤差の評価関数 E()
・更新式 Δw
問題点(本にないものあり)
・局所最適化、過学習 (わりと改善している感)
->正則化
->DropOut[Hinton 12]学習時:Nを半数消す、推論時:Nの出力2/1、複数モデルの平均
->Maxout[Good fellow 13]複数の出力関数の内最大値を取るものを選ぶ、高性能
・誤差の伝播が十分でない(層が深いとき)
・遅い →交差エントロピーの方が速く、凡化性能が良い
→ReLU[Nair 10]h(x)=log(1+e(x)) =~ max(0,x)、 結果もよい →Maxoutも速い
・構造の形はどれくらいがいいのか(層数とかピラミッドとか) →技はあるっぽい
・生理モデルではない](https://image.slidesharecdn.com/f5up-131028224307-phpapp02/85/F5up-20-320.jpg)